
Update (29/8/2023): Made an update of the format of the article because Matthieu Shakespeare Sola found that my chatGPT assistant/editor was too wordy, but the content is the same
In my recent work on recommender systems, I have been looking at costs and using deep learning methods. I saw a common issue in many articles: they talk a lot about system design and testing, but often ignore important parts like fallback strategies and serving rules. But these parts are key for actually using recommender systems in the real world. This article will talk about why fallbacks and serving rules are important, and give practical tips for making recommender systems that work well in both theory and practice.
Contextualizing Data and System Objectives
In my free time, I’ve been working on making data scrapers, which is something I’ve done before. Recently, I started making a scraper to collect data from a well-known movie review site. This data is very useful for the article I am writing. It’s also much simpler than my last data source, RecSys Sens Critique, which has a wide variety of entertainment for a French audience, including video games, movies, TV shows, and books.
Using this collected data, I am building a ‘Netflix-like’ test environment to make a movie recommendation system. The main goal is to predict the best next movie for users. The final goal of the application is to show users the top 10 movie recommendations, either by email or on a website. To give you an idea, imagine a recommendations section like the one shown below:
Unveiling the Mechanics of Recommendation Models
In the complex world of recommendation systems, a simple machine learning model does not reflect their true complexity. The process includes not just making algorithmic predictions, but also combining different strategies to create a smooth user experience.

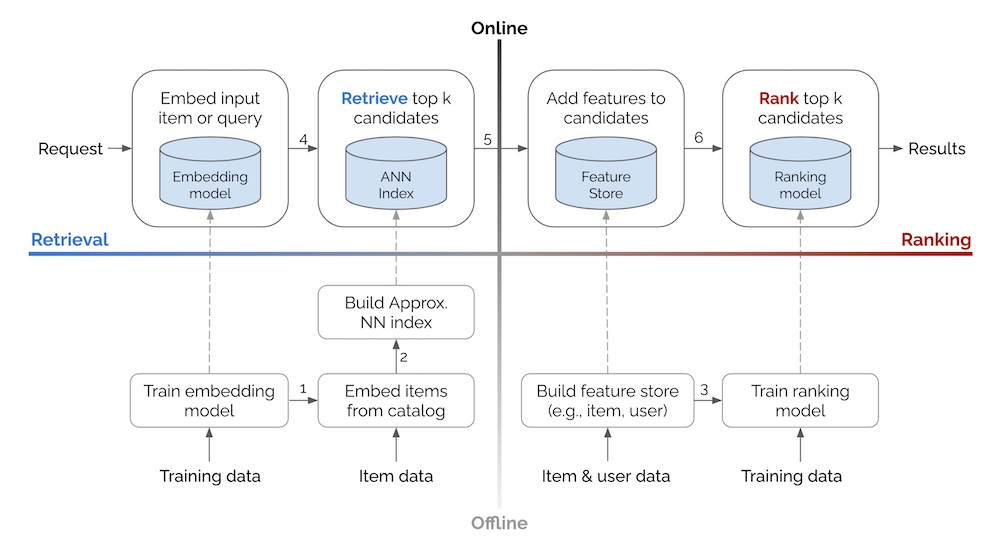
Think about two common design models—Retrieval & Rank (RR) and Retrieval, Filtering, Scoring, and Ordering (RFSO). In the RR model, the main focus is on finding potential candidates and ranking them based on what the user likes.
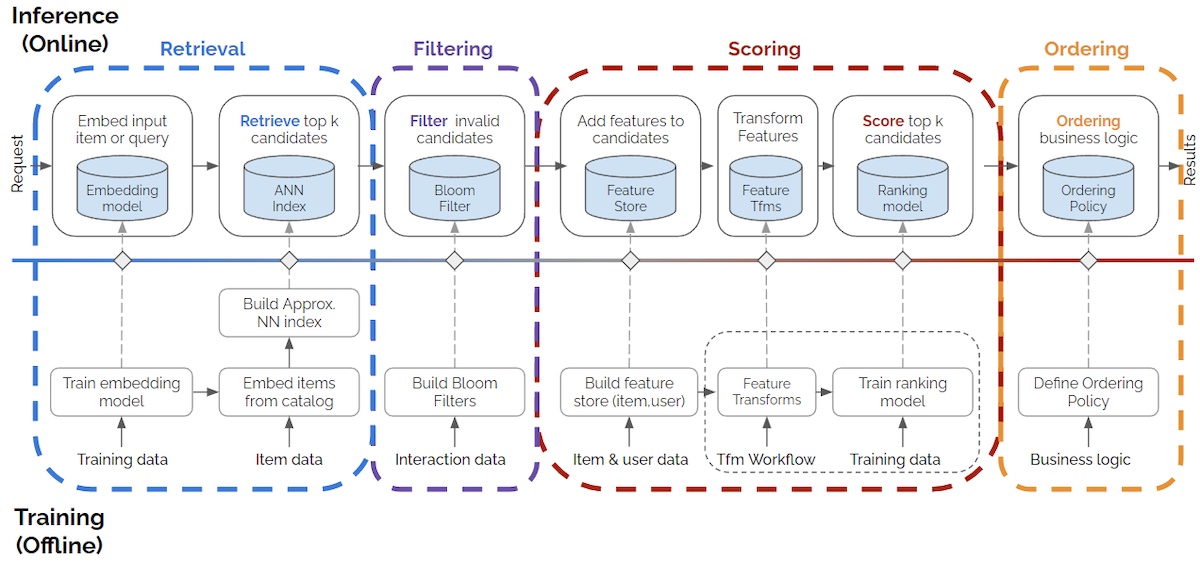
On the other hand, the RFSO approach is more complicated. It involves finding potential items, filtering out the ones that are not relevant, giving scores, and carefully organizing recommendations to meet different business needs.
I
If you want to read more about that, there is a great article by Eugene Yan on the topic HERE (I extract the diagrams from it), with various publications of different real-life applications.
However, while these design models are very promising, the actual implementation brings new challenges. The complex interaction of machine learning algorithms and system details can be expensive to maintain, especially when it comes to selecting and ranking items. This is where ‘fallbacks’ and ‘serving rules’ become very important, making the theoretical process more practical.
‘Fallbacks’ are a backup for situations where the main recommendation strategies face uncertainty or lack personalized data. Fallbacks make sure users always have options, ‘Serving rules,’ on the other hand, control how recommendations are shown to users, shaping their experience. These elements, which may seem less important, can be the difference between a successful and a confusing user experience.
Fallback Strategies: A Pillar of Reliability
In our Netflix-like example, the operation of the recommender system is all about creating recommendations based on past user interactions. However, like any system, there can be uncertainties and unexpected situations. For example, when a new user joins the platform or when the main recommendation function has technical problems, causing delays or failures in getting recommendations.
In these situations, ‘fallbacks’ are very important. A fallback is a backup plan, ready to be used if the main recommendation mechanism has a problem. It’s the safety net that makes sure users are not left without recommendations and helps keep a good user experience.
There are two main types of fallbacks to think about: those built into the recommender system itself and those linked to the application of the recommendation feature. The first involves strategic decisions made during the design and integration of the system, while the second focuses on user-facing issues like internet connectivity problems or API disruptions.
For our experiment, we will focus on fallbacks in the recommender system. Different strategies for handling exceptional situations can be done, each with its pros and cons. Strategies range from using popularity and recency-based metrics to including human insights to create fallback recommendations.
As part of our evaluation, I have used a combination of fallback policies for our use case. We check their performance over a specific period and use a simple metric, the hit rate at rank 10, to measure their effectiveness.
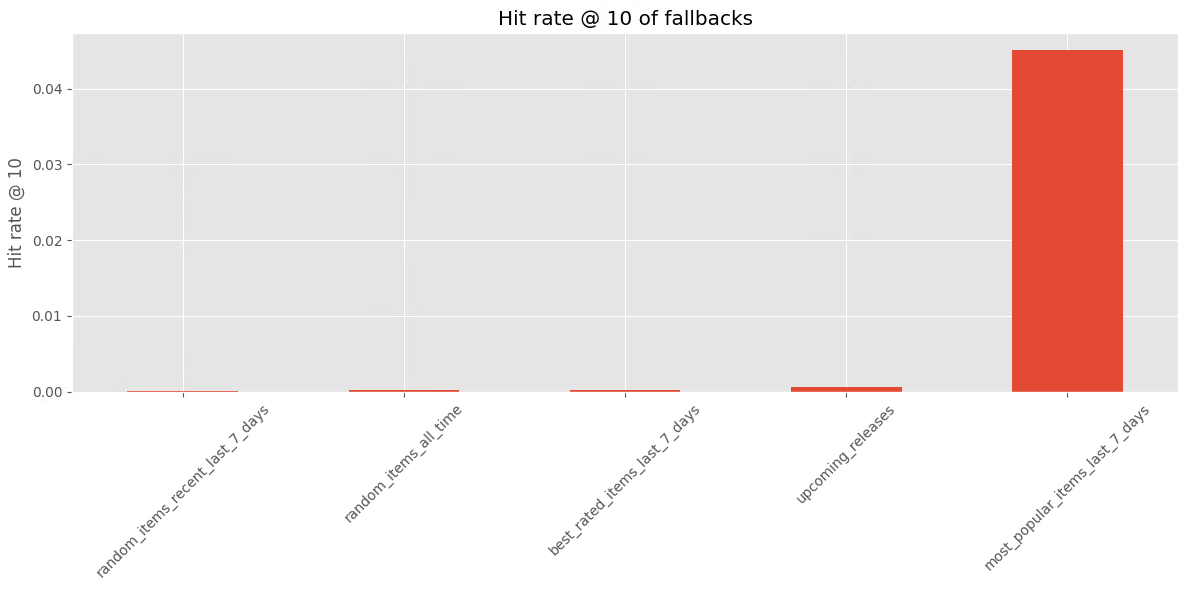
This metric fits well with the goals of the user interface and user experience of the recommendation feature. It becomes clear that, in some situations, giving priority to popular items from the recent past is a strong way to predict future user interactions (but a hit rate of 0.04 is pretty low but it’s the best one).
It’s important to remember that while our findings point out specific strategies, they are not one-size-fits-all rules..
As we finish this section, it’s worth noting that using fallbacks is not without its challenges. Relying too much on fallbacks could lessen the main recommender system’s role and hurt the user experience. Therefore, the interaction between fallbacks and the main recommendation process must be carefully balanced. This ensures a well-balanced mix that works well for both everyday operations and exceptional situations.
Tailoring Recommendations Through Serving Rules
As the recommender system works, the output it creates is just the start. This initial output, a list of possible recommendations, needs to be changed to match the needs and limitations of the application it is used in. These changes are controlled by ‘serving rules,’ a set of guidelines that shape the output into something that is not only relevant but also easy for the user to understand.
Thinking back to the earlier stages of designing the recommender system, serving rules often overlap with the business logic used during the ordering stage. These rules are made to apply filters that curate the list of recommendations, refining it to fit the application’s constraints. For my Netflix-like page, this means making sure that only the top 10 movies are sent for display, saving users from being overwhelmed with too many options. These rules are deeply embedded in your application’s user interface and experience. Also, they affect the very metrics that measure the success of your system—after all, why calculate metrics for ranks beyond what your application can show?
Furthermore, serving rules are closely linked to your chosen method for serving recommendations. Whether recommendations are served in batches or live, these rules change to accommodate the specific features of each approach. Batch serving allows for longer lists, catering to applications that can manage a wider range of choices. Live serving, on the other hand, focuses on speed and real-time delivery, influencing the length of the recommendation list.
In my own projects focused on cosmetic recommendations, a practical strategy I’ve found effective is to double the recommendations that can be displayed on the platform (it offers a decent safety in case of a serial buyers. Additionally, I prioritize promoting new content up until the upcoming weekend, carefully avoiding overstepping the recommender system’s role by allowing it to dictate content promotion. To maintain flexibility, I configure my serving rule thresholds externally (in a config file available in the project repository), allowing adjustments without disrupting the system’s workflow.
The beauty of serving rules lies in their adaptability—they’re not rigid standards but dynamic guidelines that ensure your recommendations are always in tune with the evolving needs of your application and its users.
Closing notes
Designing recommender systems involves more than just creating personalized recommendations with algorithms. Fallbacks and serving rules are playing a crucial role in shaping user experience and system practicality.
Fallbacks are backup plans that ensure users receive valuable suggestions even in difficult situations, such as system downtimes or the arrival of new users. They are essential for maintaining user satisfaction and system reliability, but they must be balanced carefully with the main recommendation mechanism to maintain effectiveness and user engagement.
Serving rules guide the transformation of raw recommendations into a curated list that fits the application’s limitations and user expectations. They ensure the recommendations match the user interface and adapt to different serving approaches, optimizing the output for the context of delivery.
In conclusion, the success of a recommender system extends beyond its algorithms. It involves a careful blend of strategy, design, and foresight, including the implementation of fallbacks and serving rules, to create an output that delights users and meets business goals.





{kind=link}