
Welcome to the exciting world of Marvel Snap, where strategy and skill meet to create the ultimate digital card game. Building the perfect deck is crucial to success, but with so many cards to choose from, it can be overwhelming to know where to start, especially when it comes to new cards. This is a common problem in the world of recommendation systems, known as the “cold start” problem.
This article will explore how to use a dataset related to Marvel Snap decks that I built recently. From understanding the game’s rules to discovering new card combinations and creating embeddings, this article will guide you through the process of building a recommendation system that can handle new items and help discover new approaches to playing Marvel Snap.
So let’s build the ultimate deck while tackling the “cold start” problem.
Building a Deck for Victory: An Introduction to Marvel Snap
A few weeks ago, I started to build a dataset related to a recent addition of mine, Marvel Snap, a digital card game built by Second Dinner.

The goal of building a deck in Marvel Snap is to confront players in 1v1 matches and win by having the higher power cumulated by the cards on the side of the player’s field.
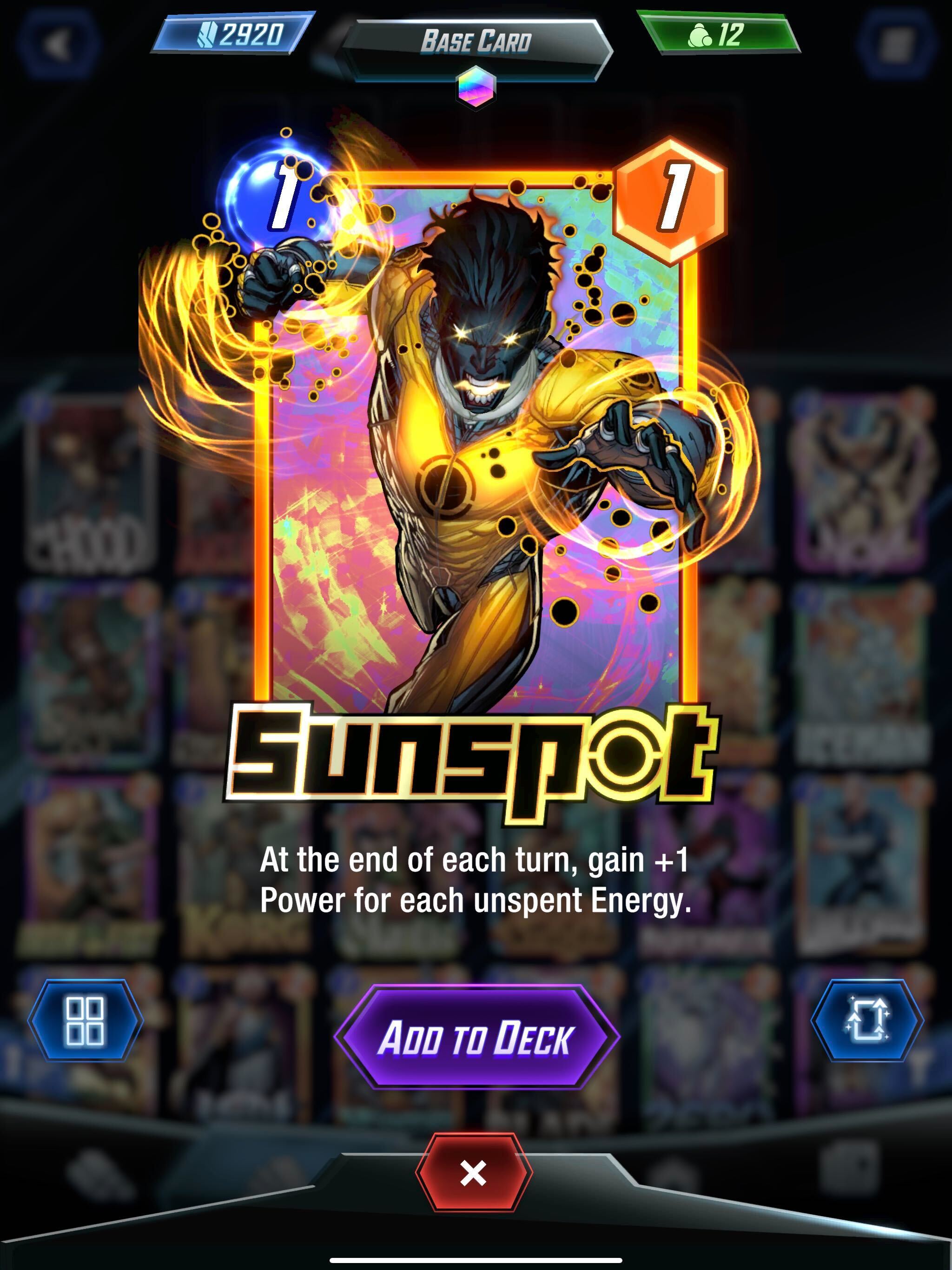
The number in the blue circle defines the energy, and this card possesses power (in the orange circle); this card can also have a unique ability that can be permanent or pops up during the reveal phase. Cards in Marvel Snap possess unique abilities that can be permanent or activated during the reveal phase; these abilities can give an edge to the player by increasing the power of the cards or adding new rules to the match.
It’s an entertaining game, easy to play, and hard to master, it was a very brief presentation of the rules, but if you want to understand the game better, there is a good video from the creators.
Now about the dataset, there are multiple sites where people share their best decks in the game; the most popular one is Marvel Snap Zone. I built a scraper that I ran periodically to collect decks and cards on the website, and you can find this data on Kaggle HERE.
After some ETL and filtering based on deck analysis (enough cards, right cards and last update date), there are around 20723 decks for 245 cards in the current version. There is a simple representation of the deck update since the official release of the game.

This dataset is good but far from being perfect :
- The art associated with the card is not all clean
- No information on the win rate of the decks and the card’s usage on a match
With all that in mind, let’s talk about recommender systems.
Creating a Winning Strategy: Implementing a Recommender System for Marvel Snap
For this section, I am balancing my role as a data scientist and a player of Marvel Snap and will use this dual perspective to design a use case linking the two.
One of the challenges of Marvel Snap is figuring out where to begin building a deck. As a player, I am very interested in a feature that can guide me in building a deck and kickstarting a deck from a specific card.
Here’s an example of what the feature might look like.

From the dataset that I built, it’s effortless to do it by building some association count per card with others (example HERE). There is an illustration of the flow of building these associations.

To illustrate this, I selected the following cards with very distinct attributes.

Sunspot is a 1-cost card with a unique ability to increase his power with remaining energies, Ka-zak supports one-cost cards, and Heimdall is a strong card with the ability to move cards. If we go back to the association, it’s simple to rank the card by the occurrence they are associated with together. There are some results for the selected three cards.



The associations are making, from my experience, a lot of sense, but there is some analysis:
- Sunspot is linked to solid cards, and there is a connection with other cards having abilities related to energy level (like she-hulk)
- Ka-zak, is linked to squirrel girl and Ultron produced cards that can be enhanced by his ability OR other cars that enhance the power of 1 cost cards.
- Heimdall is linked with cards that can move on the field or are enhanced by a movement.
We have a vector that stores the overall association normalized with the other cards for each card (It’s a vector with more than 240 components). This vector is an embedding, and as it’s normalized, so it’s easy to calculate a distance between the cards based on the embedding. To make computation easy , we will go with the euclidian distance , but there was other options possible.
There is a visualization of the distances.

With these distances, it’s easy to build other kinds of recommendations that will have a more profound knowledge of the associations of cards. (shortest distance means they are closer)



There are still similar recommendations, but new trends are rising (like hulk + sunspot).
In a game like that, new cards can appear with new releases or some player reaching a certain amount of experience; recently, Zabu came under my radar.

Based on the previous recommender systems, there are recommendations for Zabu.

As expected, the feature is not working anymore.
I dropped all the decks associated with Zabu to simulate it as a new card and illustrate this pitfall of recommender systems.
Discovering New Approaches: Handling Cold Start and Building Embeddings in Marvel Snap
This example perfectly illustrates a phenomenon in the recommender system called cold start for an item. The cold start can be of two kinds:
- User: A new user signs up to an e-commerce platform and starts browsing the products but has yet to view, purchase or rate any items.
- Item: a new product has just been added to the platform but has yet to be viewed, purchased or rated by users.
In this scenario, the recommendation system lacks enough data on the user’s interaction with the product or the product’s characteristics to make accurate recommendations.
In our case, it’s a cold start related to an item because there are no interactions, so building recommendations is impossible (with the same previous methods), but don’t worry, there are solutions to heat the situation.
** This is one possible approach, but that will give an overall idea of a possible flow to tackle the cold start problem related to items, but keep in mind there are more straightforward or more complex approaches to tackle this problem**
The idea of the flow is represented in this schema

This flow can be assigned to a hybrid recommender system because it mixes content-based filtering (step 1) and classic recommendation technics (step 2). The second step is pretty simple, but how to find the closest cards to the Zabu card? We know the card’s characteristics, like its cost, power or ability, and it’s enough to prototype something.

The idea is to build embeddings; I wanted to go the text way, build a description of the card that will embed the cost, power and ability and, after that, use a transformer to create embeddings from the description.
The function to build the description is straightforward.
dfp_cards["description"] = dfp_cards.apply(lambda row: f"This card is called {row['cname']} with a cost of {row['cost']} and a power of {row['power']}. His ability is {row['ability']}".lower(), axis=1)Now the tricky part is the transformers , let’s start by a meme.
![]()
Transformers have been the hot technic in machine learning in the last five years; it’s the approach behind applications like dalle or chatgpt, for example. They are also used in other domain than generative AI, like recommender systems (cf recsys 2022 recap), computer vision etc.
How does it work under the hood? So remember that transformers are a type of neural network architecture that Google introduced in 2017 in the paper “Attention is all you need.” The critical part of this architecture is its self-attention mechanism, which allows the model (in an NLP context) to weigh the importance of different words in a sentence when making predictions. In addition, this allows the model to handle input sequences of varying lengths and long-range dependencies in the data.
Currently, there is a lot of different architecture using the Transformers idea with a few twists; I linked a few papers on the topic:
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- GPT: Improving Language Understanding by Generative Pre-Training
- GPT-2: Language Models are Unsupervised Multitask Learners
- GPT-3: Language Models are Few-Shot Learners
- Roberta: A Robustly Optimized BERT Pretraining Approach
- ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
In the original article of Google the architecture looks like that.
![]()
It’s composed of an encoder and a decoder; in our case, we will only focus on the encoding part, but if you are curious to understand how it works, there is an excellent course on Hugging Face with a chapter dedicated to it HERE.
To leverage the encoder part of a transformer, I used a package called sentence-bert that leverages PyTorch and Transformers (of Hugging Face again, one of the creator of the package is a former Hugging Face) to make the pieces of a transformer accessible easily, and it’s effortless to do.

(I used the model based on Microsoft mp-net in this case)
With this technic, it’s straightforward to encode the description and get an embedding (with this model, it’s a vector with 768 components). If we applied this technique to all the cards, there are a few results for the selected initial cards (Sunspot, ka-zak and Heimdall) based on the euclidian distance between their descriptions embeddings.



As we can see, there are a few exciting connections, similar to what was in the deck association (like Heimdall-Quake, for example), but new trends also emerge.
Let’s go back to Zabu, his closest card from the analysis of the euclidian distances seems ka-zak, so there are the recommended cards based on my flow.


To be honest, I think it’s not making too much sense, I rebuilt an association matrix with all the cards, and there is the expected recommendation (based on association)

It makes more sense for sure (for many 4-cost cards, Zabu is beneficial to ease their usage).
Can we say it’s a failure? Not really, because I think the approach is still good (in the flow) but needs a few tweaks to be better :)
Wrap-up and next steps
This article was the occasion to :
- Give more details about my recent dataset on Kaggle (keep in mind that I will try to update it regularly also)
- Explore the encoding of an item based on its description; I think that still a solid approach to start that needs a few tweaks (with metrics to optimize)
There are plenty of other approaches to building embedding for an item or tackling cold start in general (based on the kind of items and recommendations to provide), so it will not be the last experiment on the subject for me. To be honest I think to design this kind of recommendations , for the number of cards available I think starting with hard coded rules for each card can be feasible and make more sense.
As a bonus, I also decided to play with Hugging Face Spaces, to deploy and operate a “live” version of the recommender systems. So I just embedded the different recommender systems in this application, and you can use it here also (no plan to make an update of the data/app, but who knows).
I had a hard time using the git integration, but Hugging Face also offers an excellent drag-and-drop way to deploy spaces.
This project gave me the motivation to :
- Dig more into using deep learning technics like transformers in general (I just found this great notebook related to recommender systems from Janu Verna from Microsoft)
- Work on a project around embedding visualization/dimensionality reduction: I played with this data and TSNE, but I want to take more time on it.
- Start some NLP use cases.
Beyond this article, I enjoy discussing data, AI, and system design—how projects are built, where they succeed, and where they struggle.
If you want to exchange ideas, challenge assumptions, or talk about your own projects, feel free to reach out. I’m always open for a good conversation.







{kind=link}