
Last year, I started to explore the game-engine world to delve deeper into my experimentation/exploration of the machine learning field. I had some fun exploring Unity, but I wanted to take a step back to explore the algorithms and approaches for training game agents in more detail before focusing on building an (game dev !? like) environment.
To do that, I wanted to start with a simple, physics-based game because it’s fun, but I wanted to avoid the recurrent Tetris, Super Mario Bros, Flappy Bird, or Dino game projects. These are fun, don’t get me wrong, but they can lack originality for me. Last Christmas, I discovered the game Suika Game, or Watermelon Game, which I think is the perfect candidate for this experiment. This article will focus mainly on:
- Explaining the game and the setup
- Developing the first agents, which will be my baseline agents for future experiments (in order to train a Suika master).
PS: I know that I am not the only one to have tackle this game as an ML project
Suika what?
It is a Japanese puzzle video game by Aladdin X, which combines the elements of falling and merging puzzle games. The game was originally developed for the company’s digital projectors in April 2021 and, due to its initial success, released on the Nintendo eShop in December 2021 in Japan. After gaining popularity, it was made available globally in October 2023. The concept originates from a Chinese browser game titled “Merge Big Watermelon” that was released in January 2021.
The game involves the player trying to build a high score by dropping fruits into a container without having them overflow. To earn points, the player must combine two of the same fruits, which creates a new fruit in the game’s fruit cycle. There is a link to a web version HERE with plenty of variants (like a taylor swift one)
For me, it’s kind of a physics-based mashup between Tetris and Puzzle Bobble, easy to play but hard to master. With that in mind, I decided to start my own implementation in Python, and after 2-3 hours of coding, this is where I went.

So, managing the spawn and fall of fruits was definitely not difficult, but my struggle started when I wanted to add some physics to the thing (as pygame is not a physics engine). So, I decided to search the internet for some existing implementations, and my research led me to this video by OB1 (the YouTube channel seems to have pretty cool stuff).
He presented his own implementation of the game, with an associated repository. All the physics of the ball/particle is leveraging another package called Pymunk, specialized in 2D physics.

I made a few tweaks to the original implementation, to be played by a machine and not a human (originally you should use your mouse), and now I have everything to comtinue my experimentation.
Gym and agent design
The foundation for my experiment will be the gym where the agent will execute actions to play the game, and these actions will be logged with the status of the environment. In our case, the environment is composed of the fruit container with the previously fallen fruits, the score, and the next fruit to fall.
My gym is pretty limited to one setup compared to others like the one from OpenAI (which seems to have switched leadership recently), that contains a lot of different environment. A “gym session” looks like that.
import gymnasium as gym
env = gym.make("LunarLander-v2", render_mode="human")
observation, info = env.reset(seed=42)
for _ in range(1000):
action = env.action_space.sample() # this is where you would insert your policy
observation, reward, terminated, truncated, info = env.step(action)
if terminated or truncated:
observation, info = env.reset()
env.close()
An instance of an environment can be set up where a general agent can interact with it at specific steps. At the end of the play, you can reset the environment. Note that there is also the notion of a reward in this gym, which illustrates its use in reinforcement learning applications.
It’s a really neat design. I aimed to have something that looks like that, but my design is simpler.
The script running the environment is called simulation and can be run with different parameters:
agent: to define the kind of agent that will run.scenario: a path to a file that defines the scenario of fruits that will fall (explained later).
The scenario parameter allows you to provide a specific pattern of fruits that will fall during the simulation. I set up a pattern of 1000 fruits. If the simulation goes beyond these 1000 fruits, a random assignment will happen (as if you didn’t provide any scenario). I want to provide a scenario pattern to offer a simple replayability ability to my setup, allowing logical comparisons (to compare typical patterns and see how the agent behaves in a similar context).
In the script, after the declaration of the agent, the environment will play, and this is where the magic begins (every 2 seconds).
The overall idea is that in the environment we are going to:
- Check the states of the particles (aka fruits), which means their position in the container and the kind of fruit.
- Build an observation that will be composed of:
- The states of the fruits
- The fruit that needs to be dropped
- The score
- The timestamp
- Based on the observation, the agent will take action to move the fruit to a specific place.
- The observation will be saved in a buffer.
This loop will continue until the game ends (if you reach the top of the container). In this case, the buffer will be saved in a CSV file with the different information collected in the buffer during the run.

Another aspect of the environment to train the agent is the ability to multithread different plays in parallel. In my case, I decided to use a bash script to run different plays in parallel (not more than 4). My approach is brute force, but it does the job for the experiment on my laptop.
Now let’s discuss the fun part, the agent.
To start, I am going to use the definition of the agent found in the book Artificial Intelligence: A Modern Approach. Big shoutout to Nguyen Nguyen for introducing me to the book, and to the Ubisoft garage sale that gave me the opportunity to buy the 2nd edition. In this book, the authors define an agent as:
An agent is anything that can be viewed as perceiving its environment through sensors and acting upon that environment through actuators.
Very theoretical, and they have a nice schema also in the figure.
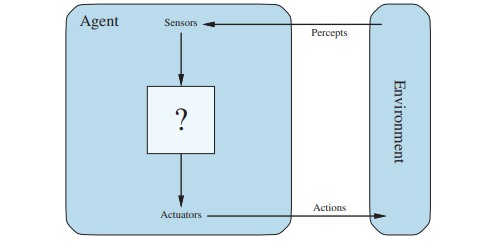
So in my case, the agent will perceive the fruit to drop, the status of the container, and the score. Its action will be to move the fruit and drop it. Pretty easy, right? :)
I’ll be honest with you, I find my setup of the perception to be somewhat of a cheat because it’s very embedded in the environment (as I am collecting all the data directly from the environment). You might expect an agent to not have this level of integration in real life, but in the video game industry, this is the reality. Agents are plugged directly into the engine, so they don’t need to perceive the game from the outside (as a human player would).
Going back to the agent itself, the “question mark box” called the agent program implements the agent function to process the data from the sensors into actions via the actuators. This is where the intelligence (artificial?) takes place.
There are multiple kinds of agents defined in the book, such as goal-based agents, reflex agents, and utility agents. I strongly recommend you look at the book if you want more details on that. In my future experiments, I will try to dig into these concepts in more detail and apply some algorithms behind them in future articles
So we have the gym/environment, and we have the agent. Let’s code the first agents.
First Agents: Random & Baseline
To start, I wanted to create some simple agents with very simple rules behind the agent program to establish a baseline for future evaluations using more advanced ML techniques.
My first agent, which we’ll call Random, is simply a system that will drop the fruit randomly in the container. Yeah, I know it’s boring, but the results are not so bad.
My second agent, called Baseline, is a simple rules-based model with the following rules:
- If the fruit to fall finds a pair in the fruit container, make it fall to the closest similar fruit.
- If no fruit matches in the container, drop it randomly.
I included the code here if you are curious:
These basic models can interact with the environment and start to play Suika on their own. For this environment, I can see different metrics to evaluate how the agent is behaving: the score of the play and the number of steps in a play (or a series of plays).
I conducted a small benchmark of the agents in two contexts: one in a series of 10 random plays and the second in a pre-made scenario, Scenario 10. I compiled the results of the agents in the following two graphs.
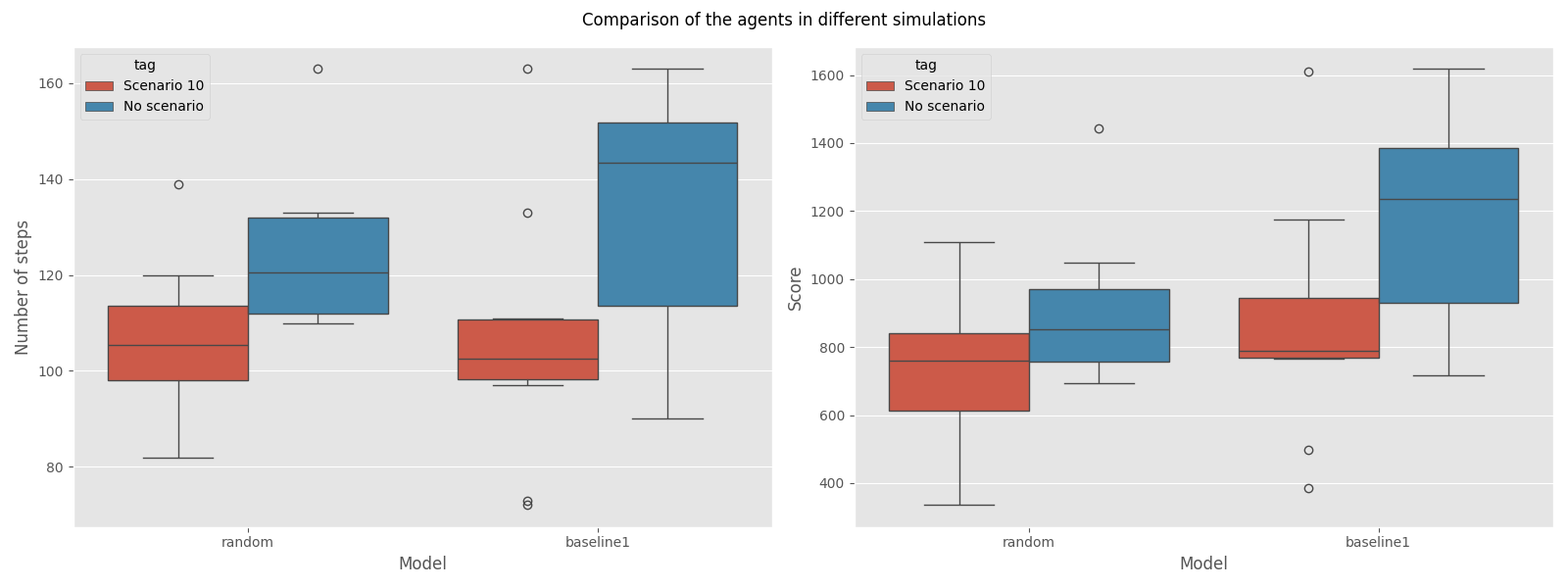
Overall, it seems that:
- In the random play context, the Baseline is slightly better than the Random one, but their average scores are pretty close (around 800).
- In the Scenario 10 context, the Baseline model has longer plays and generates more points (900 vs. 1200).
So the big question is, how do these agents behave compared to a human player? From my understanding and experience:
- An average player (like me) seems to reach a score between 1800 and 2500 in random plays.
- The top scorers in the current week are closer to 4000 (but slightly under).
So our baselines are far from reaching an average player, which means there is room for improvement (and learning stuff) :)
Next steps
This article/project was just an appetizer, and I will continue to work on it in the following weeks with a focus more on agent program development.
I see the following steps in front of me:
- Algorithms exploration:
- Benchmark the new agent against the current baseline and average player (2000), and top scorer (4000).
- I have in mind genetic algorithms, reinforcement learning, supervised learning, and maybe LLM (because it seems to be the thing these days) to explore in the future.
- Improvement of the environment:
- Handle time acceleration to run faster experiments (= more experiments).
- Switch from the agent embedded in the environment to the environment embedded in the agent.
- Deployment of the simulation and training environment (why not !?)
To be honest, I will mainly focus my work on algorithm exploration, so stay tuned for future posts on the subject.




{kind=link}