
This is this time of the year (with a small delay, I know) when I am doing a recap of the RecSys conference, which this year took place in Bari, Italy. I attended the event virtually (thanks to Ubisoft for the ticket). In this article, you will find a selection of the best papers, posters, and workshops that I discovered during this event.
Matrix factorisation everytime everywhere all at once
As usual, at the conference, there were multiple papers discussing the topic of matrix factorization, which is always a strong component of the recommender systems field (I wrote about it this summer). For this year, I picked two papers on the topic.
The first article is The Role of Unknown Interactions in Implicit Matrix Factorization: A Probabilistic View. This is a question I’ve always had in mind—how the weight of unobserved items can impact the predictions of recommendations (basically, what’s the impact of matrix sparsity?). Usually, algorithms like ALS handle these unknown interactions through negative sampling, but I’d say this is an oversimplification of reality. For example, non-interaction doesn’t always mean a lack of interest; it might simply mean the user didn’t see the item (based on the interaction funnel, like content hidden in an unusual place, such as at the bottom of a dropdown menu, etc.). The paper proposes a probabilistic approach called LogWMF (Logistic Weighted Matrix Factorization) to assign different weights to unknown samples by giving a probability for each unknown interaction to be either positive or negative. This is achieved by using a logistic function to model the probability of positive interactions and representing unknowns as the product of positive and negative probabilities.
This approach encourages the model to find a balance between the two possibilities. The unknown probabilities are approximated with a Gaussian function, enabling efficient optimization.Their benchmarks seem to slightly improve some metrics compared to the implicit version of ALS. They also extend this probabilistic approach to tweaked versions of EASE (logEASE and WEASE), inspired by their method for LogWMF (I am attaching the results).

The other article I picked related to matrix factorization is one that combines factorization with Graph Neural Networks. Integrating Matrix Factorization with Graph-Based Models is a very brief article that provides an overview and general reflections on how these two methods could be integrated to work together to produce recommendations. For example, it includes a representation of how a similar dataset could be represented in both a factorization and graph context.
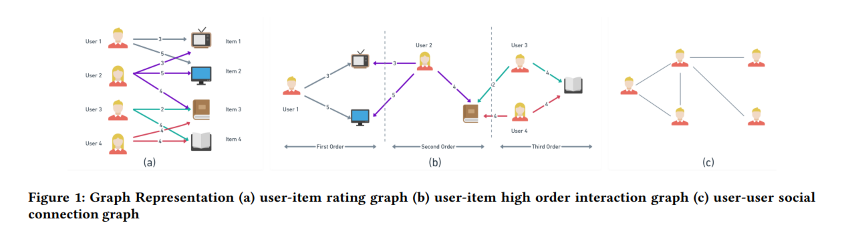
There is a strong emphasis that NMF techniques seem to be the best methods for matrix factorization (based on some surveys/reviews).
If, like me, graphs have always intrigued you, I once had an intern (👋 Cyril M) who worked on the topic in 2019. However, I’ve never really had time to dig deeper into it since then. There’s also a tutorial that took place during RecSys, presented by Panagiotis Symeonidis, as an introduction to using graphs for recommendations. This tutorial is part of a larger body of work by the professor, which seems super interesting for anyone curious about recommender systems in general.
Grouplens: How to reinvent the recommendations flow
Most of the time, recommendations are very static, where you cannot directly influence the output or only provide very explicit feedback that will affect the flow later (like ratings on Netflix or Prime Video). However, GroupLens (the team at the University of Minnesota behind the famous MovieLens dataset) published two interesting papers this year about experiments they conducted to rework the recommendation process by gathering more input from users during a session.
One of these papers, The MovieLens Beliefs Dataset: Collecting Pre-Choice Data for Online Recommender Systems (awarded at the conference), illustrates an experiment by some GroupLens members. In this work, they explore how to collect specific feedback by asking users: “What do you think of this movie?”
For example, in the context of movies, a user might believe they would enjoy a comedy more than a horror film, even if they haven’t seen specific movies from those genres. These beliefs influence the user’s choices. When a platform suggests a movie the user hadn’t considered, it can change the user’s initial belief about that movie. If the recommendation is effective, it might persuade the user to watch a movie they wouldn’t have chosen otherwise.
In this approach, they aim to capture the user’s overall perception of the displayed content. They used economic mechanisms of user decision-making to model this phenomenon (with concepts like “good” and “utility”). They also developed a specific interface in the MovieLens app to collect this feedback. The interface includes a “seen or not” feature (to determine if the user missed rating the movie) and a 5-star rating system to capture the user’s general perception.
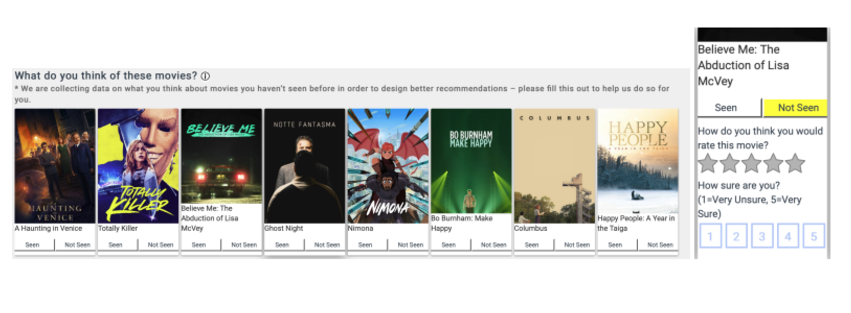
I’m not sure how we could see this implemented on common streaming platforms, but I’m a big fan of explicit feedback. Personally, I would love to have the option to evaluate what’s being offered to me in the recommendations.
They also shared some numbers on how their feedback collection campaign went. It seems that 7.8% of the time, a MovieLens user who received a belief suggestion filled out the form. Not so bad, if you ask me! The dataset should be public and available here, but unfortunately, the link doesn’t seem to work.
In the second article, Interactive Content Diversity and User Exploration in Online Movie Recommenders: A Field Experiment, the team worked on the ability to surprise the user (the ongoing question of exploration vs. exploitation). In this case, they made some tweaks to the MovieLens UI to test two things:
- Adding a carousel that extends the length of the recommendations displayed.
- Introducing a slider that gives users more control over what is displayed.
These changes impact how diverse the recommendations are. For instance, the diversity slider allows users to influence the variety of content they see.
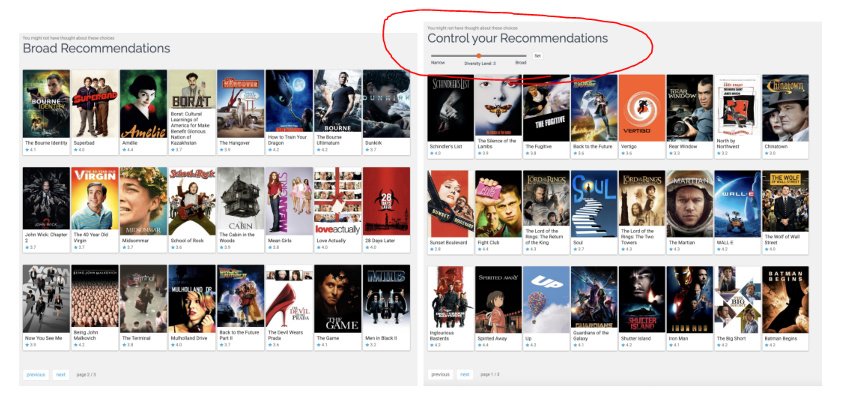
They ran a six-week experiment in 2022 with 1,859 active users from the platform in 2021. These users were randomly assigned to a treatment group (carousel or slider).
Keep in mind that on MovieLens, you can change the type of recommendations you want to receive by choosing one of four paths: Peasant, Warrior, Wizard, or Bard.
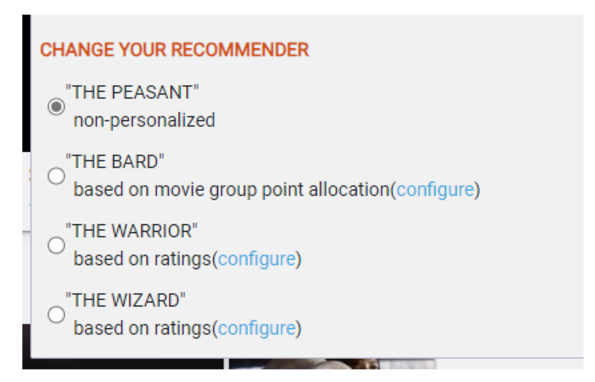
During the study, they made a few interesting findings:
- Users with more diverse tastes who interacted with the carousel during the experiment seemed to continue engaging more with MovieLens afterward.
- The carousel appeared to be more effective than the slider (so sad about that!).
However, the paper also highlights an important point: the design of the recommendation system itself can influence how these UX updates impact the user journey.
Overall, these experiments from GroupLens are really cool and reflect a trend I’ve noticed at the RecSys conference, where “companies” are exploring new ways to interact with recommendations (like Deezer’s Flow Moods paper). They also mention that one of their next steps is to explore conversational recommenders and AI-powered tools to better address diverse user needs.
Reproducibility papers
As usual, there’s a paper about benchmarking implementations, and this year I picked an article about Bayesian Personalized Ranking. The paper, Revisiting BPR: A Replicability Study of a Common Recommender System Baseline, provides an overview of the algorithm’s implementation along with the various features enabled in the process (like in this table).

They benchmarked both open-source implementations and their own, discovering that Cornac’s implementation stands out with impressive performance. Additionally, the BPRs on Elliot closely mirror the original 2009 paper, making them highly reliable.
A recap of the RecSys conference wouldn’t be complete without mentioning a paper from Deezer (and the CNRS). This year, the article Do Recommender Systems Promote Local Music? A Reproducibility Study Using Music Streaming Data took center stage. They revisited a previous study, Traces of Globalization in Online Music Consumption Patterns and Results of Recommendation Algorithms, which suggested that certain recommender systems might exhibit biases against local music.
Deezer and the CNRS aimed to reproduce these findings using proprietary data, focusing on the French, German, and Brazilian markets, where Deezer is a local leader. Interestingly, they were unable to replicate the original study’s results, which were based on the lfm-2b dataset. The paper includes a quick representation of local streams in both datasets.
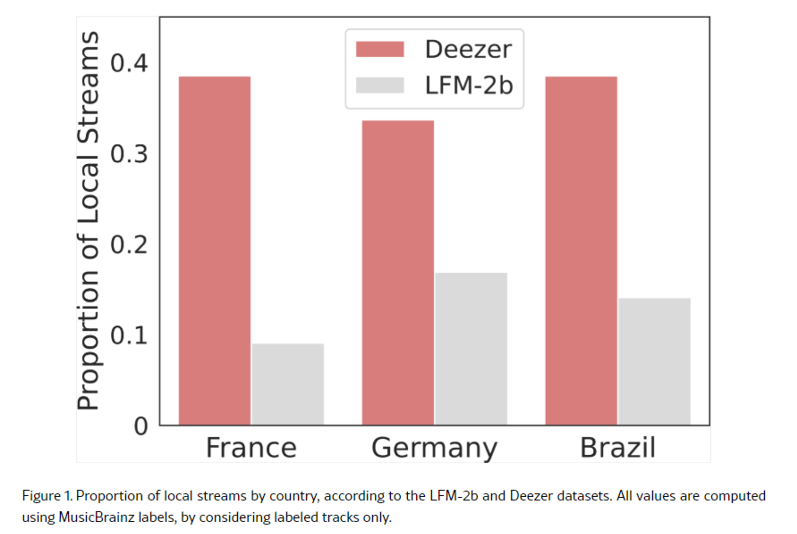
The authors also analyzed the algorithmic biases of two recommender systems, NeuMF and ItemKNN, used in the original study. However, they found that the biases observed on LFM-2b did not consistently translate to the Deezer dataset. In some instances, the direction of bias even reversed depending on the dataset, training parameters, and label source used.
LLM this LLM that
As expected, language models were a hot topic at the conference, reflecting the growing popularity of transformer-based systems over the past few years. I came across some articles that are definitely worth delving into.
The first one, from Microsoft, is titled Analyzing User Preferences and Quality Improvement on Bing’s WebPage Recommendation Experience with Large Language Models. In this article, the team presents how they leverage large language models to create snippets of websites that can be recommended in the “Explore Further” feature.
They used GPT-4.0 to generate high-quality titles and snippet summaries for a large dataset of webpages and fine-tuned Mistral 7B to scale this task. With these new insights, they managed to create multiple recommendation scenarios such as:
- Same Tier Alternative: Substitute webpages or services.
- More Authoritative Alternative: Webpages with higher authority on the topic.
- Complementary Recommendation: Content that complements the original webpage.
They classify the websites based on the evaluation of the LLM.Additionally, they developed a new metric called Recommendation Quality Discounted Cumulative Gain (RecoDCG), which scores website pairs based on their relevance and quality, incorporating LLM-generated assessments.
The other articles I picked are from Spotify, discussing search in two components and specifically how LLMs are used to generate synthetic data to train models. The first one is Encouraging Exploration in Spotify Search through Query Recommendations, where Spotify outlines their approach to improving the search mechanism.
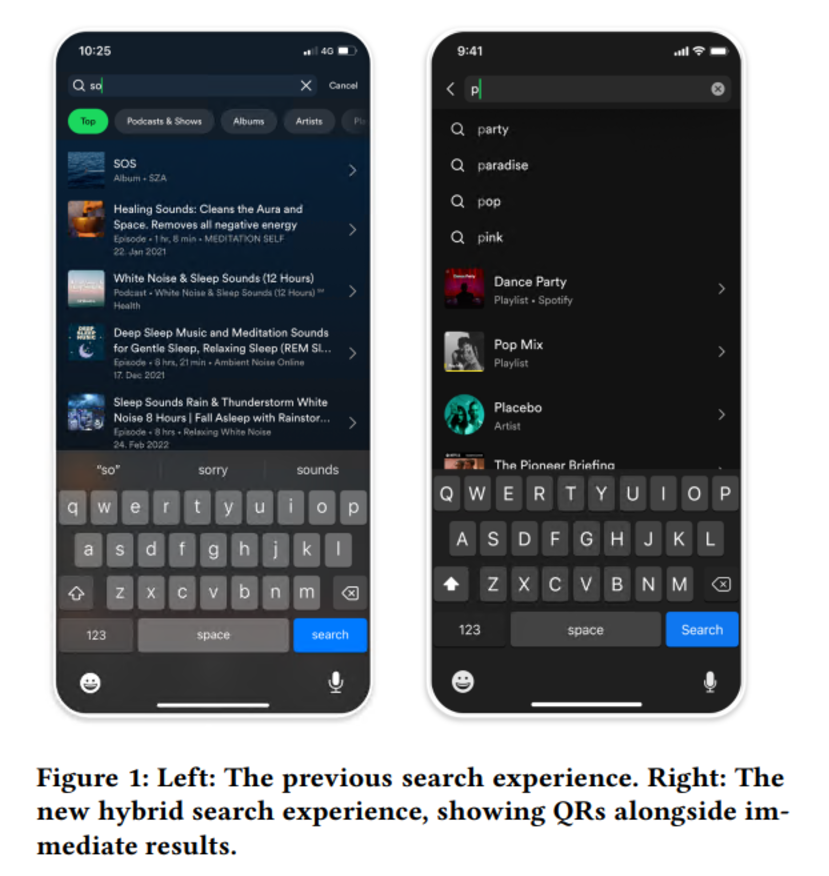
In this case, the goal is to make query recommendations (QR) and explore different methodologies to build new queries, such as:
- Extracting queries from catalog item titles (e.g., artist names, playlist names)
- Mining complete queries from search logs
- Leveraging users’ recent searches and personal items
- Using metadata and expansion rules (e.g., “[artist name] + covers”)
- Employing LLMs to generate natural language queries
Their QR system is a hybrid one that works with their instant search, providing recommendations alongside immediate results. This hybrid approach aims to support both known-item and exploratory searches. They observed some interesting results:
The introduction of QR led to a 30% increase in maximum query length per user and a 10% increase in average query length. This suggests users are formulating more complex searches. The system resulted in a 9% increase in the share of exploratory queries, indicating that users are engaging in more discovery-oriented searches.
The other article from Spotify that I picked, Bridging Search and Recommendation in Generative Retrieval: Does One Task Help the Other?, investigates whether training a single generative retrieval model on both search and recommendation data can enhance performance for both tasks. This research is more theoretical and offline, with no impact measured in a live manner, but it still provides a great example of how LLMs can be used to create query variants.
The study suggests that training a single model on both search and recommendation data improves the model’s ability to understand items and make better predictions by combining content and user behavior information.
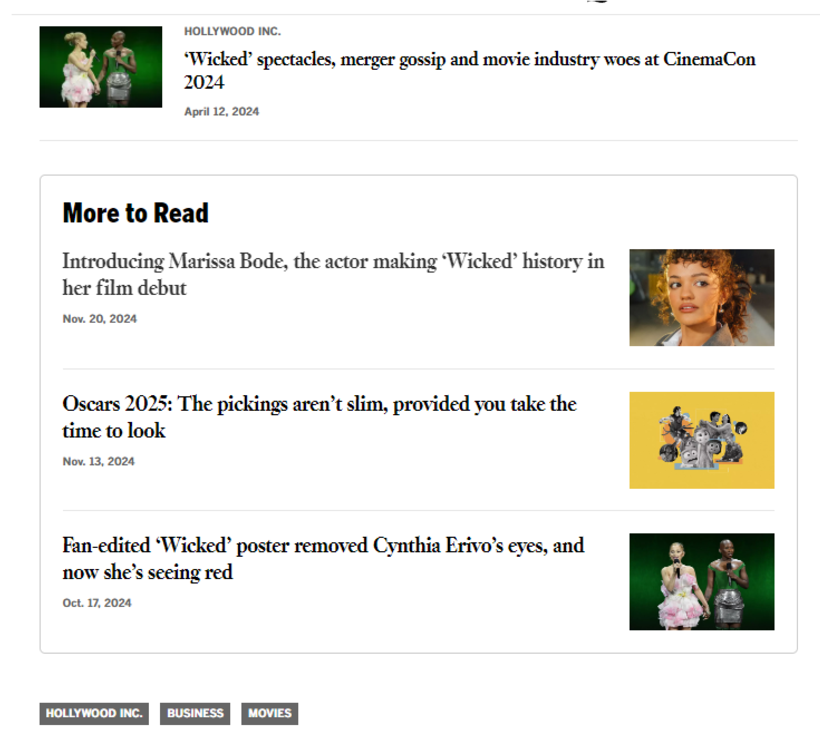
Finally, there’s a very short but interesting article from the Los Angeles Times titled More to Read at the Los Angeles Times: Solving a Cold Start Problem with LLMs to Improve Story Discovery. This article presents their “More to Read” feature, which suggests similar articles that readers might find interesting , there is a screenshot of the feature.
They benchmarked two systems: one based on TF/IDF (term frequency–inverse document frequency) and the other on GTE (General Text Embedding). Both systems showed impressive results, achieving a 39.4% increase in CTR compared to a popularity-based model, indicating that users found the recommendations more relevant and engaging. However, these two systems differed in the type of recommendations they generated:
- TF/IDF: This system tended to recommend articles that were highly similar to the seed article, creating a more immersive experience for the user.
- GTE: This system identified articles that explored related themes and contexts, offering a more novel experience that encouraged exploration of tangential topics.
To illustrate the difference, they looked at an article about Jennifer Aniston and cancel culture. The recommendations from the two models clearly differed in content, showcasing the unique strengths of each approach.

The classification of similarity is based on a comparison of the 5W1H (Who, What, When, Where, Why, and How) of each article. Immersive recommendations have closely matching 5W1H elements, while novel recommendations have more diverse 5W1H elements.
In the end, the LA Times selected GTE for its ability to offer more novel recommendations, which helps limit the filter bubble and echo chamber phenomenon.
The misfits !?
For this section, I wanted to aggregate a few articles that don’t fit into the larger sections but are definitely worth reading.
The first one is A Dataset for Adapting Recommender Systems to the Fashion Rental Economy. This introductory article, available on Kaggle, highlights a unique setup for making recommendations with very specific constraints, such as Clothing Wear and Decay: as items are rented multiple times, their condition deteriorates. The article also mentions a useful GitHub repository for data processing.
An interesting finding from the paper is the use of the EfficientNet_V2_L model for tagging images of clothing. This model appears to be one of the best based on their benchmark , there is an overall representation of the tags associated to the outfits (Thanks to Karl Audun for the wordcloud distribution of the tags).

Another article I picked is A Pre-trained Zero-shot Sequential Recommendation Framework via Popularity Dynamics from the University of Illinois. The team developed a method called PREPRec, which utilizes a novel popularity dynamics-aware transformer architecture to exploit shifting user preferences highlighted by the popularity dynamics of interacted items.
The goal is to encode the sequence of actions based not on the item itself but on the trendiness of the item over short-term (like 2 days) or long-term periods (like 10 days). The article also provides an overview of the transformer’s architecture.
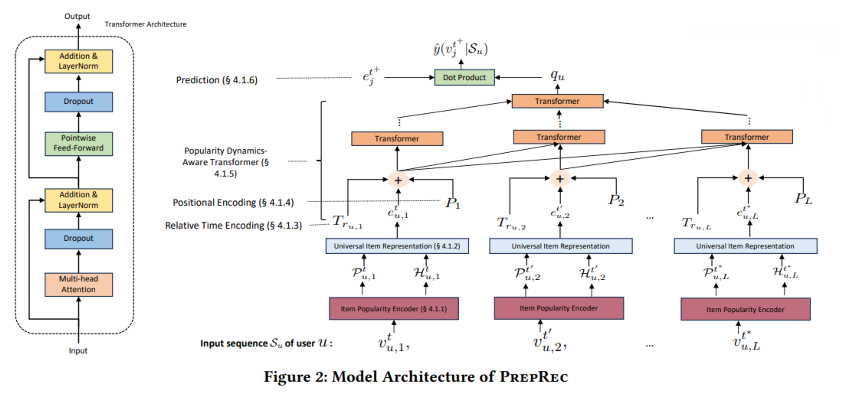
The code and theory seem a bit complex, but the results are very impressive, such as:
- Up to 6.5% performance improvement in Recall@10 for zero-shot cross-domain transfer compared to target-trained models.
- 11.8% average increase in Recall@10 and 22% in NDCG@10 when interpolating PREPRec results with BERT4Rec.
- 12 to 90 times smaller model size compared to BERT4Rec, SasRec, and TiSasRec.
I found the approach really innovative and potentially very transferable in contexts where applications are released regularly, even if they vary in structure (like video games 😁).
A/B testing is a strong component, and there’s a great article, Powerful A/B-Testing Metrics and Where to Find Them from ShareChat, that provides an excellent overview of the paradigm for a recommender setup. I really enjoyed their visualizations on metrics in their slides, which I think could be a great recap for any A/B test analysis.
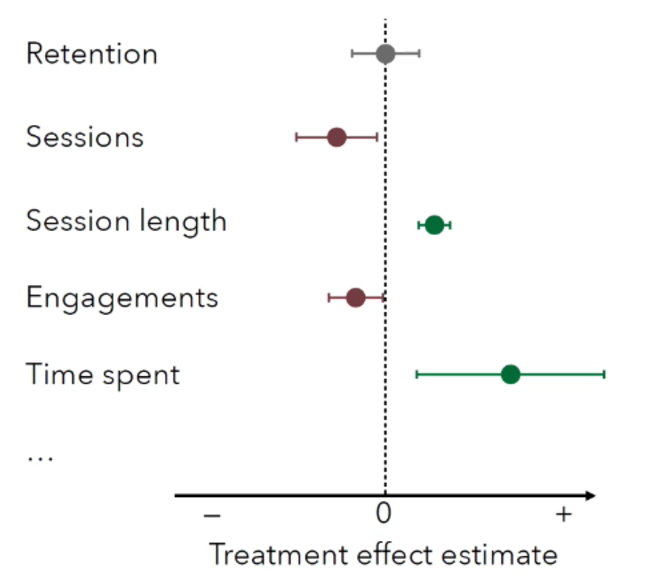
Another cool initiative is the work from the University of Siegen, titled Recommender Systems Algorithm Selection for Ranking Prediction on Implicit Feedback Datasets. This study explores the problem of algorithm selection for recommender systems focusing on ranking prediction using implicit feedback datasets. To address this, they created a meta-dataset encompassing the performance scores of 24 different recommender system algorithms (with two hyperparameter configurations each) on 72 diverse datasets. These datasets represent a variety of sizes, domains, and characteristics, including various numbers of users, items, interactions, and data sparsity, which compose the meta-features from the data.
They trained several meta-learners, including traditional machine learning models like Linear Regression, K-Nearest Neighbors, Random Forest, and XGBoost, as well as an automated machine learning algorithm (AutoGluon). The results are impressive:
- The best meta-model in terms of Recall@1 (correctly predicting the top-performing algorithm) is XGBoost, achieving a recall of 48.6%.
- Random Forest excels in Recall@3, identifying two of the top three algorithms for 66.9% of the datasets.
- Automated machine learning with AutoGluon demonstrates a slightly higher correlation with the ground truth ranking compared to traditional models. However, traditional models slightly outperform AutoGluon in predicting the best and top-three algorithms.
I think this article could be a great starting point for anyone looking to explore which algorithm to use for a new use case. It also offers practical guidance for practitioners seeking to optimize recommender systems.
A big trend in recent years has been using multi-modal approaches to tackle recommendations. There’s a great article from Kuaishou Technology titled A Multi-modal Modeling Framework for Cold-start Short-video Recommendation. In this article, they explain their system called M3CSR, a new multi-modal modeling framework designed to address the cold-start problem in short video recommendations. The authors highlight the challenges of recommending new videos with limited user interaction data, focusing on the gap between pre-trained multi-modal embedding extraction and personalized user interest modeling.
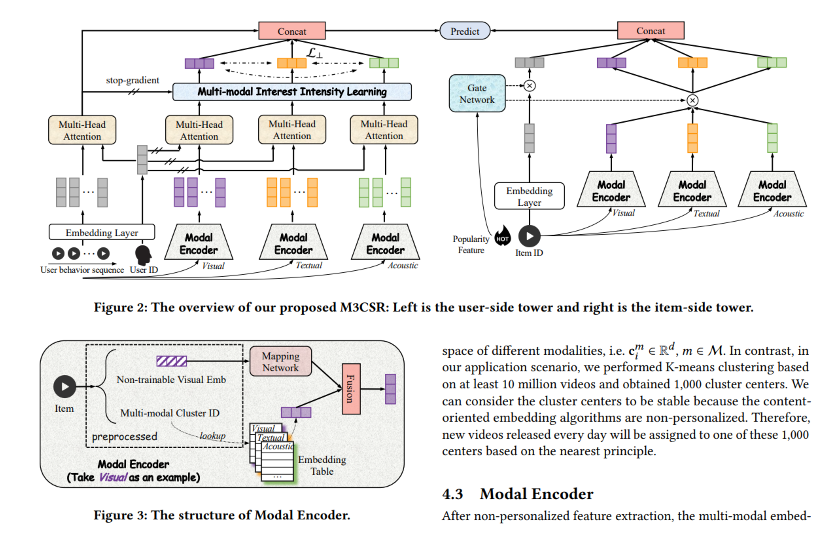
They mix the sequence of user actions with the relationships between items based on their modality (image, acoustic, textual). To build these modalities, they use “small models” like:
- Image modality: Resnet
- Text modality: Sentence-BERT
- Acoustic modality: VGGish
All these modalities can be used to associate new videos with cluster IDs, which can then be used in the dual tower process to make recommendations on the fly. It sounds complex, but they have achieved very impressive results during A/B testing on various metrics (though the control group details are not provided):
- Engagement: Click-through rate (+3.385%), likes (+2.973%), and follows (+3.070%) show increased user engagement with recommended videos.
- Watch Time: An increase of +2.867% suggests users are finding the recommendations more engaging and watching for longer durations.
- Cold-Start Video Discovery: The significant increase in “Climbing4k” (+1.207%) indicates that M3CSR helps promote new, high-quality videos by effectively matching them to interested users.
- Coverage: The rise in coverage (+3.634%) implies a wider range of cold-start videos are being successfully surfaced to users, contributing to content diversity and platform growth.
Finally, I didn’t manage to catch the workshop VideoRecSys + LargeRecSys 2024, but there was an interesting presentation by Justin Basilico, who leads the ML and recommender systems efforts at Netflix. You can find the presentation here. In his presentation, he shared some of his learnings about building and operating recommender systems, making an analogy to raising a teenager. This presentation is a good collection of Netflix’s vision on how to operate a recommender system, with a few key learnings worth highlighting:
- Design a self-improving system using a contextual bandit approach. This involves continuous learning from user interactions.
- Personalization requires balancing accuracy, diversity, discovery, continuation, new and existing content, and scalability. Focusing on long-term member satisfaction is key to achieving this balance.
- Acknowledge that mistakes are inevitable and design systems for resilience, fast detection, and rapid recovery (apply Recsysops).
- Recognize the temporal dynamics of user interests and content consumption. Make models aware of time to capture short-term and long-term preferences.
- Prioritize user enjoyment over simple engagement metrics.
But at the end the final lesson is 😁

Closing notes
In RecSys, there’s always something new to learn, and we can see the rise of new trends (like LLMs—who could have expected that?). I really enjoyed the article A Pre-trained Zero-shot Sequential Recommendation Framework via Popularity Dynamics, which I found to be an innovative twist in sequence recommendation and cross-domain recommender systems. I’m really excited for next year and the conference in Prague.
Beyond this article, I enjoy discussing data, AI, and system design—how projects are built, where they succeed, and where they struggle.
If you want to exchange ideas, challenge assumptions, or talk about your own projects, feel free to reach out. I’m always open for a good conversation.






{kind=link}