
The past year was tumultuous, marked by team changes, reorganizations, and other stuff. It was also the year that I celebrated a decade of working in the data science field. During that time, I’ve worked for four companies across three countries (France, England, and Canada) and in various industries, starting in the energy sector and transitioning to the video game industry six and a half years ago.
Looking back on these 10 years, I’ve gathered some key learnings and experiences. I decided to summarize them in this article—so let’s dive in.
Beyond the Buzz: Classifying Emerging Technologies
Working as a data scientist across multiple industries for the past 10 years, I’ve been embedded in teams focused on innovation. This has allowed me to explore and share new tools and algorithms both internally and externally. To keep a cool head amidst the hype surrounding new companies, tools, frameworks, and algorithms, I’ve found it crucial to develop a classification system for all this new information.
Hype cycle and Technology radar
This section will concentrate on two established representations used for classification. The first is the Gartner Hype Cycle, which depicts how expectations for a technology evolve over time before it eventually reaches a plateau of productivity. The Hype Cycle’s characteristic peak in the middle illustrates how expectations can become inflated, only to decline as rapidly as they rose. A prime example is the latest Hype Cycle published by Gartner, which focuses on AI for 2024.

The key insight isn’t just the shape of the curve, but knowing where a technology stands on it over time. Gartner recently introduced a color code to estimate when technologies will reach the plateau of productivity.
But beyond the hype cycle, which many people use as a common reference, there is a second classification that I found interesting and perhaps less common: the Thoughtworks’ Technology Radar. I discovered it while reading a series of articles by LJ Miranda on MLOps tool classification.
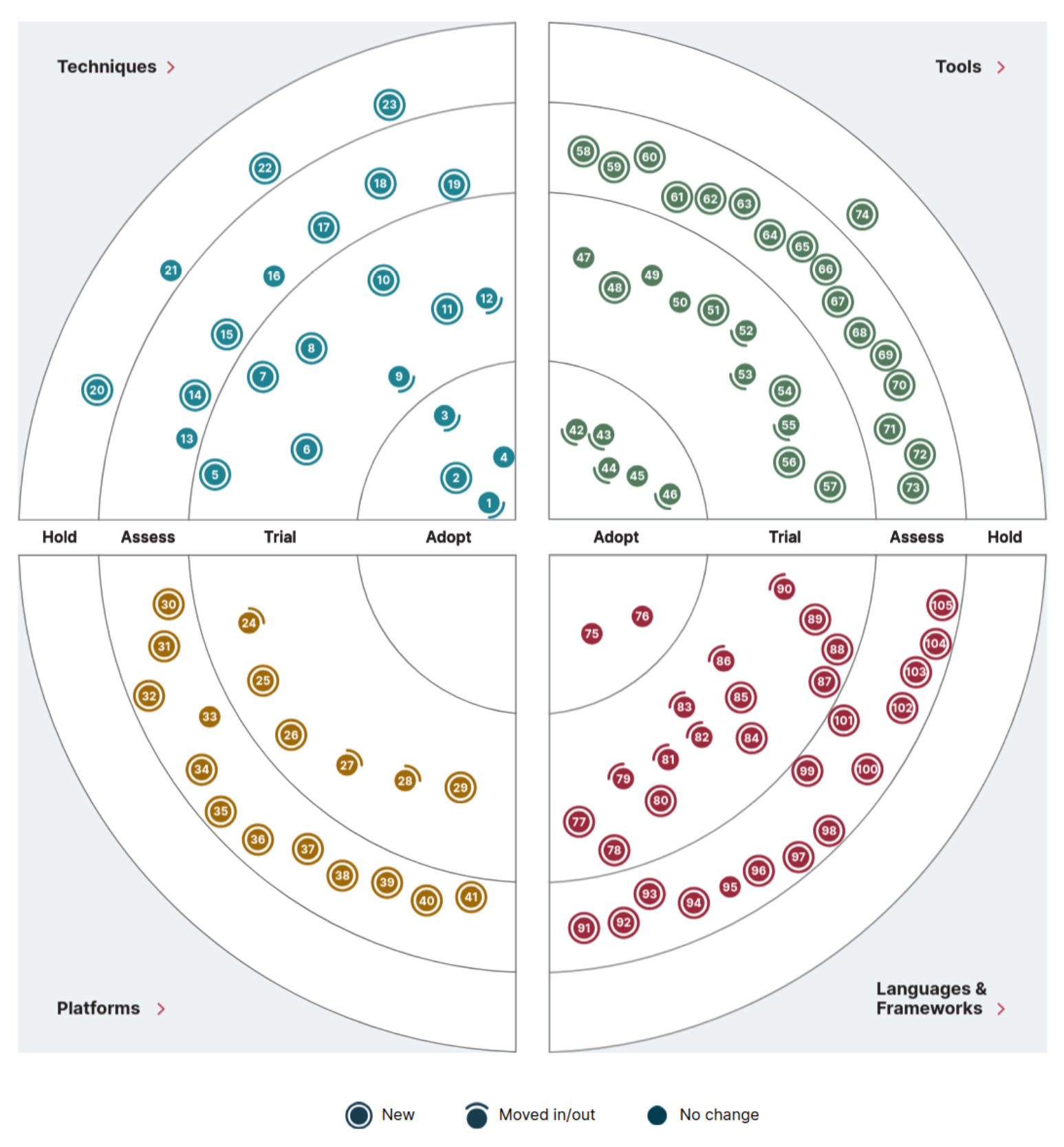
The concept is to divide the radar into quadrants, each representing a category of technologies (e.g., software, languages). Within each quadrant, technologies are positioned based on their recommended adoption status:
- Closer to the center signifies that the technology should be adopted or tried.
- Further from the center implies that the technology should be assessed or held.
This view is pretty good and LJ Miranda made a tweaked version in its article but it keeps the essence of the recommended adoption.
Ok, but besides the framework and visualization, what are my thoughts on all this data/AI hype
My take on the hype classification
At first, when I was writing this section, I wanted to build my framework that was kind of a mashup between the hype cycle and the radar.
In hindsight, I was probably reinventing the wheel, but after spending hours creating it in Procreate, I wanted to keep it. But still, behind all these frameworks, there is one question to try to answer:
When can this technology be useful and used for my business and not just be a flex?
A specific technology at a specific time can seem irrelevant. For example, deep learning architecture in the late 1980s was interesting but not applicable. However, systems using deep learning architecture are now part of our daily lives.
Categorizing technology by its production readiness is useful for product/project roadmap planning. For example, in 2020, a client for our ML platform insisted on using a deep learning model to build a recommender system, as Facebook was doing. However, after some exploration and testing, we determined that this was not a priority, as there was no evidence in the literature that this technique provided any advantage at that time. So it’s important to keep the head cool on this industry, and focus on what can bring value quickly (first rule of machine learning don’t use machine learning) but still keep an open mind for the future (80-20 rules basically)
But beyond the hype of the fields, let’s talk about organization.
Navigating Data Organization Challenges
Before joining Ubisoft, I was part of smaller teams that had varied assignments. These teams didn’t work on a traditional data stack; instead, they experimented and created their solutions to deliver their projects, and honestly it seems reasonable to do so but you could see a lot of overlap and duplication of work that could be avoided. However,I think that I joined Ubisoft at perfect timing as was able to witness how a large, non-data-focused but data-friendly company could structure its data strategy to be more efficient.
From a web to a mesh
In 2018, I became a member of Ubisoft’s DNA team, which focused on supporting game production by creating data tools like KPI dashboards, 3D visualizations, and analytic platforms. Other teams at Ubisoft also developed data tools for various departments, including marketing, HR, and legal. With over 15,000 employees worldwide, data needs were diverse.
After a few years, a centralized Data Office was established to consolidate data teams, prevent duplication, and optimize processes. In theory, this seemed like a good idea; however, in reality, centralization led to a misunderstanding of data consumption and desensitized departments to the actual cost of data utilization. For example, data practitioners like analysts were taken out of their department and assigned to the Data Office, which created a disconnect between the data work and the department (how much it costs, what it takes to get these numbers basically)
Over the past year, there has been a shift towards a more federated data strategy, rather than a complete rollback. In this model, a central data office provides governance, tools, and APIs to different areas of the company, with representatives from the data office ensuring their interests are considered, like in this schema.
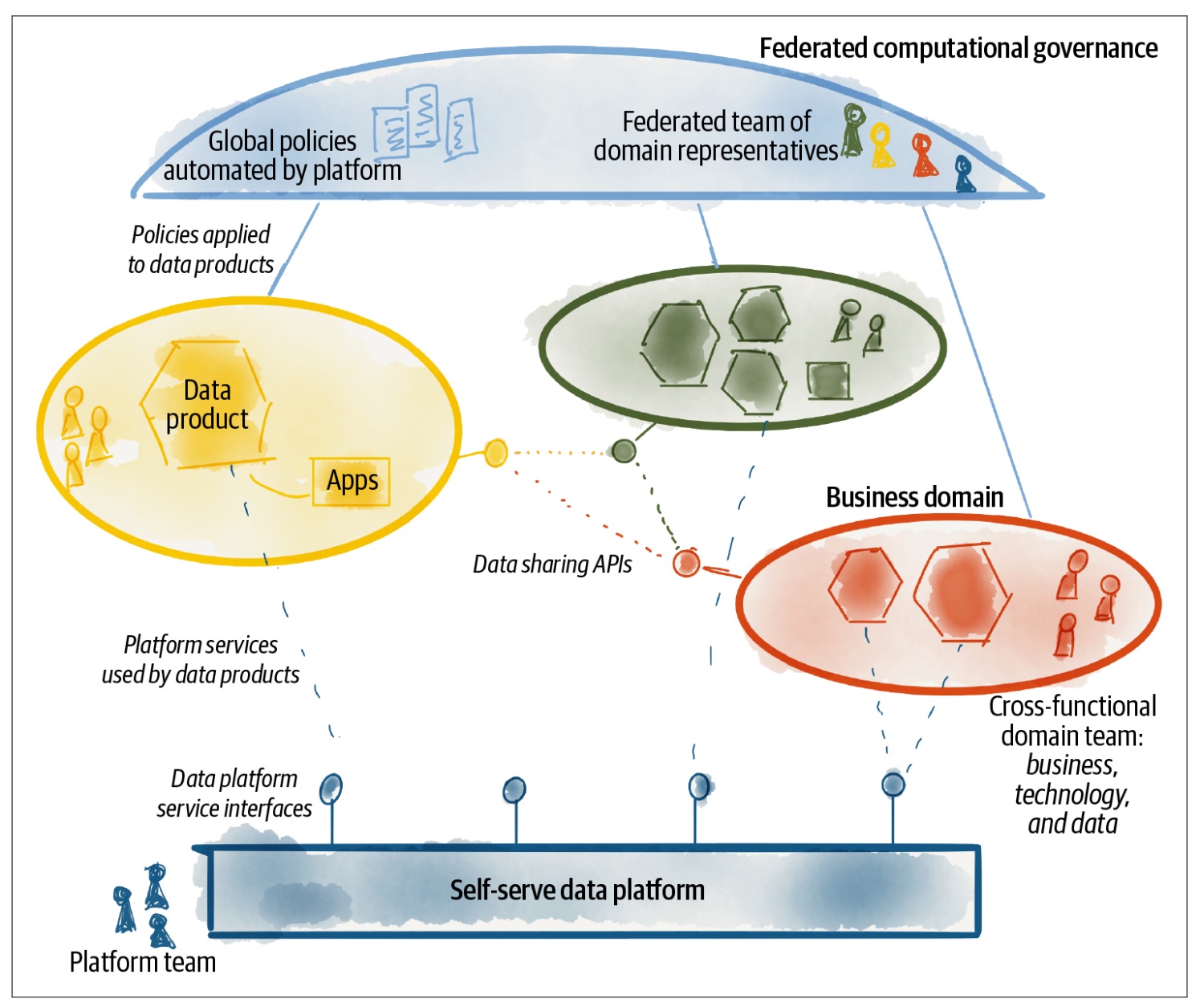
This concept is not new and draws inspiration from the data mesh concept, as detailed in Zhamak Dehghani’s book “Data Mesh: Delivering Data-Driven Value at Scale.” (recommended by our top management) where I took the previous figure. This organizational structure seems promising, but I still have some interrogation (that I guess only time will answer).
- What types of roles are needed to make this federation work? I’m seeing job titles like data strategist and data steward emerge. At my level, I don’t see how these roles would directly impact my work, but I’m assuming they would facilitate interactions between the domains in this federated model.
- What mechanisms can be put in place to prevent teams from going rogue? I haven’t finished reading the Data Mesh book, so perhaps it addresses this, but in my experience, there’s always something that teams will use to justify going rogue (usually some tech trend).
The ideal organizational structure for a data team within a company depends on the company’s size and current organization. In a company with 100 employees, a centralized data team might be appropriate. Finding the right balance is crucial but challenging. However, there is one pending question.
What about an AI organization?
How is AI fitting into all of that? To be honest, I’m starting to see some org charts with AI prefix titles like Generative AI Program Director, VP of AI Programs, or AI Program Manager, and I can’t stop thinking about that tweet from 2018 when I see AI in a job title 😁

The emergence of AI roles raises a few questions for me.
Should AI projects be under data office governance? A big yes, as AI is only a byproduct of data; like reporting, it seems normal that they follow similar rules and logic of federation across the company (with specific hardware policy, as training and serving models are very specific tasks).
Do you need a Chief AI Officer? Given the growing importance of AI applications in company strategy, and depending on the size of the company and its data/AI load, I believe that this role could be valuable.
What will be the tasks and mandate of a Chief AI Officer? Let me design a job posting for you
- Spearheading the internal AI initiatives as the primary coordinator, aligning AI projects with overarching business strategies and objectives.
- Overseeing AI Product Owners/Product Managers across all company divisions, ensuring cohesive product development and strategic alignment.
- Collaborating closely with the heads of Data, IT, and Security departments to deliver AI systems that are robust, scalable, and secure, while adhering to industry best practices and compliance standards.
- Communicating effectively with top-level management and technical leads across various business units to foster understanding and adoption of AI solutions, translating complex technical concepts into actionable business insights.
- Staying abreast of emerging trends and advancements in the AI landscape, identifying potential opportunities and threats, and adapting strategies accordingly.
- Allocating time equally between promoting and developing innovative AI solutions with high potential for success and deploying proven (section 1 plateau of productivity), reliable AI systems to address existing business challenges and dreaming a bit
But overall, as a TL;DR, I think this role is mainly responsible for coordinating and improving AI efficiency within the company. It should not have any developers directly under it. If I refer back to my hype visualization for representing technologies, there are different cones of discussion allowed for this role.

It should focus on working with developers to use and discuss production-ready or near-ready technologies that can deliver value while also selling a vision to top management (being the “hype guy”) but still highlighting what is in production.
In conclusion, I witnessed this transformation within a video game company, but it’s important to note that many companies are restructuring their approach to data/AI, Yves Caseau from Michelin and Michel Lutz from Total Energies are two valuable sources of insight into this trend, as they frequently share interesting perspectives on the topic of organization in big groups.
Now, let’s dig into the heart of my work, the projects and some learning around them.
Project lifecycle
Throughout my 10-year career, I’ve had the opportunity to work on a wide range of projects. These projects can be broadly categorized into two main types: Proof of Concept (PoC) projects, Minimum Viable Product (MVP or PoC++ with real data/user flow) and projects that have been successfully deployed into production (scaled version of an MVP).
I have been involved in numerous PoC projects, primarily during my time at CEA and EDF. My current role at Ubisoft has shifted my focus toward production projects, with a few PoC here and there (that are usually closer to MVP). I won’t go into too much detail about how I organize my projects, as it has changed a lot over the years, but I think I will write a few articles about it later. For now, I’ll focus on how projects that can be kickstart and general takeaways.
Hackathon
During my time at EDF and Ubisoft, I have been involved in numerous hackathons, both as a participant and as an organizer. This was a new experience for me, but I discovered hackathons as a great way to kickstart projects. Over time, I identified three distinct types.

Free-For-All Hackathons: These hackathons are primarily focused on team building and exploration, without specific objectives or production goals.
- Example: We hosted a hackathon for local data scientists using our ML platform. The goal was to explore AI projects that could be implemented on our platform, using available data. While many interesting ideas emerged, none have been implemented due to a lack of business traction.
- Pros: Freedom to explore and experiment
- Cons: Outcomes may not be actionable or lead to production projects.
Tech-First Hackathon: A collaborative hackathon with a greater number of “hardcore” programmers. The focus is on utilizing a specific technology to address one or more business needs or roadmap objectives.
- Example: Our ML platform team was exploring live prediction capabilities, including model serving and feature engineering. We partnered with a team experienced in streaming technologies like Kafka to experiment on possible flow to deliver live prediction features
- Pros:
- Explore new and interesting technologies
- Generate new business ideas
- Cons:
- Technical setup can be time-consuming
- Potentially less engaging for data scientists, as complex ML and data engineering may not be required initially
Business-First Hackathons: These hackathons, which I mostly participated in while at EDF, are divided into two main phases with an Ideation where business sponsors present ideas and developers from our team provide support on the technology that can be used (devices or software) to design multiple subjects for the second phase that is the hackathon on itself
- Example: One hackathon focused on supporting smart meter installers. During the ideation phase, we designed multiple projects, including a VR (360 video) simulator to stress test installers using Unity.
- Pros:
- Proper ideation
- Business-oriented and results in actionable outcomes.
- Cons:
- More preparation
- Less freedom, as subjects are defined in advance.
Hackathons can be an excellent way to jumpstart internal projects and generate new ideas within a company. While there are multiple ways to structure a hackathon, I’ve found that the business-first format tends to yield the best results. In this format, the problems or challenges to be addressed are defined upfront by the business side of the organization. This ensures that the solutions developed during the hackathon are directly aligned with the company’s strategic goals and have a clear path to implementation.
Now let’s discuss project management itself.
Project management
Beyond the technical side, successfully completing a project requires managing resources and time effectively. Here are a few key lessons I’ve learned.

Project managers: In 2018, I had mixed feelings about the necessity of project managers. While I had both good and bad experiences with them, I questioned their role as intermediaries between technical teams and clients.
However, at Ubisoft, I began to see the value of project managers in large organizations. They facilitated communication with clients, promoted our work within the company, and helped establish frameworks for new initiatives. This role is particularly effective when managing multiple projects and ensuring their quick launch. However, project managers are not solely responsible for these tasks; they collaborate with others (I mean people like me) to achieve these goals.
Learnings: Familiarity with project management methodologies (e.g. Agile, Scrum, Kanban) and tools (e.g. Jira, Asana) is essential for any data or AI practitioners to effectively manage their time and deliver projects on schedule (and work in good terms with project managers).I won’t go into too much detail about my experiences with his methodologies and tools, but here are some key takeaways.
- Split your work into tasks: Tasks should ideally be completed within a week, as this indicates that they can be broken down into smaller, more manageable tasks. My typical work breakdown involves tasks that can be completed within an hour (e.g., sending an email, updating documentation), a day, or a week.
- Document as much as possible: Documenting your system and experiments is a crucial, albeit less exciting, aspect of the job. For example, creating a one-page summary document for your client is essential after a few weeks of work on any PoC, MVP, or production project.
- Be a conditional optimist: When working with clients, you should be optimistic about your proposed timeline, but always include conditions that must be met to achieve that timeline. The availability of data is a common example of such a condition.
- Git and task: Linking merge requests and tasks is a good practice for segmenting work and maintaining traceability, which in turn documents the project development.
- Lifecycle: Planning a roadmap for any project is crucial, but it is equally important to consider the various aspects of decommissioning a project, which will be discussed in a later section.
Credibility in the data/AI industry beyond pure technological knowledge depends on understanding these methodologies and tools, as they are commonly encountered in the workplace and illustrate good planning capabilities
Standardization
During my initial 5 years at Ubisoft, I was embedded in a product team responsible for developing an ML platform. After deploying several recommender projects, a need rise for workflow standardization. Many elements were reusable across projects, making standardization valuable—but deciding how far to take it was a challenge.

In 2022 and early 2023, one of my main tasks was to simplify the use of our ML platform by contributing to our inner source code package to interact with the ML platform components. The developers had already established a framework to facilitate code packaging. We learned a lot from this standardization work.
- Determine your audience: Adapt the standardization to your audience
- Prepackage often used functions: Our primary focus revolved around the input and output interactions between the various platform components. This included everything from data storage interactions to our MLflow server and all the functions that were used daily.
- Be technology agnostic: The prepackaged code should abstract the platform’s components, allowing us to focus on the desired functionality rather than the underlying technology. I will provide specific examples in the next section.
- Build sample project: These code snippets provide a comprehensive illustration of how to utilize the platform’s pre-packaged functions from start to finish, serving as an ideal starting point.
- Don’t focus on the ML part: We were asked to package our ML code; however, this should be your last step. Most current open-source packages already provide a sufficient level of abstraction, and the right code snippet is sufficient to understand the logic of thr ML part of a project.
- Documentation as code: Linking documentation directly to the codebase is essential. Sphinx is a great tool for this in Python.
After establishing these standardization practices, questions inevitably arise regarding the promotion, maintenance, and evolution of these standards. In my view, data/AI offices should be responsible for managing these standards, but I have yet to see a concrete, long-term plan for achieving this (not an easy task)
Let’s switch now to a more concrete topic, the tech stack.
Don’t get attached to the stack
My tools and technologies have evolved naturally over time. From 2014 to 2018, I primarily worked on my local machine (Windows laptop, Raspberry Pi, or Macbook Pro), occasionally using the cloud for some applications. I didn’t have a dedicated machine learning stack during that time. In 2018, I began working on production projects at Ubisoft, where I started using the cloud more and working in distributed environments with Spark to handle ETL jobs, analysis, and machine learning pipelines. I also used GPU machines to explore deep learning-based systems and machine learning tools to simplify my workload during exploration and project deployment, as you might expect when you’re part of the ML platform team.
This progression shows how the field has changed and matured over the past 10 years but it has taught me that it’s important not to get too attached to a specific tech stack, which opens up several points for discussion.
The Build VS Buy paradox: my ML platform experience
As a member of a team building an ML platform, I have been in a unique position to experience the common build-versus-buy dilemma that companies face today. ![]

(merlin holding a merlan in style of michelangelo)
The ML platform product, Merlin, started in 2018. Its development was driven by internal needs at Ubisoft, which was beginning to see makeshift solutions to operate machine learning pipelines on the analytic platform. The project drew some inspiration from the Uber Michelangelo ML platform, which detailed the concept and advantages of having an ML platform.
By 2019-2020, the platform began taking shape, integrating into Ubisoft’s data and online ecosystems, it supported its first clients and performed well. At that time, open-source ML tools were readily available, and cloud providers were not as focused on ML solutions as they are today, so building a custom solution on top of AWS, our main cloud provider for this part of the group, was logical.
The needs of our clients and the company’s vision continued to drive the evolution of our ML platform beyond 2020. This occurred despite the availability of new MLOps solutions and versions from cloud providers, such as the 2020 edition of AWS SageMaker, and third-party layers like Databricks, which raised the bar for ML platforms (we had started to do a benhcmark at this time). In mid-2023, in the post-COVID era, the company entered a cost optimization phase, which included team mergers and a restructuring of the entire data organization. The data platform strategy was also reevaluated, shifting from a “build” to a “buy” model to support the company’s analytics and machine learning needs more effectively. Consequently, we are currently migrating to Databricks on Azure.
1000000$ question: Should I build or should I buy?
Given my experience, what are my thoughts on the evolution of the ML platform?
- From an end-user perspective, the platform initially made sense and was a valuable addition to the data/AI tool portfolio. But as standards evolved rapidly, keeping up with limited human resources became difficult.
- From a former ML platform team member, this new setup can feel less interesting and challenging. While it may be difficult to accept, the role primarily involves the integration of the tool (another kind of challenge as the management will say)

However, I think that more generally, the decision to go in one direction or another can be determined by asking a very simple question:
- How much can you wait to deploy new features with the allocated resources?
- What’s your cost of maintenance of the product after deployment?
Companies often claims one strategy is better than the other one like for example David Heinemeier Hansson has shared his experiences to quit cloud-based infrastructure, or the Databricks website features customer stories highlighting the benefits of their product. Ultimately, the final decision comes down to time, money, and higher-up decisions but I would like also to highlight a few things that should be weighted in your decision:
- When deciding whether to build or buy solutions, it’s important to consider your team’s experience and interests. However, be mindful of potential conflicts of interest that might influence their decision. Additionally, assess your team’s overall willingness to experiment with new solutions.
- The robustness of build-and-buy solutions depends on making clear assumptions about potential packages or vendors. Building proper benchmarks is essential. In 2020, we performed this exercise to evaluate potential vendors for our ML platform.
Beyond the decision to build or buy, there is something important that starts with an M that people forgot to present you.
You know there is always migration
This isn’t my quote, but a former data VP once said it—and it’s absolutely true. To illustrate, here’s a slide from my DEML Summit 2024 talk.
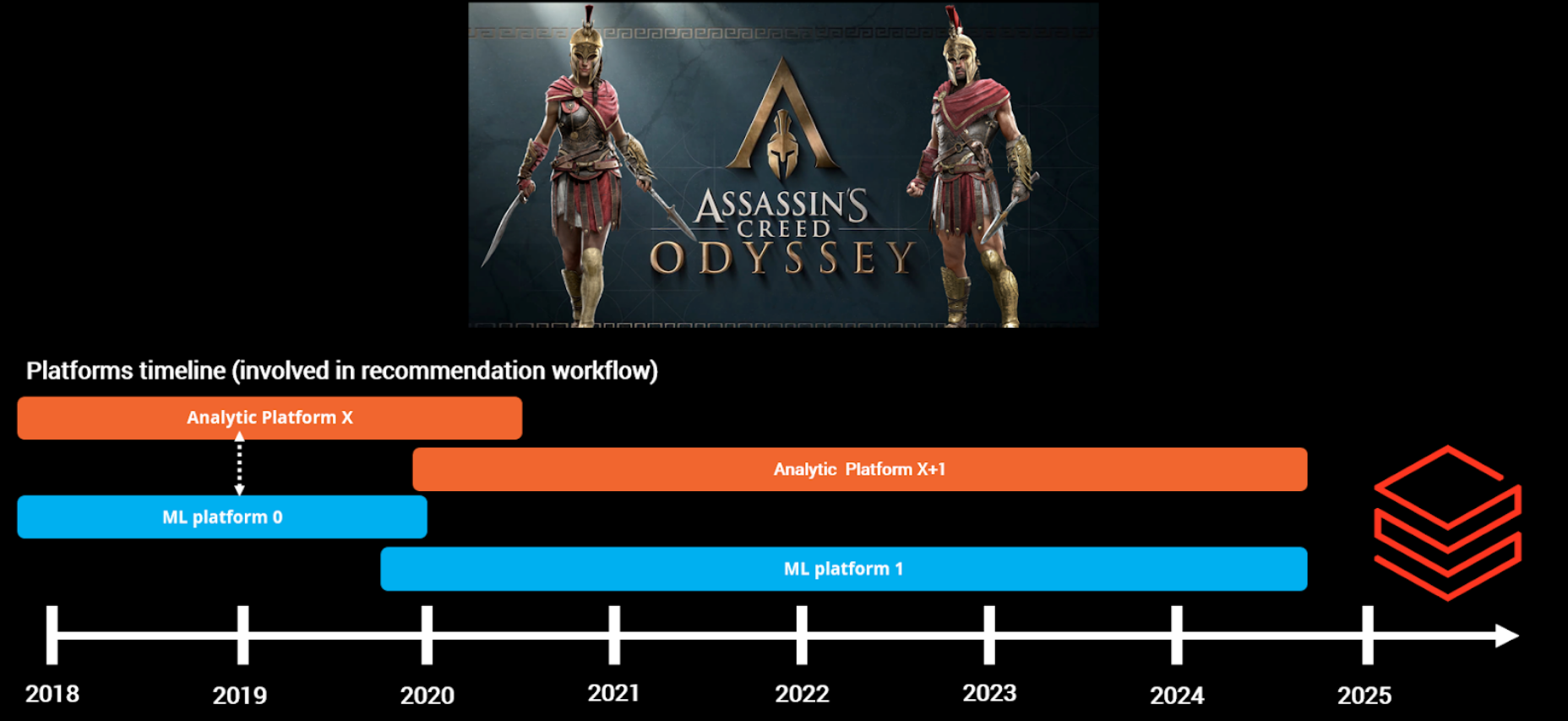
The analytic and ML side has seen a lot of migration in the past six years, typically following a 2-5 year cycle as it seems to be an expected norm in the industry (no proper source). Although tech and cost improvements generally justify these migrations, they can still be risky. However, in my experience as an end user, they have usually been successful.
While those in charge may have more interesting stories to tell about the migration process, from my perspective as I help people onboard new user on the ML platform and migrate a few of my projects on the new platforms, there are a few points that can be relevant to have in mind:
- Credit to the existing foundation: Acknowledge the work that has already been done, even if it wasn’t perfect.
- Sandbox: Develop an environment where users can experiment with a trial version of the new tool using sample data.
- Test project: Ensure to have a test project to try out the entire process, in our case, we used our game that is not too small but not too big also
- Project’s value: Assess the value of migrating certain projects by determining if they are still relevant ( will elaborate later)
- Onboarding meetings: Brief, one-hour meetings spread on 1 or 2 weeks are effective for introducing and onboarding new users to specific aspects of the system.
- Communication channels: Establish a direct communication channel for questions, Not something shared across people but dedicated to a specific project
- Local migration first: Start with local colleagues first—it’s always easier to support people in the same time zone before tackling global migrations.
In addition to these insights, there’s something that can simplify the integration of a new tool into your tech stack.
Build or buy who cares , wrap it
From my perspective, being able to create software that integrates with existing company tools is a smart strategy. As illustrated by my build-versus-buy paradox, circumstances can shift and it can happen quickly However, if this software wrapper prioritizes functionality over the specific cloud provider or tool it interacts with, it can simplify testing and future transitions. Here’s a quick example to demonstrate this point.
During my time on the ML platform team, I worked on an ML tracking module for the ML platform python wrapper. This solution was designed to be compatible with the technical requirements of multiple teams utilizing various tools in the company , like MLflow and ClearML. The primary focus of the module was on the functionality of an ML tracking solution as most of the tool have similar hierarchy like tracking server , artifact metrics and so on, there is a screenshot of the documentation.
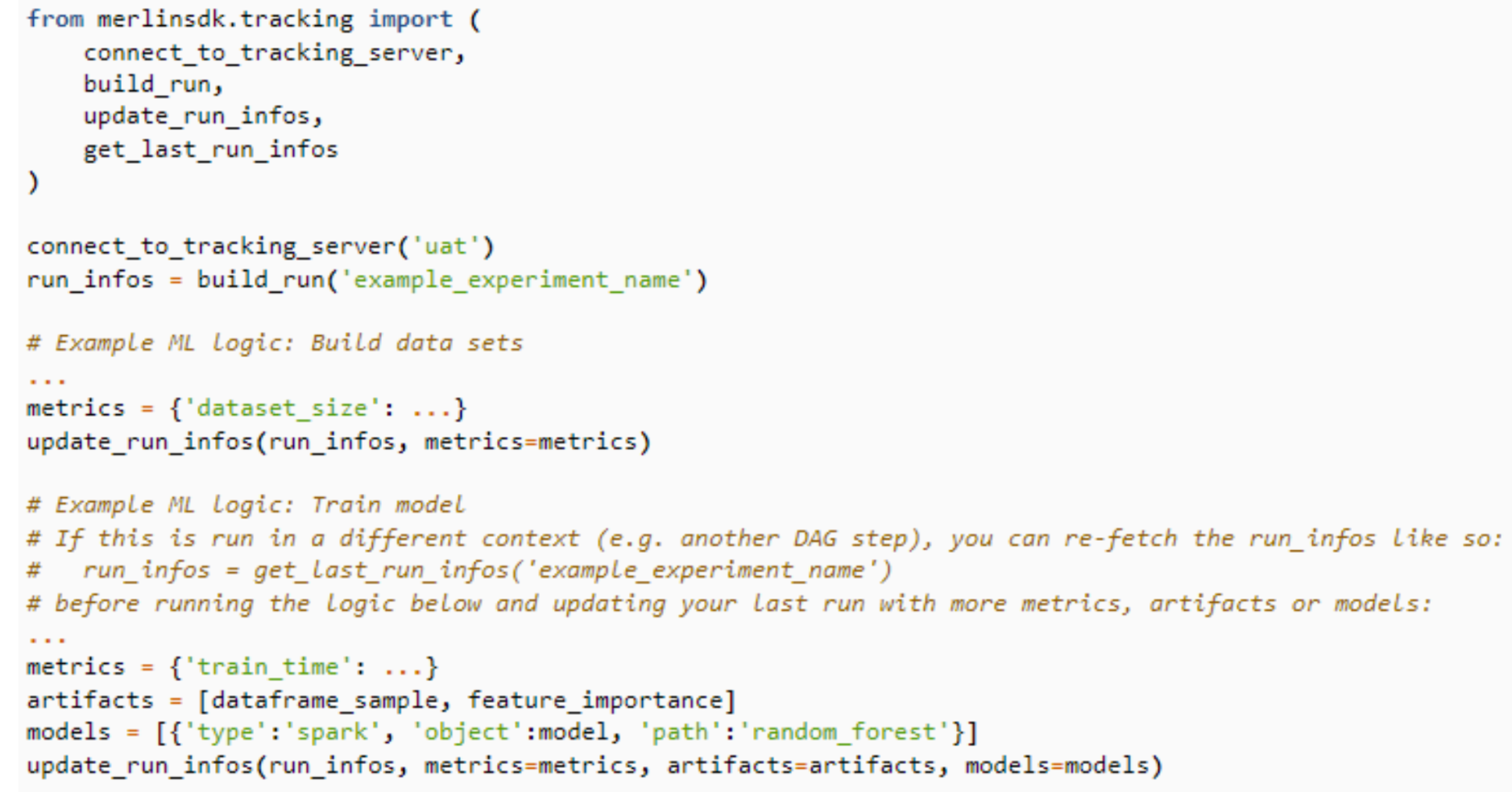
While constructing this wrapper was relatively straightforward for me, developing other functionalities that are more closely integrated with the data for example can be considerably more challenging as you need to find the right format for this wrapper to be futurproof as possible.
That’s it for my tech stack experience. Working with data and AI isn’t free, and financial decisions should be considered at the project level. Let’s now look at how decisions are made at my level to either help a project evolve or decide to stop it.
Money, money, money, Must be funny, In the rich man’s world
As technology rapidly evolves and costs can escalate quickly, questions around cost and return on investment (RoI) become increasingly critical when working on projects, so there is different aspect about this question of RoI.
Continuous evaluation
I deployed production projects at Ubisoft, primarily in-game recommender systems. These projects had to adapt to changing platforms and are still running today. However, it is important to evaluate the continued relevance of these systems over time and to do so your best friend is AB testing.
I believe it’s crucial to always have a control group that doesn’t receive output from your system (in this instance, the recommender system). This group should instead receive default fallbacks, either from your application client (a default list) or from the system itself. I’ve written a short article about this if you’re interested in learning more about my perspective on fallbacks for recommender systems.
When doing an AB test something that is crucial is to identify your key performance indicators (KPIs) that you would like ot use to compare the populations.While your KPIs should mainly be linked to spending or finances, which can then be compared to your operating costs (including infrastructure and human resources), it’s also practical to track some non-monetary metrics. For instance, while most of my projects can be tied to spending, I also track more general engagement metrics, such as clicks and visits as it can help to design UI/UX decision..
The ML platform feature introduced in early 2023 to analyze individual project costs now allows us to properly assess project RoI and answer the question of project relevance raised earlier. We conducted a 3-month A/B test to compare the impact of personalized recommendations (using a classic ranker) versus a fallback solution featuring the most popular items from the past 7 days, in different projects of my portfolio and there is the overall comparison in a graph.
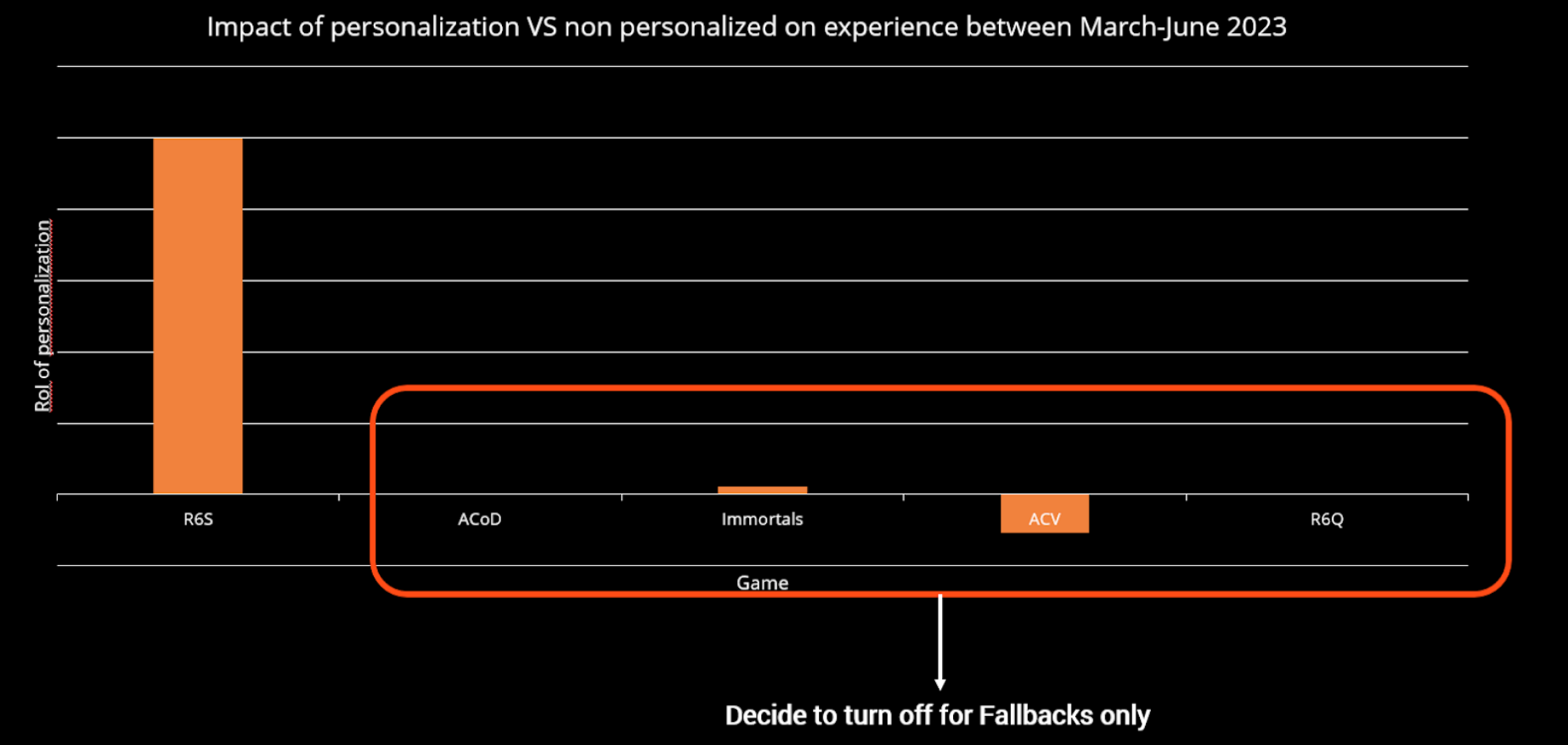
The outcome of projects can vary significantly as you can see; some projects prove to be highly valuable, while others may only break even, and for some may even need to be terminated. The ability to track costs is essential when deploying any data or AI applications.
But there is always the pending questions, how much return should justify to continue in a specific direction.
How much return is enough ?
Returning to the previous section, we used a simple rule to determine which projects should be cut: any project that didn’t generate twice its cost was switch in fallback mode
Where did this number come from? We made an educated guess. 🙂 (or as in France we say, it came from our hat)

I wasn’t sure if I had more to add, but a few months ago, I came across an IDC study (sponsored by Microsoft) that was circulating at work. Produced in 2023, the study surveyed over 2,000 “AI decision makers” about their experiences in building AI projects. Here are the key findings:
- The average return on investment in AI is 3.5 dollars for 1 dollar invested. Notably, the top 5% of companies investing in AI saw an 8 dollars return for every dollar invested.
- AI deployments are happening with the following pace, with 92% taking a year or less to implement, and 40% of companies deploying AI in less than 6 months.
- The average return on investment begins to appear within the first 14 months.
For me this is THE key takeaway: AI projects generate an average $3.5 return for every $1 invested.. However, there are some caveats:
- We lack the standard deviation for the results. Without it, an average alone doesn’t provide a complete picture.
- We don’t know the type of AI applications being analyzed. For instance, the reported deployment time seems extremely long compared to what we typically experience when deploying an project (at least for the AI component itself).
While 3.5x is slightly higher than our current factor of 2, it’s not an extreme difference. That said, using such a multiplier should be done with caution. It’s easy to quantify direct financial returns (e.g., $1 spent vs. $1 earned), but indirect impacts (such as a reporting solution used to take decisions) are harder to measure. A proper methodology or benchmarking approach should be established before starting a project.
To conclude this section I want to highlight also a reality in an AI project.
You do not need a bigger AI boat yet
I stole and tweak a title’s article of Jacopo Tagliabue, that was more around the tech stack to operate recommender system in production , but I found that it can help to define this section.
In the AI field, new models with improved performance are constantly being released. While it’s true that these advancements can quickly render existing models obsolete, the reality is that the performance gains are becoming increasingly marginal. Meanwhile, the costs associated with training and serving these models are growing exponentially.
To support this statement I will refer myself to an article of Gael Varoquaux, Alexandra Sasha Luccioni, and Meredith Whittaker of last year called “The Hype, Sustainability, and the Price of the Bigger-is-Better Paradigm in AI.” The article compares different element of models from training time and model size for example

inference cost and energy consumption

The methodology behind these figures could be questioned I guess, but they still highlight that we’re reaching a performance limit. If we only focus on new developments, the return on investment of projects will decrease due to higher running costs for marginal gain (but it needs to be measure as at some point the model can be more performant to run).
Therefore, data scientists and machine learning engineers should be questioned about the overall benefit and value of any requests for additional infrastructure and resources, to run new models for a specific project.
Let’s stop to discuss about money but more around the human factor in all of that.
Human factor
The data and AI fields tend to attract introverts, so the human touch may not be an instinctive element in a work experience but trust me this is essential.
Disclaimers:
- The following section will be in bullet point format and reflects only my personal experiences working for these companies.
- Apologies in advance for the upcoming Office references in the illustration – I’m currently rewatching it.
Management

In my ten years as a data scientist, I’ve never had a formal management role—aside from mentoring interns and onboarding new team members. And honestly, I’m fine with that. I believe that managing people is a unique skill, especially with the changes brought about by the COVID pandemic and the shift to remote/hybrid/office work, which we may or may not like.
My diverse professional experiences have exposed me to varying management styles, which have given me valuable insights from the perspective of a subordinate:
- 1:1 : Regular discussions with your manager are crucial for your growth. These one-on-one meetings should be dedicated to your development, so come prepared. The format can vary (e.g., 30 minutes bi-weekly, 45 minutes weekly, in-person or remote) but ensure they are focused and valuable. Avoid distractions; this is your time to grow.
- Accessible management : It’s beneficial to have impromptu discussions with upper management. I’ve found that my managers until +2 level are accessible in every company I’ve worked for, so taking the opportunity to discuss with them is always a good idea.
- Project != Human : Project managers and people managers require different skill sets; you cannot manage people in the same way you manage a project.
- 360 feedback: The 360 feedback process at Ubisoft is really good. It provided an opportunity to evaluate the past year and plan for the future, as well as assess colleagues and managers. ,
- Sanity check: Regularly check that you have a clear roadmap and question where you are going (constructively) if you don’t.
- Direction’s update: Biweekly updates and quarterly status reports from upper management are a good way to stay informed on the direction of the group (I hate when the top management is silent, it’s the worth)
- Bad luck in reorg: If you end up with a manager who doesn’t have a clear plan for you (possibly due to a reorganization), it’s crucial to be mindful of all the previously mentioned points.
I believe I will eventually become a manager, but I’m not in a hurry. When the time comes, I will definitely use online resources such as Benjamin Rogojan’s GitHub repository, which contains a wealth of compiled content on the topic.
However, beyond simply being managed, I worked for large, French corporations with over 10,000 employees globally. Consequently, it’s crucial to consider the human factor not only on an individual level but also from a broader group perspective.
Be part of a group

Interaction within a group can occur at various levels, such as within teams or divisions. Despite these different levels, overall group behavior should remain consistent. Here are a few key takeaways:
- Be kind: Provide feedback in a way that you would like to receive it, you are going to do evaluations for you or your peers, so let’s be constructive
- Sharing is caring: Share your work and knowledge! Don’t let your contributions go unnoticed!
- Knowledge-sharing groups: It is essential to join and be active in reading clubs or other knowledge-sharing groups in your company to foster internal exchange and collaboration.
- Tailored message: Adapt your communication to your audience. You will collaborate with technical experts (DS/MLE) and other programmers, as well as less technical, more business-oriented stakeholders. Always adapt your presentation style and keep things as straightforward as possible.
- Be an ambassador for your company: Always look for opportunities to showcase your work externally. While it may seem daunting, most large companies have a process to approve external presentations, and the restrictions are often less complicated than you might think. I also involved myself in meetup organization a great way to gain visibility,
- Team building activities and events: I know that sometime it could be difficult but these opportunities are great for networking and building relationships that could benefit future projects.
- Be the stand-up guy: Taking on not sexy tasks demonstrates reliability, teamwork, and dedication to a larger goal.
- Be a pastry chef: People like to eat homemade pastries trust me
Alight I guess it was the last section about work, and let’s discuss free time now.
Beyond the 9 to 5
This next section might be a bit controversial, at least it was a sensitive subject for some of my colleagues. It contains some suggestions for after work activities (but still related to data and AI)
Coding Side projects
Since graduation, I’ve spent part of my free time on personal projects. At first, I focused on skill development to boost my job prospects in 2014. Although I had a basic understanding of Scilab and Matlab, I prioritized learning Python at the beginning of my job search due to its industry demand

Continuous learning is key to growth, and side projects can help bridge the gap between what you learn on the job and what you need to know. They allow you to learn at your own pace, without the pressure of extra work hours. It’s important to document your progress, focusing not just on the code, but on the overall project.
I understand that no one wants to do extra work in their free time—it can feel like more work. However, I believe side projects contribute to personal growth and can even enhance your daily tasks. Ultimately, you’re working for yourself, at your own pace.
The ideal side project should align with your personal interests and teach you new skills. Avoid working on basic projects that are commonly found in developer portfolios or data science courses. For example recently I work in some projects that I connect to my interest for the video game Marvel Snap (1,2) or finding good movies to watch (1,2). Most of the time also you will have also to build a data pipeline to collect some data so it’s also a good practice in general.
Finally participating in Kaggle competitions and managing datasets can be a valuable way to develop new skills, even though they may not be representative of most work done by data scientists and machine learning engineers. Engaging with active communities like Kaggle can provide valuable learning experiences.
Build an online and local presence
The recent emergence of content creators within the data and AI domain is evident on platforms like LinkedIn and YouTube. Many professionals in my field are becoming increasingly visible, contributing to this growing trend so creating an online presence is a good asset.

I mainly use my blog and social networks (e.g., LinkedIn, Reddit, and more recently, BlueSky) to maintain an online presence.
Whilesocial networks are used to keep up with trends, the focus of my work is on my blog, which I started at the suggestion of a former EDF colleague in the UK (coucou Alex Nicol). My blog is where I share some of my side projects and industry insights, and it’s easily deployed with the Jekyll framework.
I don’t often chase trends or buzz online (no salary or [technology name placeholder] is dead post for me). Instead, I focus on addressing questions or thoughts I’ve had previously (write for your past self). For instance, I wrote an article on matrix factorization because it’s a recurring topic in my work, and I wish I had such a resource when I first started working on recommender systems.
I started to engage with local communities at Montreal by getting involved with various meetup groups two years ago. Establishing a local presence has been a goal of mine, and I believe engaging with my local tech community will be valuable in the long run.
What’s next?
In 2013, I never would have guessed that I’d be working in data and AI for Ubisoft ten years later. My current position as a data scientist involves a mix of software, data engineering, data analysis, machine learning, and project management. I appreciate the variety of my work and the chance to apply my skills in different areas and industries.
I truly enjoy designing and delivering complete data/AI systems and taking responsibility for their evolution. I find working on personalization features particularly exciting, especially considering recent advancements in this area. For example,my French colleagues’ research on creating intelligent characters with LLMs or Spotify’s work on blending personalization and generative AI, demonstrate that it’s a great time to be working in the AI industry.
And what’s my next 10-year plan? Good timing is that it was evaluation time at work a few weeks ago so there is my section how do you picture yourself in the future ? Very broad overview of my 10 years’ career plan
- Short-term (1-3y): Continue to be hands-on data scientist MLE to deliver data and ML product
- Mid-term (3-7y): Lead technical team to operate ML (and data) product
- Long-term(7-10y): Becoming some kind of head of, director, CXO, VP around data and AI
But if we focus more on the short term, there are the main tasks that i will like doing in my day-to-day job
- Partner with Data, Design, Product Management, Production, and Engineering to explore AI opportunities to transform game production.
- Design and develop data/AI systems to improve user experience.
- Partner with engineers to deploy solutions.
- Partner closely with Design to innovate and integrate data/AI solutions to augment the application’s design workflow.
- Research and prototype AI technologies to push the boundaries
- Level up the data/AI literacy of the company.
- Contribute as a key member in determining the vision and strategy for data/AI.
Beyond the serious tasks listed above and what I am currently doing, I may explore side hustles like consulting or teaching as I think I am starting to have relevant experience worth sharing beyond my 9 to 5 (I started to give a few talks for some mlops training). I also thinking to create YouTube/Twitch content based on my side projects; I’m inspired by Andrej Karpathy’s work and have already started creating AI-generated podcasts from a few articles on Spotify #TheOddDataCast, so will see how it goes.
I hope you found this interesting and informative. I know I covered a lot, and it may not have been perfectly clear. This will likely trigger some additional content in the future, so stay tuned !
Beyond this article, I enjoy discussing data, AI, and system design—how projects are built, where they succeed, and where they struggle.
If you want to exchange ideas, challenge assumptions, or talk about your own projects, feel free to reach out. I’m always open for a good conversation.




{kind=link}