
Construire un tableau de bord avec Dash (plotly), AWS et Heroku
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Vous pouvez trouver le modèle pour ce tableau de bord dans ce dépôt Github.
Bonjour, dans cet article je vais expliquer le processus que j’ai suivi pour créer un tableau de bord qui affichait certaines informations personnelles. Pour réaliser ce projet, j’ai décidé d’utiliser Dash, un framework Python qui a été développé par Plotly, une entreprise canadienne qui développe la bibliothèque Plotly pour faire de la visualisation de données interactive.
Dans cet article, je vais expliquer :
- Les données impliquées
- Le backend de ce projet (et quelques conseils pour créer le vôtre)
- Le tableau de bord, son déploiement et ses composants
Introduction sur les données
Dans notre vie quotidienne, nous générons beaucoup de données et en tant que data scientist, j’aime jouer avec les données. Dans mon cas, j’ai des appareils intelligents comme une balance intelligente ou un bracelet intelligent que j’utilise tous les jours, et j’ai des applications pour surveiller certains aspects de ma vie comme Strava. Dans ce contexte, je suis intéressé par les sources de données suivantes :
- mes données de balance intelligente des appareils Nokia
- mes séances de course sur Strava
- mes exercices de crossfit
Pour les deux premières sources de données, j’ai une application pour suivre l’évolution de différentes métriques
Donc c’est génial, mais un service/appareil = une application, ce n’est pas très efficace pour faire un suivi rapide de ce qui s’est passé. Mais qui dit application dit API potentielle pour les développeurs et dans ce cas il y en a une (Nokia et Strava).
La dernière source de données est plus une source de données “à l’ancienne” car c’est simplement une feuille de calcul Google que je remplis chaque semaine avec les différents exercices que j’ai complétés pendant mes séances de crossfit. J’ai trouvé que c’était un bon moyen efficace de garder une trace de ce que je fais à la box et de voir les progrès. Il y a une API qui m’offre la possibilité d’accéder à cette source de données.
Donc toutes les données sont disponibles pour mon projet.
Voyons maintenant la structure du backend qui exposera les données pour le tableau de bord.
Description du backend
Pour ce projet, le backend est hébergé sur Amazon Web Services. Il y a une illustration du backend du projet.
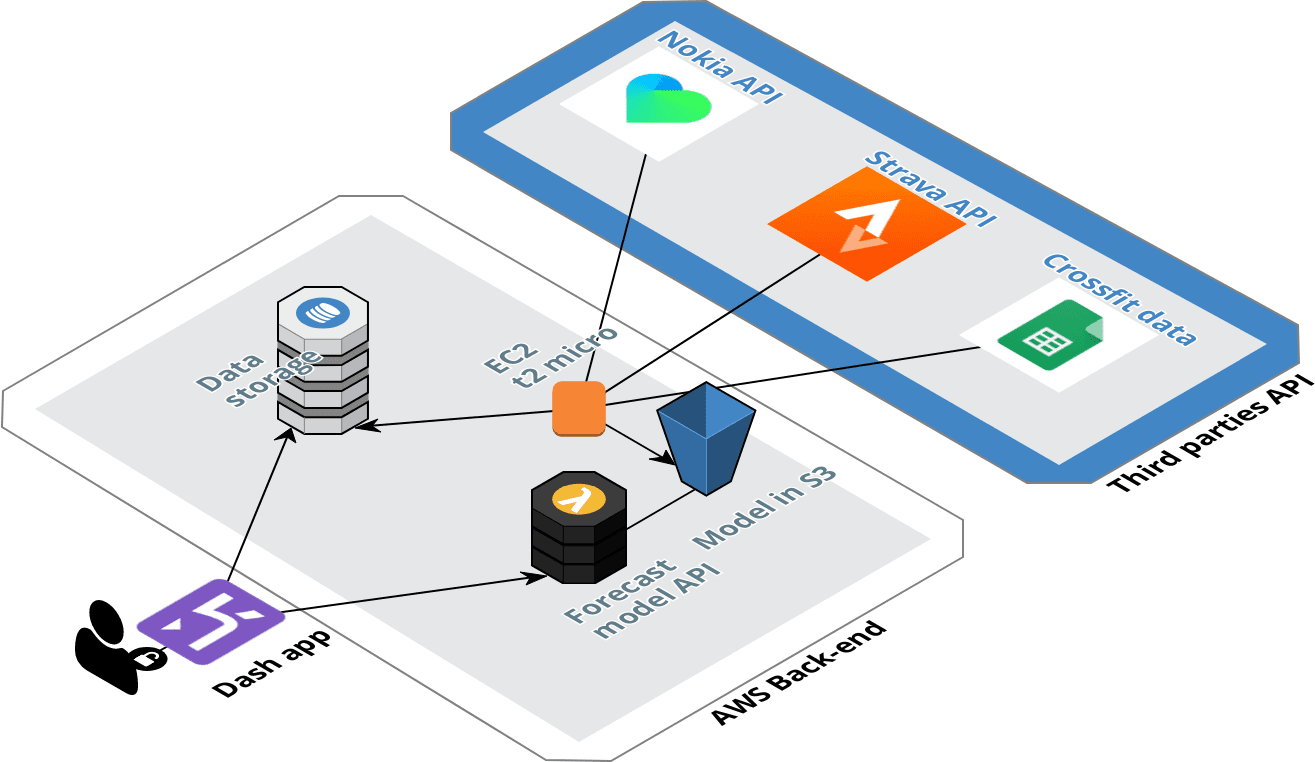
Structure du backend
Ce backend est structuré autour de deux éléments, le pipeline de données pour la collecte de données des différentes API, et l’API qui offrira les possibilités d’obtenir une prévision du poids et du ratio de graisse.
Construction du pipeline de données
Pour la collecte des données, le pipeline est hébergé dans Amazon Web Services. J’ai une instance EC2 (celle du niveau gratuit AWS) qui collecte périodiquement (toutes les 3 heures) les nouvelles données qui ont été poussées vers les différentes sources. Les données collectées sont nettoyées et envoyées à 3 tables DynamoDB différentes.
Le pipeline est très simple. Pour la configuration de la table DynamoDB, j’ai configuré une très petite capacité d’écriture de 2 unités, mais pour la lecture, j’ai décidé d’utiliser la fonction d’auto-scaling pour définir une capacité de lecture dynamique entre 10 et 50 unités en fonction du trafic.
Déploiement d’un modèle de prévision
AVERTISSEMENT : Ce n’est pas un modèle super efficace, mais au moins il existe
Le modèle est très simple mais pas très efficace. J’ai actuellement un modèle pour le poids et un autre pour le ratio de graisse.
C’est un simple modèle KNN dans chaque cas qui prend les entrées suivantes :
- la distance parcourue pendant la semaine
- le temps de course pendant la semaine
- le nombre de séances de crossfit
- le poids moyen porté pendant les exercices de crossfit (avec poids)
Le modèle prédira la variation hebdomadaire du poids et du ratio de graisse.
Le modèle sera mis à jour chaque semaine et envoyé vers un bucket S3. Pour accéder au modèle directement depuis le tableau de bord, j’ai créé une API avec Flask que j’ai déployée dans une Lambda avec le package Zappa que j’ai utilisé pour mon article sur le chatbot messenger.
Collecte de données
Comme je l’ai dit précédemment, il y a trois API à connecter à notre backend :
- API Nokia
- API Strava
- API Google drive
Examinons chaque source de données.
API Nokia
Avec cette API, j’ai commencé à collecter les données depuis février 2017. J’ai mon bracelet intelligent depuis juillet 2014 et ma balance intelligente depuis novembre 2014 et j’adore ces appareils. Leur design est agréable et l’application est bonne. J’espère que toutes les rumeurs sur Nokia arrêtant cette branche sont fausses.
Appareils Nokia (de marque withings mais c’est la même chose maintenant)
J’ai créé un script qui appelait l’API avec des requêtes GET (super long en termes de longueur). Honnêtement, je pense que l’API de Nokia est l’API la plus technique que j’ai utilisée jusqu’à présent (en comparaison avec Netatmo qui est pour moi l’API la plus facile à utiliser) mais au moins elle fonctionnait pendant l’année dernière.
Pour ce projet, j’ai essayé de faire quelques ajustements et j’ai littéralement tout cassé, alors j’ai décidé d’utiliser ce dépôt GitHub pour gérer la connexion avec l’API et ça fonctionne très bien !
API Strava
J’utilise Strava depuis septembre 2016, j’étais un utilisateur de Runkeeper et Runstatic avant, mais j’ai décidé de changer quand je suis arrivé au Royaume-Uni en 2017.
Honnêtement, l’API de Strava est super facile à utiliser, créez simplement une application, obtenez votre jeton d’accès et faites des requêtes GET pour obtenir vos activités passées.
Données Crossfit (API Google drive)
Je pratique le crossfit depuis août 2017. Comme je l’ai dit précédemment, je surveille mes entraînements dans une feuille de calcul sur Google Sheets.
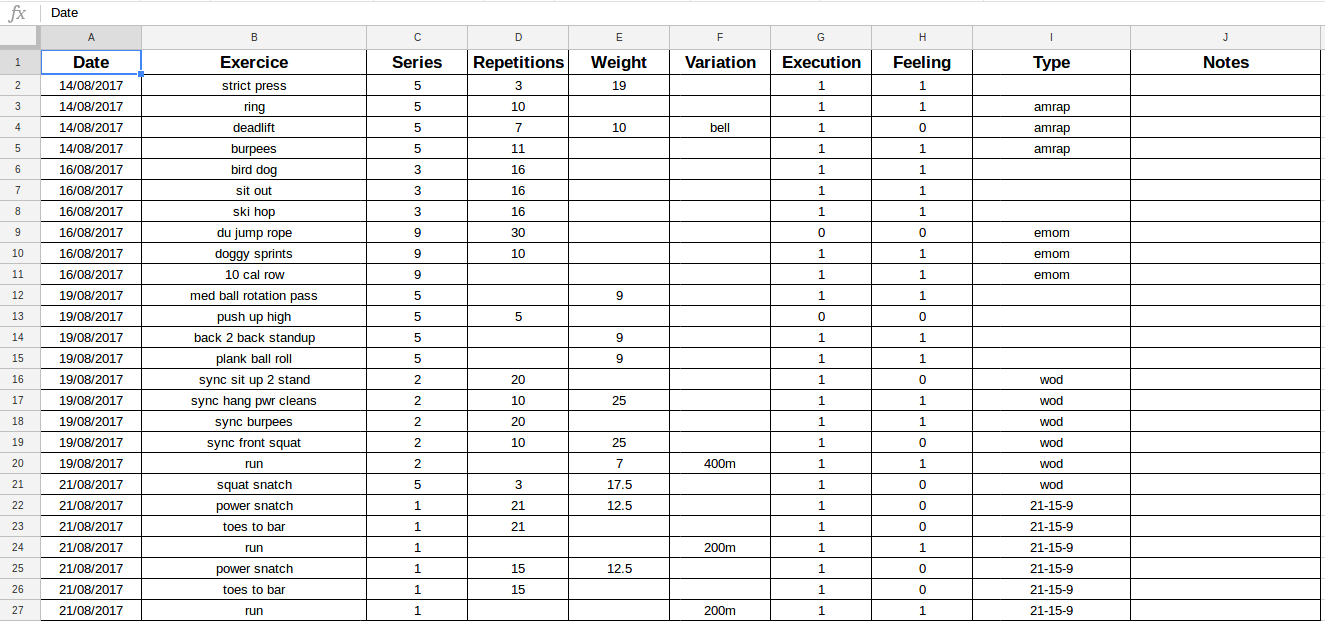
Capture de ma feuille de calcul Google
C’est une façon de faire à l’ancienne, mais je l’ai trouvée plus efficace qu’une application pour collecter les données.
J’utilise l’API Google Drive et ce tutoriel réalisé par Twilio pour configurer un script Python qui collectera les données. Une autre façon de le faire est d’utiliser Sheetsu. Comme j’ai des crédits Google, j’ai décidé de ne pas utiliser ce service (je l’ai utilisé dans le passé pour une compétence Alexa et c’est génial).
Analyses
Données de poids
Comme je l’ai dit précédemment, pour cette source de données, je vais me concentrer sur les données de la balance, les paramètres sont le poids et le ratio de graisse.
Dans la figure suivante, il y a la représentation des données historiques de mon poids pour l’année dernière.
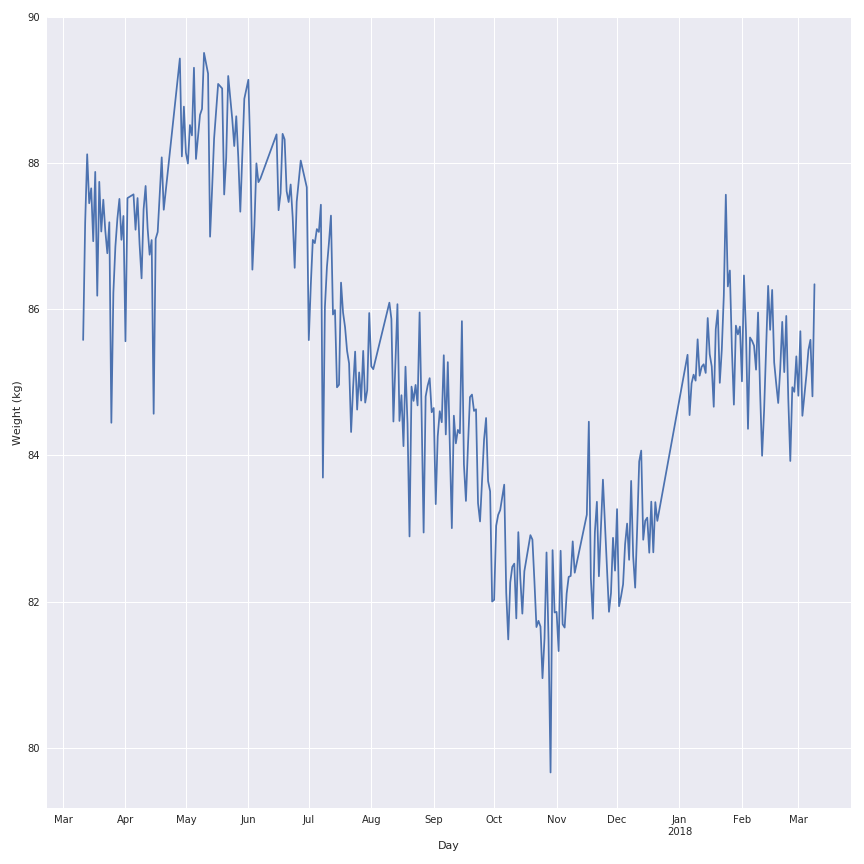
Comme vous pouvez le voir, il y a beaucoup de bruit dans l’évolution du poids au cours de l’année dernière, donc je vais appliquer une fonction de moyenne mobile sur le signal pour le rendre plus joli et garder la tendance du comportement.
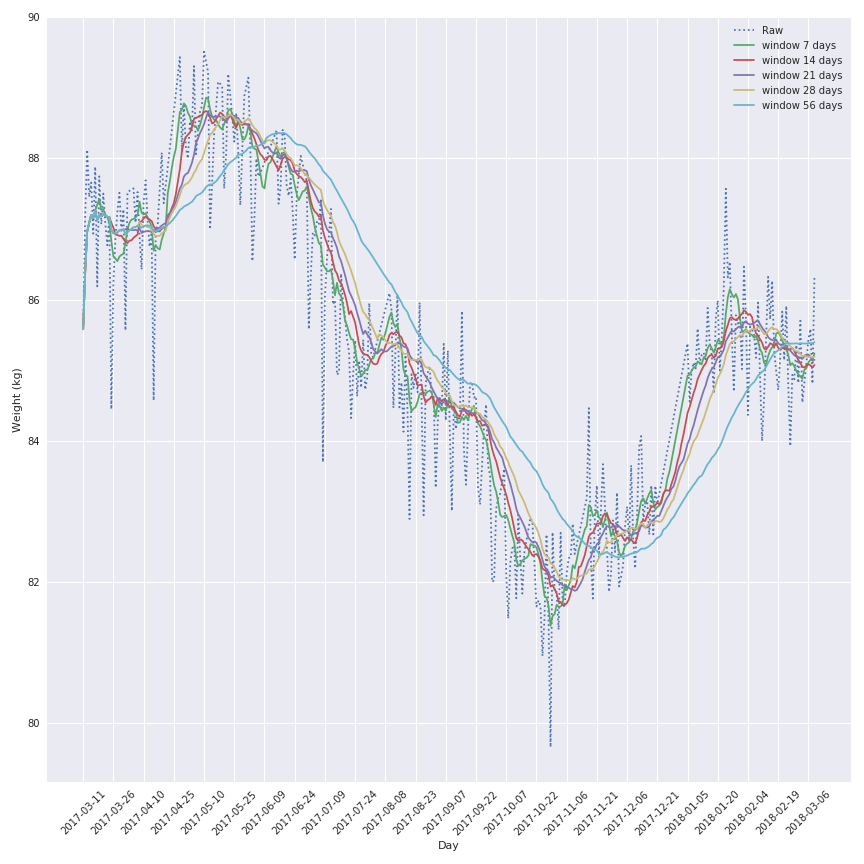
La fenêtre la plus intéressante semble être la fenêtre de 7 jours car celle-ci garde la variation locale mais n’est pas affectée par un effet de retard qui corromprait l’analyse des données.
La conclusion sur la variation est la même pour le ratio de graisse.
Un autre élément à analyser pourrait être la variation hebdomadaire des métriques pour illustrer les bonnes et mauvaises semaines et peut-être détecter les périodes intéressantes (gain de muscle ou de graisse par exemple)
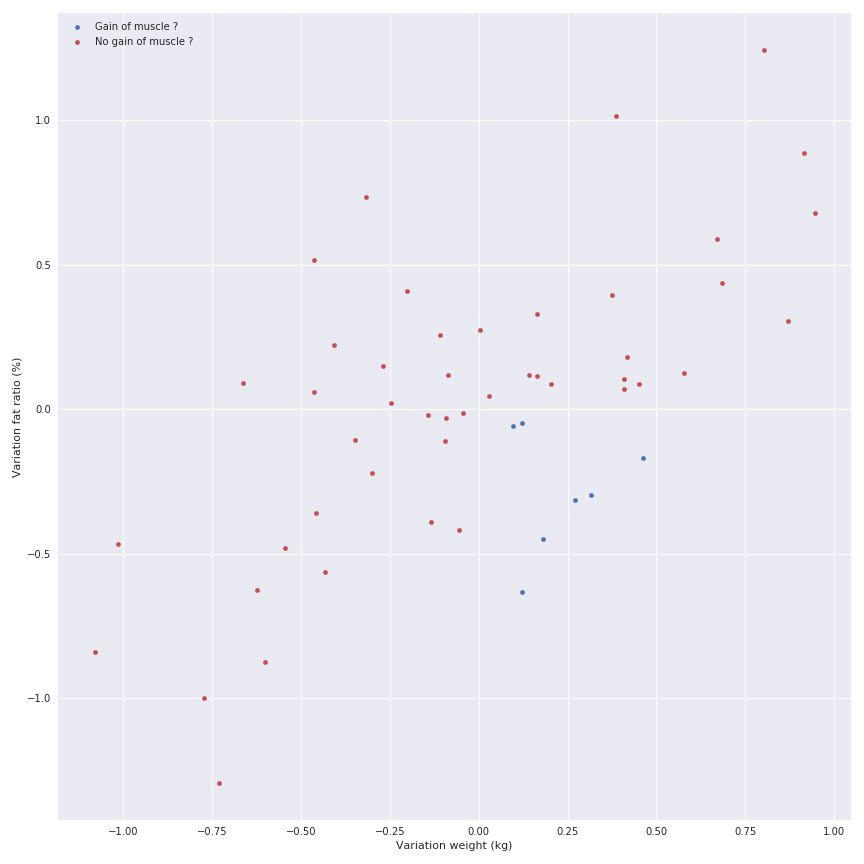
Il y a une relation linéaire entre le gain de graisse et le gain de poids, mais je ne veux pas l’afficher car je sais qu’il y a des phases où vous pouvez prendre du poids mais perdre de la graisse (gain de muscle), donc la relation n’existe pas.
Jetons un coup d’œil aux données Strava.
Données de course
Je cours essentiellement une fois par semaine en moyenne environ 10 km en moins d’une heure.
Les métriques intéressantes pour cette source de données sont :
- la distance
- la vitesse moyenne
- l’élévation
- le temps écoulé
Quelques graphiques à barres très simples peuvent être affichés sur l’évolution de ces paramètres.
Le point intéressant est de croiser la distance, la vitesse moyenne et l’élévation ensemble pour voir l’impact du dernier paramètre sur la vitesse.
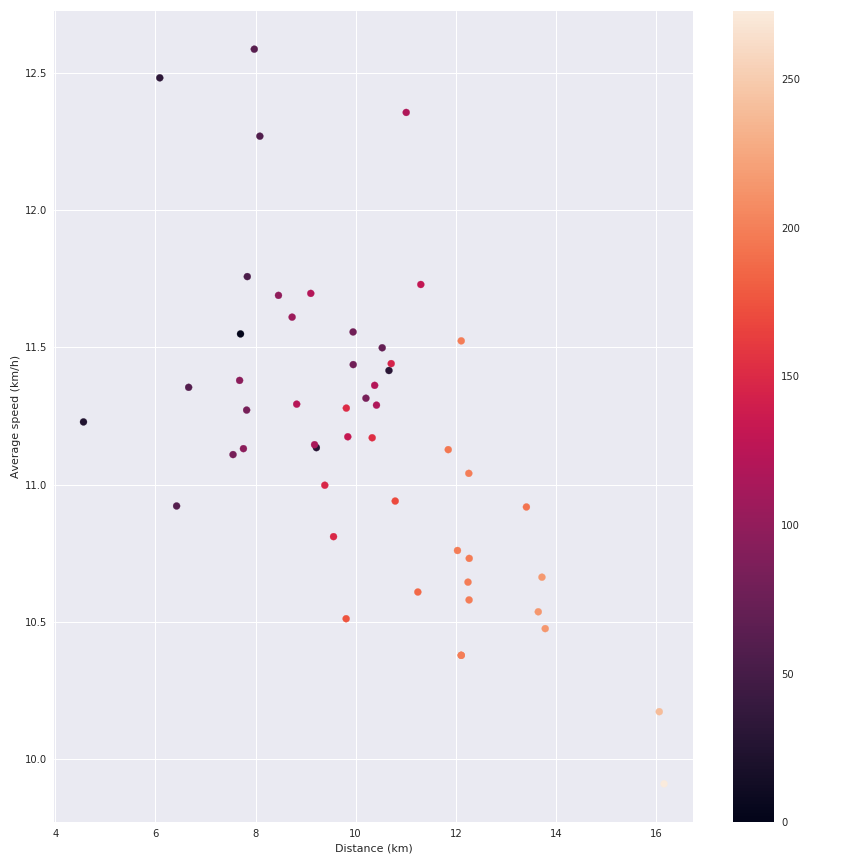
On peut voir l’impact de l’élévation sur ma vitesse moyenne. Mais soyons honnêtes, cette source de données n’est pas très excitante (je collecte également les détails des séances de course comme la vitesse pendant la séance, etc., mais je ne fais actuellement rien avec ces données).
Jetons un coup d’œil aux données de crossfit.
Données Crossfit
Je pratique le crossfit depuis août 2017, 3 fois par semaine et je ne suis définitivement pas un pro. Dans la figure suivante, il y a une visualisation du poids total porté pendant une séance en fonction du nombre de répétitions.
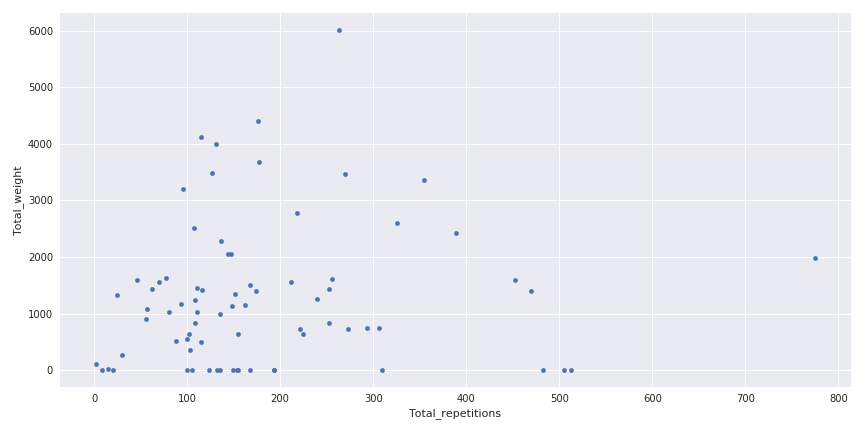
Poids porté en fonction du nombre de répétitions
Cette figure est une bonne illustration de la variété de séances qui peuvent se produire en crossfit, certaines où vous pouvez porter beaucoup de poids sans trop de répétitions et au contraire certaines avec beaucoup de répétitions et pas trop de poids.
Une autre partie intéressante est de voir l’évolution du poids entre les séances pour un exercice (et oui je progresse un peu).
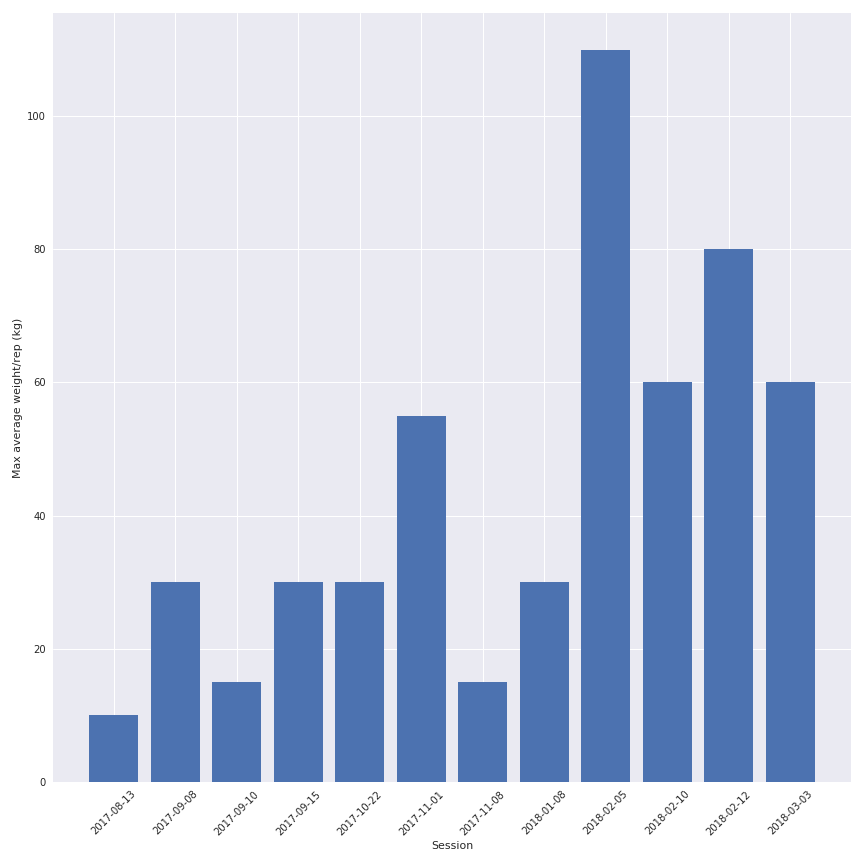
Donc la qualité des données dépend de ma motivation à les écrire correctement dans la feuille de calcul, mais la quantité d’informations est assez intéressante.
Il est maintenant temps de créer le tableau de bord qui affichera toutes ces informations.
Conception du tableau de bord
Pour ce tableau de bord, mes exigences pour l’application sont :
- Facile et peu coûteux à déployer
- Processus d’authentification pour accéder au tableau de bord
Je vois des gens dire “oh vous devriez utiliser R Shiny pour créer votre application parce que…” et je dirais.
Honnêtement, je ne suis pas un grand fan de R, je sais comment l’utiliser mais je le trouve assez limité quand je veux faire des choses de calcul plus avancées qui ne sont pas liées à l’analyse de données.
Et je veux écrire un article sur Dash, alors allons-y avec Dash.
Pour moi, il est important d’avoir les sections suivantes sur le tableau de bord :
- Un aperçu des données (comme la dernière valeur, et quelques statistiques rapides)
- Une section pour chaque source de données
- Une section de prévision où je peux utiliser un peu de ML
Je vous invite à utiliser le code et l’environnement dans ce dépôt Github pour commencer.
Présentation du tableau de bord
Dans cette section, je vais décrire et présenter le tableau de bord dans sa dernière version (avant le “coup de polish” CSS final).
Pour le style de l’application, j’ai utilisé les ressources suivantes :
- Inspiration/super base pour les métriques merci @Jamie pour le lien.
- Bootstrap 4
- Support de @Marius pour le css final
La section aperçu
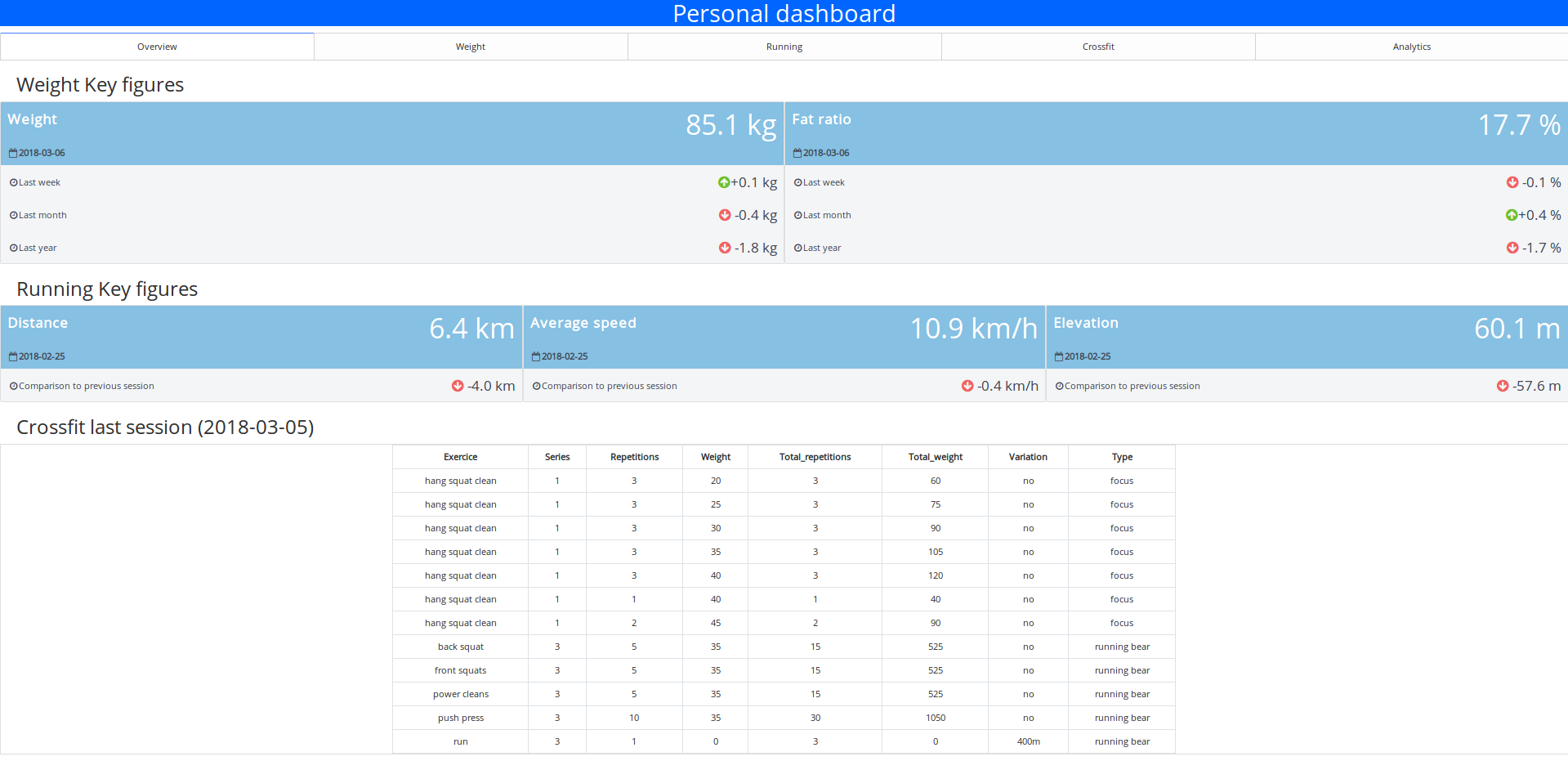
Dans cette section, l’idée est d’offrir à l’utilisateur un aperçu très clair et simple des différentes métriques et un aperçu rapide de leur évolution.
Il y a une première partie où des informations sur le poids et le ratio de graisse sont affichées.
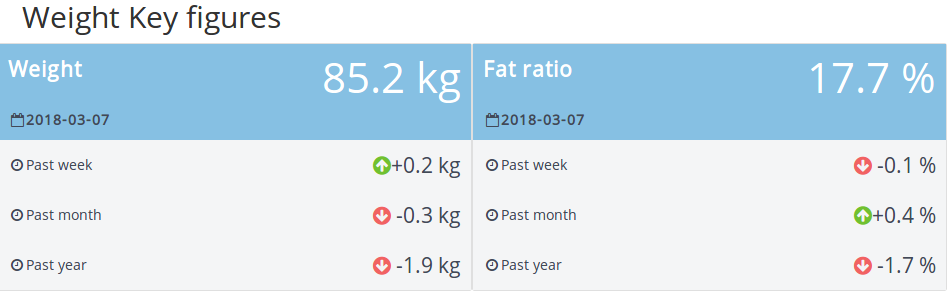
Il y a pour chaque paramètre :
- La dernière mesure (et quand elle s’est produite)
- L’évolution des métriques sur différentes périodes (depuis la semaine dernière, le mois dernier et l’année dernière)
J’ai trouvé cette partie très riche en informations, elle est facile à comprendre et vous pouvez voir les tendances (donc parfait pour mes parents)
Cette section est suivie d’une autre avec la dernière séance de course, plus simple.

Il y a des informations sur la distance, la vitesse moyenne et l’élévation suivies d’une comparaison avec la séance précédente.
Pour le reste de la section, c’est une table qui contient les exercices de la dernière séance de crossfit, donc rien de vraiment excitant, pas besoin de zoom.
Les sections poids et course
Pour les deux sections suivantes, ce sont essentiellement des figures très basiques où je prends la visualisation de cet article.
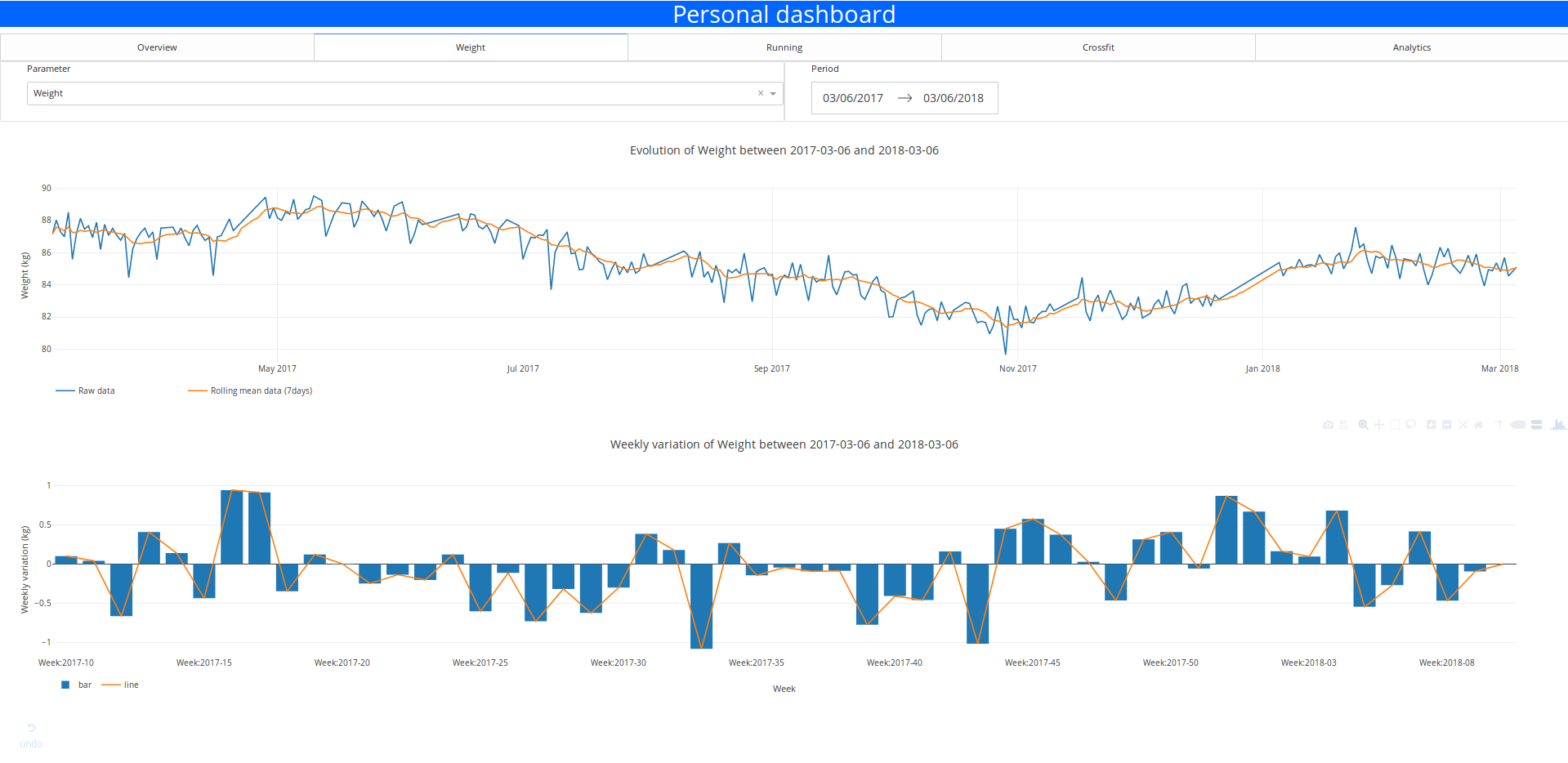
L’utilisateur peut sélectionner la période de temps et le paramètre qu’il souhaite visualiser avec les éléments d’entrée. Il peut sélectionner le paramètre et la plage de données avec le panneau déroulant et le sélecteur de plage de dates

La mise en page est super simple mais elle est fonctionnelle.
La section crossfit
Dans cette section, j’ai choisi de croiser l’index des métriques et les options d’entrée des sections précédentes.
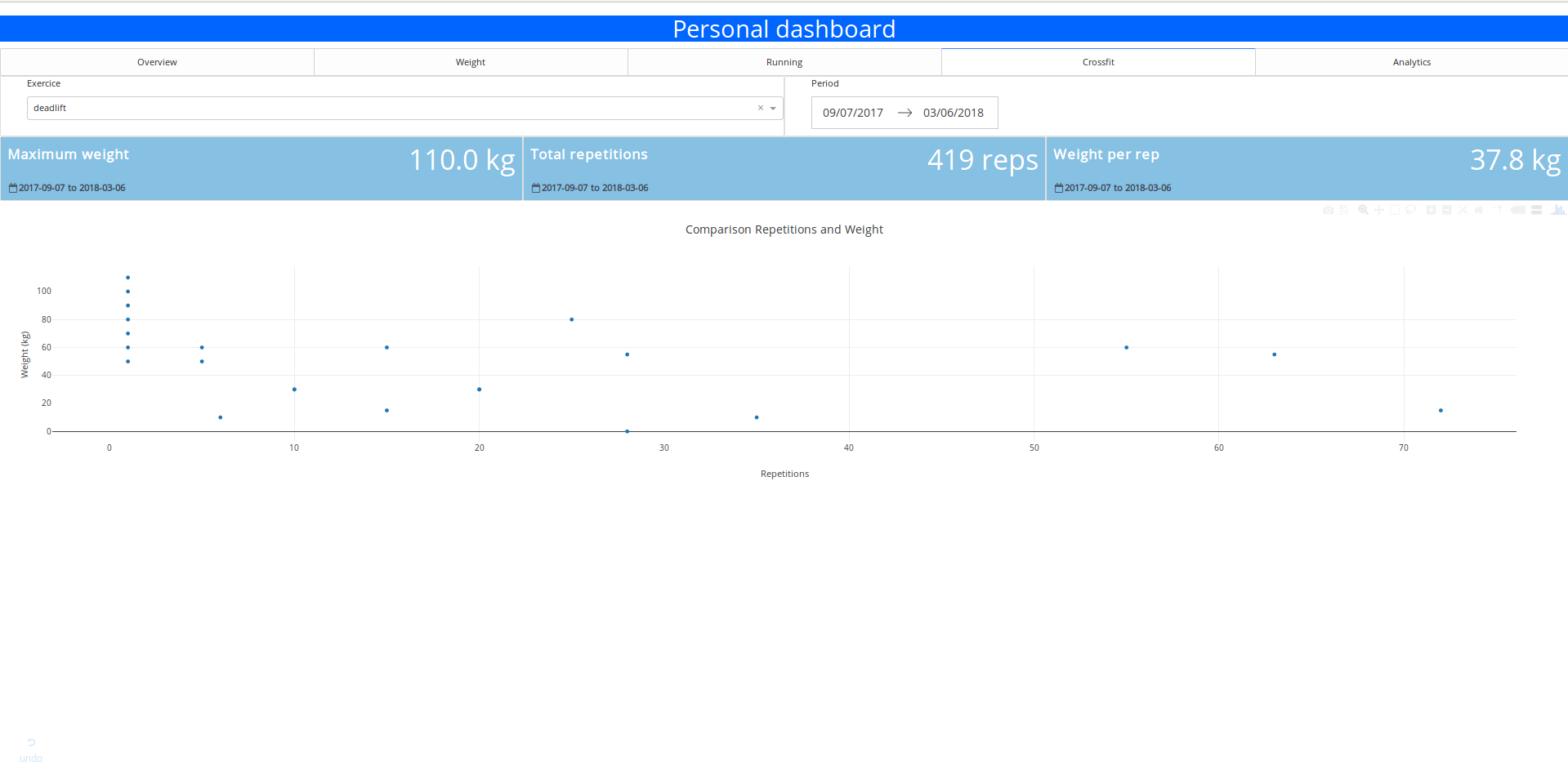
Vous pouvez sélectionner les exercices et obtenir quelques statistiques rapides sur eux :
- Le poids maximum porté
- Le nombre de répétitions exécutées
- Le poids moyen par répétition
- Le graphique des répétitions vs poids
C’est simple mais assez utile quand je veux trouver rapidement mon poids max 1 rep.
Section prévision
Dans cette section, c’est essentiellement le panneau de contrôle pour appeler l’API qui contient le modèle.
L’utilisateur peut sélectionner la période de prévision et les paramètres d’entraînement hebdomadaires et avoir une idée de l’évolution du poids et du ratio de graisse à la fin de la période de prévision.
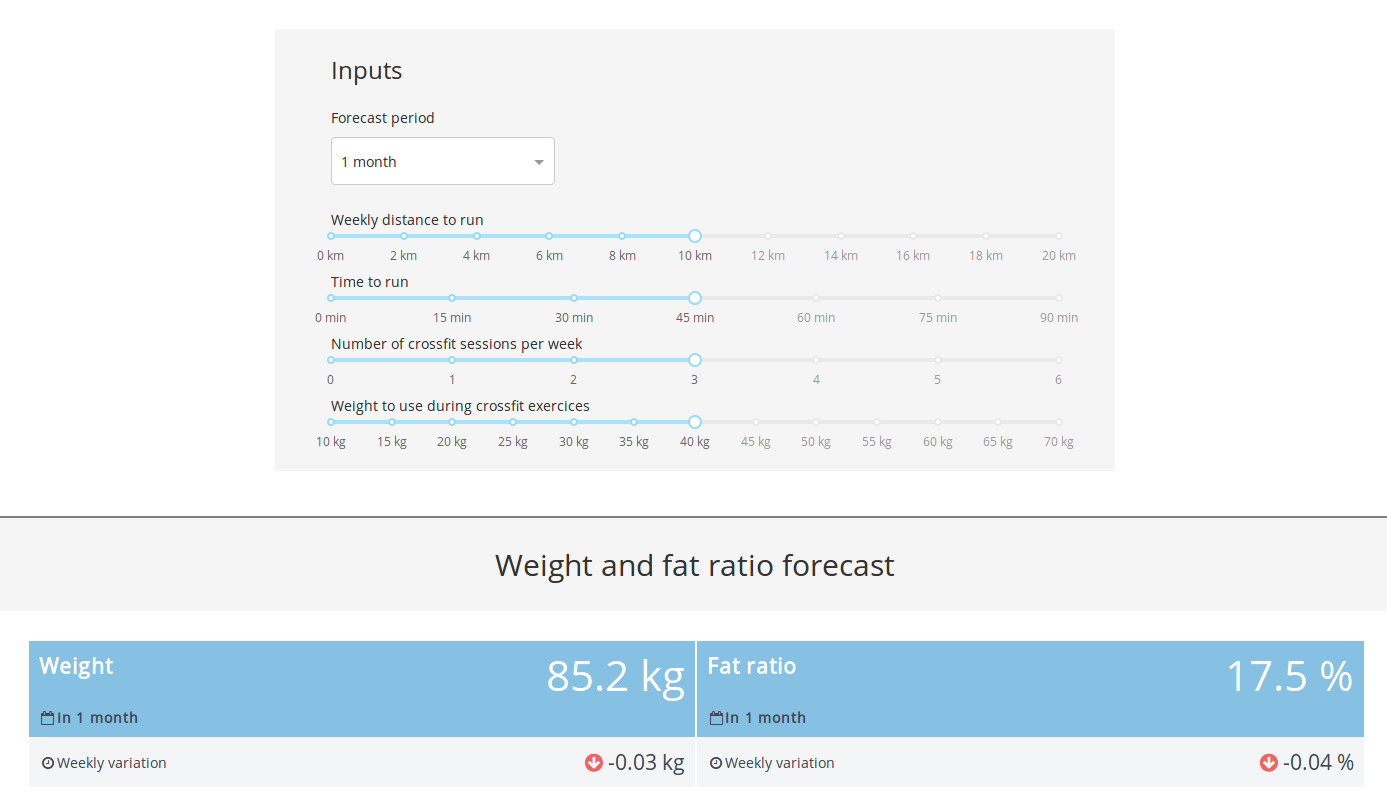
Section prévision
Peut-être pas précis, mais au moins c’est là et cela deviendra certainement meilleur avec plus de données (le modèle est entraîné sur 30 points).
Conclusion et prochaines étapes
Donc le prototype fonctionne très bien et est déployé sur Heroku (si vous voulez y avoir accès, vous pouvez me contacter). Il m’a fallu 2 semaines pour le faire (week-ends et pauses déjeuner), donc je suis assez content de cela.
Vous pouvez trouver tout le code (au moins le squelette de l’application) dans le dépôt Github.
Les prochaines étapes sont :
- Essayer peut-être une alternative avec Flask et D3.js
- Ajouter plus de données, peut-être un indice alimentaire
- Implémenter une visualisation des détails de la séance de course (leaflet pourrait être un bon début)
- Trouver d’autres métriques à afficher
- Obtenir des retours des utilisateurs
Références
- Dépôt dash_template_dashboard — GitHub
- Dash — GitHub
- Plotly — plot.ly
- API Google Drive — developers.google.com
- AWS Free Tier — AWS
- Dépôt python-nokia — GitHub
- Flask — flask.pocoo.org
- Zappa — GitHub
- Ratio de graisse corporelle — Wikipedia
- An Easy Way to Read and Write to a Google Spreadsheet in Python (Twilio) — twilio.com
- Sheetsu — sheetsu.com
- Bootstrap 4 — getbootstrap.com
- Leaflet.js — leafletjs.com