
Construire un pipeline de données sur AWS
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
J’ai démarré ce projet en écho à la compétition Kaggle liée à PUBG, où l’objectif était de prédire le classement du joueur dans la partie basé sur certaines statistiques de fin de match (comme la distance parcourue durant la partie, etc.). Je voulais comprendre la source de données (pour voir s’il y a des statistiques/informations volontairement manquantes) et essayer certains services d’Amazon comme AWS Glue et Athena pour construire un pipeline de données dans AWS.
Dans cet article, je vais expliquer :
- Ce qu’est PUBG, le principe du jeu, etc.
- L’approche du projet
- La collecte et le nettoyage des données
Description de PUBG
PUBG est l’un des jeux phares (le premier et l’un des plus populaires) d’un type de jeu vidéo appelé battle royale. Le principe est que 100 joueurs (plus ou moins) sont largués sur une île sans équipement et ils doivent survivre sur cette île en collectant des matériaux, des armes, de l’équipement et des véhicules.
Pour pousser les gens à se battre, la zone disponible devient de plus en plus petite au fur et à mesure que le jeu progresse, donc ce format pousse les gens à se battre les uns contre les autres car à la fin il ne peut y avoir qu’un seul survivant. Il y a deux jeux très populaires qui soutiennent le mouvement : PUBG et Fortnite. Ils sont disponibles sur toutes les plateformes possibles (PUBG sur console n’est pas terrible), et maintenant vous pouvez voir que tous les autres jeux populaires (Call of Duty, Battlefield) veulent ajouter leur propre mode battle royale à l’intérieur, mais soyons honnêtes, Fortnite écrase tout le monde (regardez les Google Trends PUBG vs Fortnite).
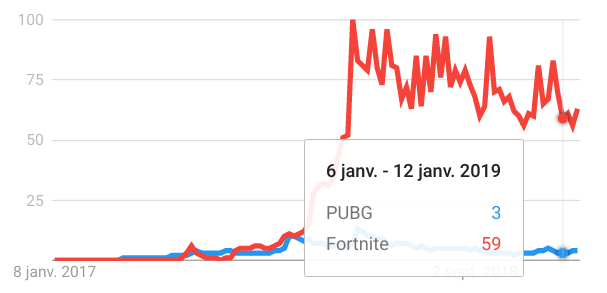
Mon opinion sur ce genre de jeu est que le principe est cool, vous pouvez construire des situations incroyables où il y a de la tension pendant le jeu, mais je pense que vous ne pouvez pas vendre (à plein prix) un jeu qui est juste du battle royale. Epic a été intelligent avec Fortnite car ils ont transformé un projet qui a pris beaucoup de temps à produire et dont les ventes n’étaient pas bonnes en quelque chose de très lucratif en proposant une application autonome gratuite qui utilise les mêmes assets que le jeu original mais se concentre uniquement sur le battle royale (j’espère que le gars qui a eu l’idée a eu une augmentation).
Voyons maintenant le projet de collecte de données.
Approche du projet
L’idée derrière ce projet est de : Construire un système pour collecter les données à partir de l’API fournie par PUBG corporation Nettoyer les données Rendre toutes les données disponibles sans tout télécharger sur ma machine
Pour construire le pipeline, j’ai décidé d’utiliser AWS car je suis plus à l’aise avec leurs services que Microsoft, Google, etc., mais je suis sûr que le même système peut être construit sur ces plateformes aussi.
Pour accomplir la tâche, j’ai décidé d’utiliser les services suivants :
- Instance EC2 pour avoir une machine en cours d’exécution pour faire la collecte
- S3 pour stocker les données collectées et traitées
- Glue pour rendre les données propres et disponibles
- Athena pour être l’interface avec les données stockées dans S3
Voici une vue de haut niveau du processus déployé sur AWS avec les différentes étapes.
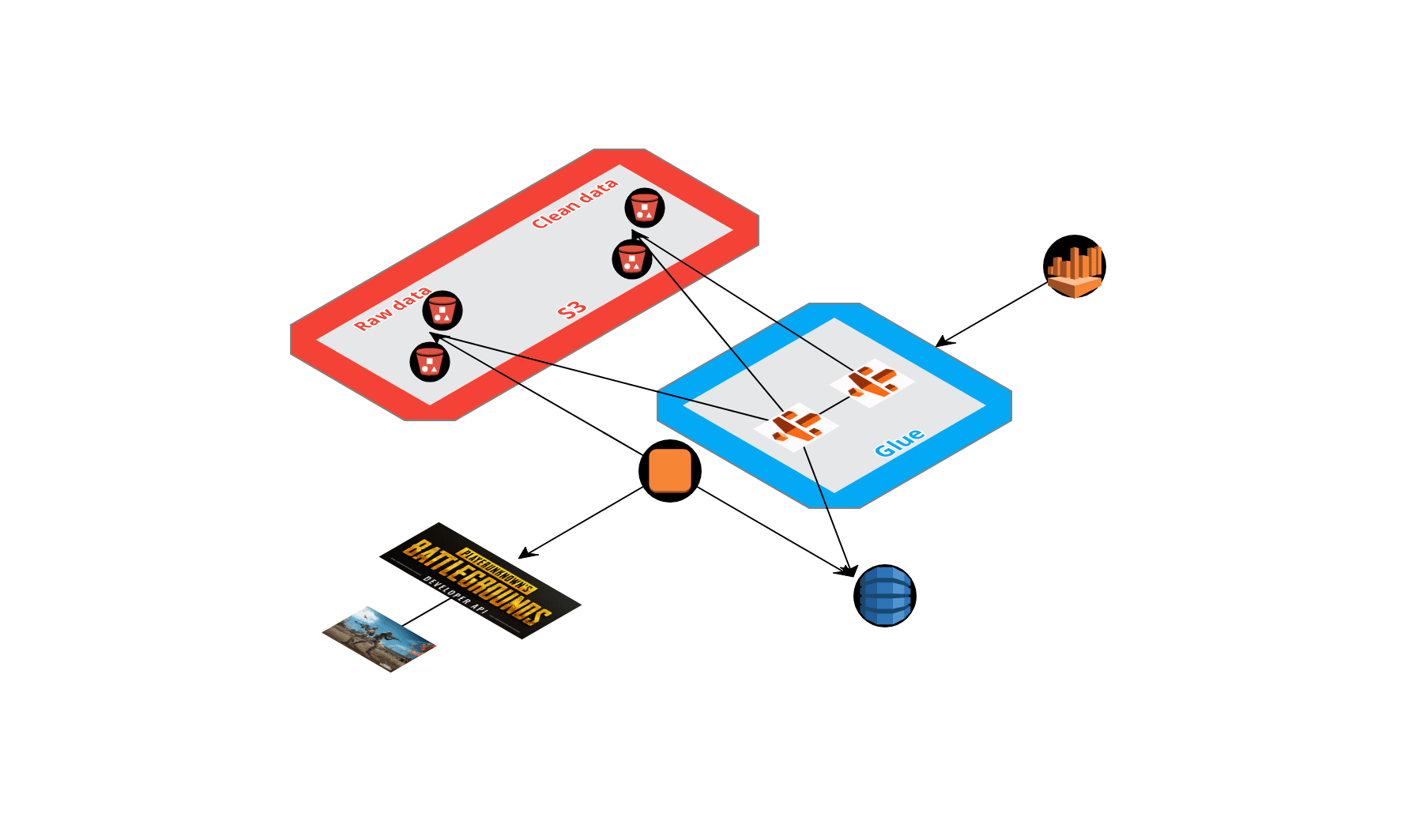
Voyons le processus en détail.
Collecter les données de l’API PUBG
La corporation PUBG a construit une très bonne API ouverte, il y a plusieurs endpoints qui ouvrent différentes sources de données. Pour faire simple, vous pouvez accéder aux données liées à :
- Le joueur PUBG défini par son ID de compte
- Le match défini par son ID de match
Il y a des données de plusieurs plateformes (PC, Xbox et PS4) provenant de différentes régions (Amérique, Europe et Asie). Pour cet article, je vais me concentrer sur la plateforme PC et la zone Amérique du Nord. Il y a plusieurs endpoints sur cette API mais concentrons-nous sur :
- Le sample endpoint : Qui donne accès à certains ID de match mis à jour chaque jour
- Le matches endpoint : Qui donne des détails sur le match, comme le résultat final et plus important encore le lien pour télécharger un paquet compressé d’événements.
Vous pouvez trouver un dépôt avec les fonctions que j’ai construites pour collecter, nettoyer et envoyer les données. Ce notebook donne de bonnes informations sur les données collectées. Il y a trois types de données :
- Les statistiques de fin de match, elles sont stockées dans un “dossier” dans un bucket S3
- Les événements complets qui sont stockés dans un autre dossier
- Les événements décomposés qui sont stockés dans des dossiers séparés
À propos des paquets d’événements, il y a plusieurs événements disponibles sur l’API. Il y a un schéma qui contient les détails sur ces événements.
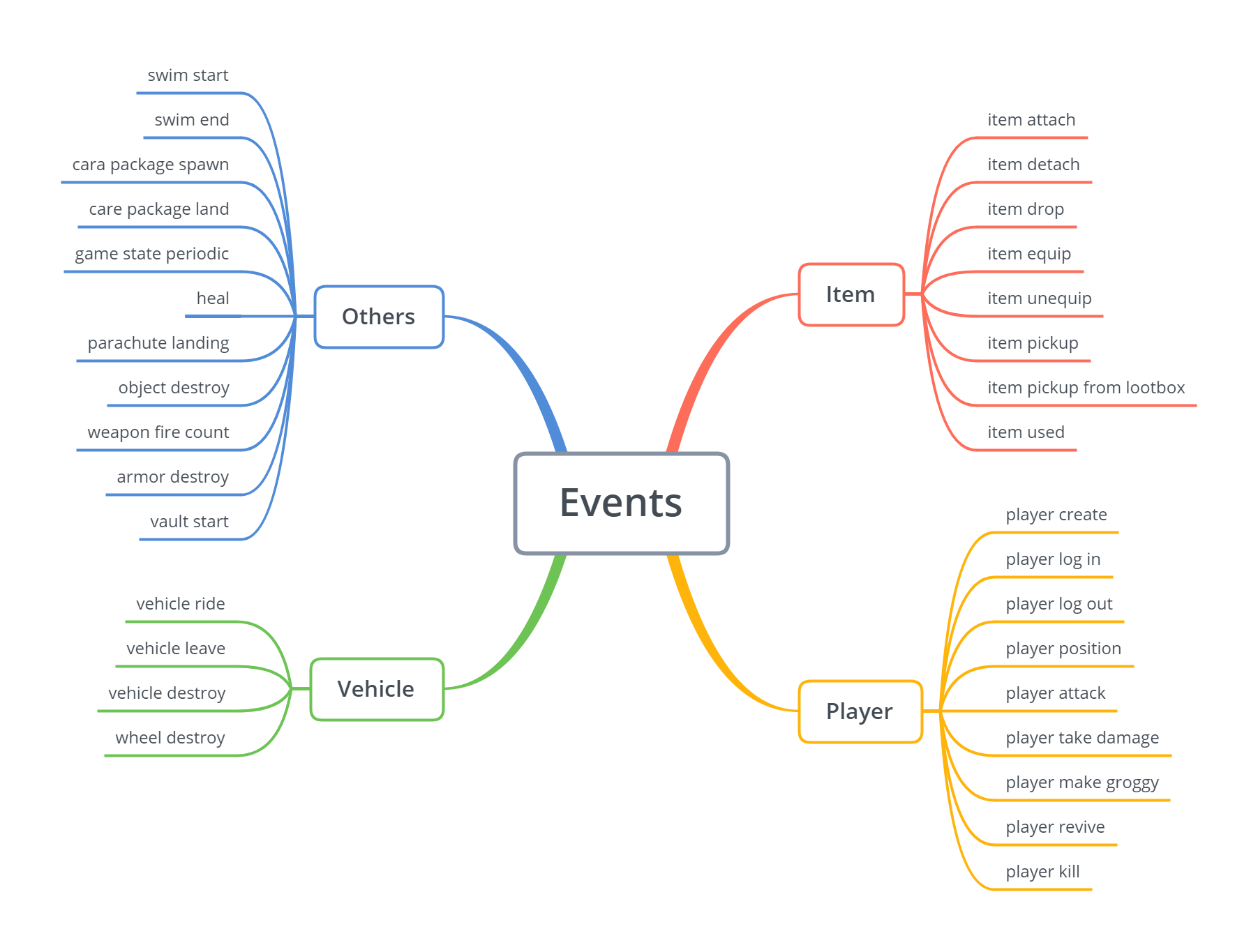
J’ai programmé un script pour s’exécuter chaque jour sur mon instance EC2 qui déclenche l’acquisition de nouvelles données de l’échantillon et les stocke dans le bon dossier et dans un dossier quotidien.
Pour obtenir les informations générales, les détails sur le match sont collectés (comme le nombre de personnes, le nom de la carte, etc.) dans une table DynamoDB.
Quelques conseils que je peux donner lorsque vous stockez les données :
- Stockez-les sous forme de fichiers .gz appropriés
- Soyez clair sur le délimiteur, le caractère d’échappement et le caractère de citation
- Supprimez l’index
- Pour DynamoDB, convertissez vos données float en Decimal
Donc c’est un aperçu simple de la façon dont j’ai collecté les données, maintenant jetons un œil sur la partie cloud.
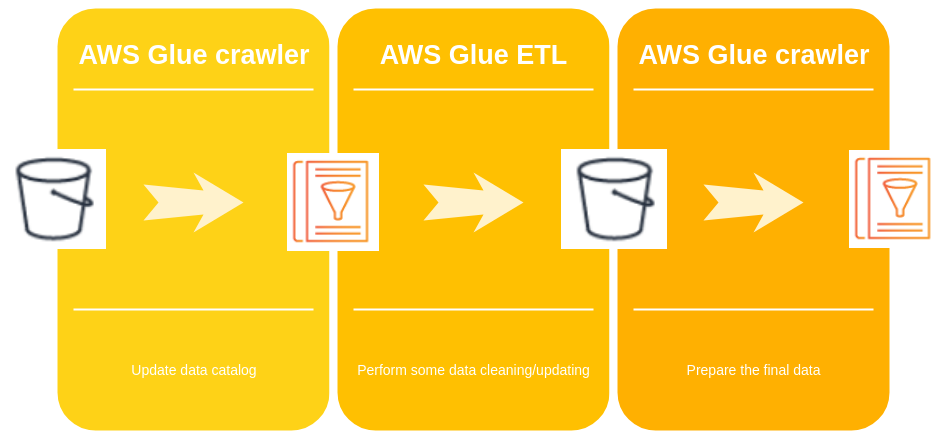
Crawler les données dans S3 et DynamoDB avec Glue (beaucoup de noms)
Le tableau de bord de configuration d’AWS Glue est configuré en deux sections avec la partie catalogue de données et la partie ETL (je vais me concentrer sur la partie supérieure du tableau de bord).
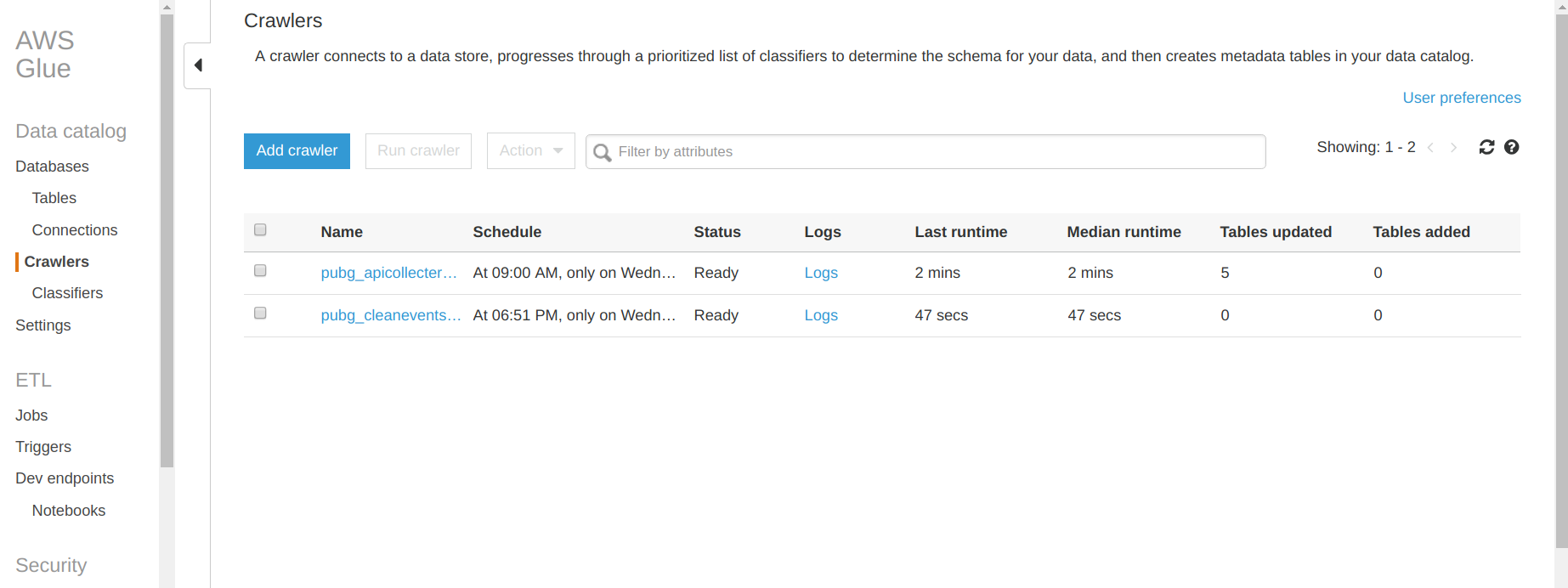
Concentrons-nous d’abord sur le catalogue de données.
Partie catalogue de données et Crawler
Dans cette partie, vous pouvez trouver un onglet base de données qui contient toutes les bases de données et les tables associées que vous avez créées avec Glue. Pour ce projet, j’ai créé ma première base de données. La partie intéressante est l’onglet crawler où vous pouvez configurer le crawler qui naviguera dans S3, DynamoDB et d’autres services AWS (comme RDS). Dans la figure précédente, il y a une liste de tous les crawlers que j’ai créés pour ce projet. Voyons ce qu’il y a à l’intérieur d’un crawler.
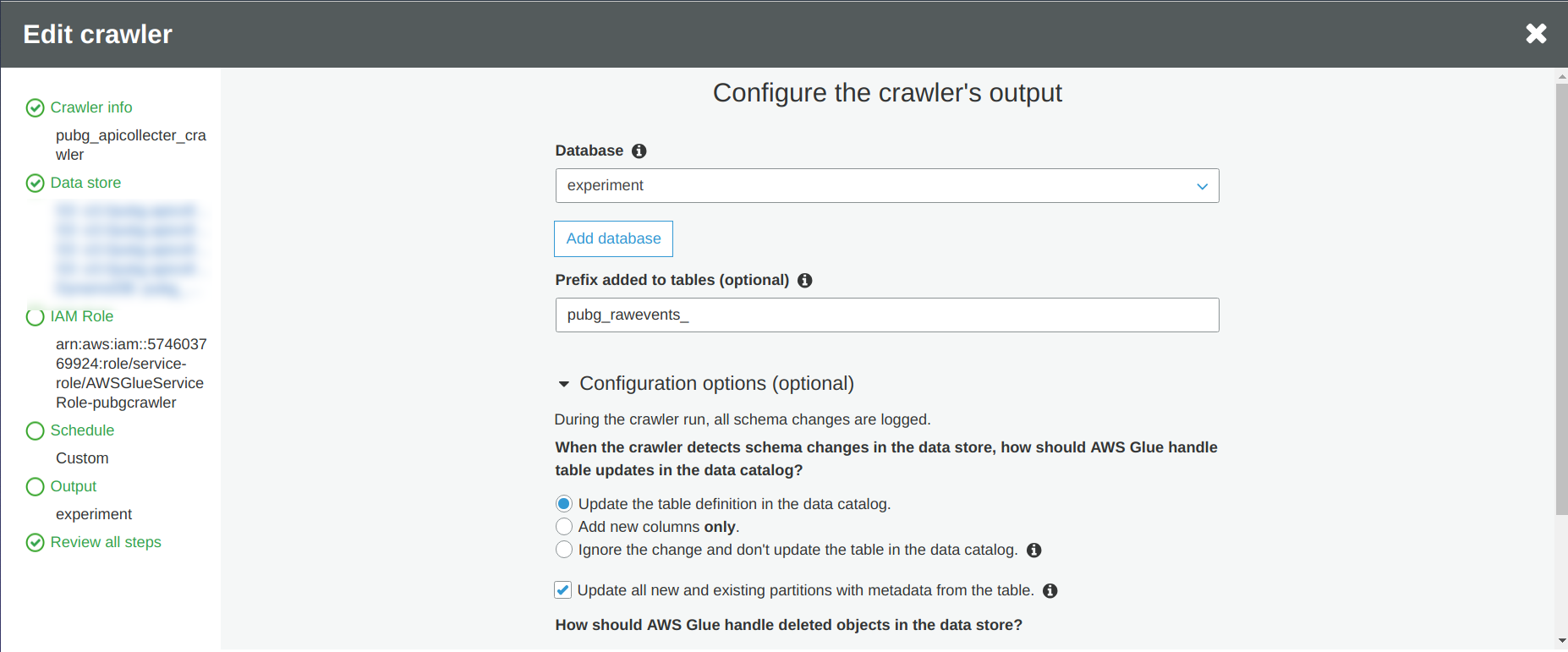
Donc quand vous configurez votre crawler, il y a :
- Trouvez un nom pour votre crawler
- Définissez la source de données, dans ce cas je vais me concentrer sur trois événements et ma table DynamoDB
- Définissez un rôle AWS pour que votre crawler ait accès à toutes les sources de données que vous voulez crawler
- Définissez la fréquence d’exécution du crawler, j’ai décidé de le faire fonctionner une fois par semaine
- Définissez la sortie du crawler
Je recommande fortement d’activer la case à cocher “Update all new and existing partitions with metadata from the table” pour éviter certains problèmes de partition pendant la lecture des données si vous ne contrôlez pas ce que vous recevez comme moi.
Et voilà, vous n’avez qu’à lancer le crawler depuis la page principale d’AWS Glue et vous pouvez maintenant accéder à vos données extraites par le crawler dans Athena (façon SQL d’accéder aux données).
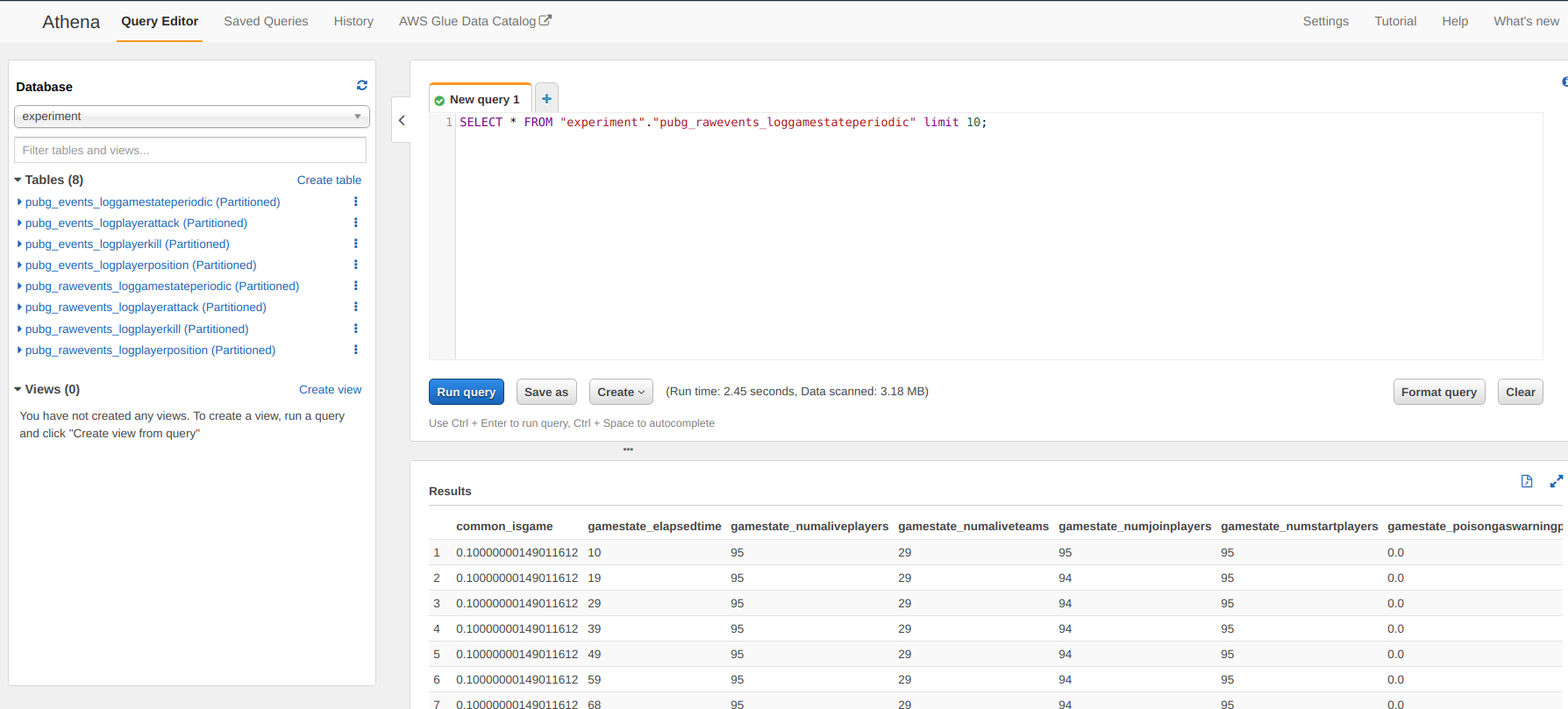
Mais les données sont encore assez brutes, donc j’ai décidé d’ajouter une nouvelle couche au crawler pour faire un peu de nettoyage de données et ajouter des informations.
Partie ETL
Pour la partie ETL, c’est la partie de traitement des données du pipeline. J’aurais pu analyser les données au fur et à mesure qu’elles arrivaient dans le bucket S3, mais j’ai remarqué que certains enregistrements n’étaient pas bons (disons corrompus), donc je voulais appliquer un état de transformation pour ces données pour :
- Supprimer les enregistrements corrompus (avec un mauvais format d’ID de match)
- Faire une jointure avec les détails du match collectés dans la table DynamoDB (et crawlés précédemment)
- Calculer le delta temps entre l’événement et le début du match (en secondes et minutes)
- Faire quelques manipulations de chaînes simples en fonction des événements (comme nettoyer le nom de l’arme)
Il y a une illustration du code et vous pouvez trouver le morceau de code dans le dépôt.
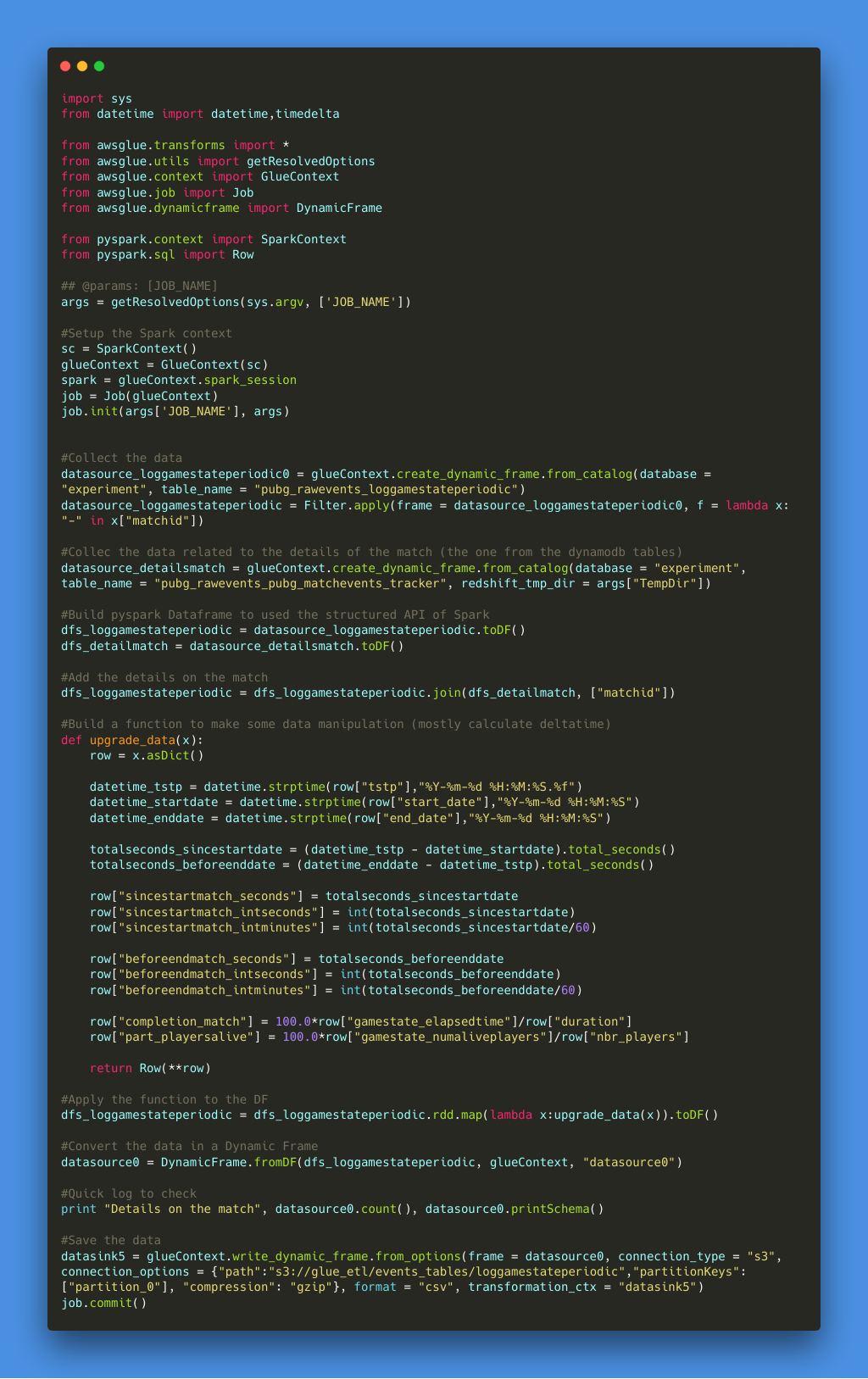
J’ai essayé l’approche code mais il y a une option dans la configuration ETL où vous pouvez avoir plus d’une approche diagramme pour faire la manipulation des données. Comme je voulais utiliser le map RDD et le dataframe de Spark, j’ai décidé de ne pas utiliser cette fonctionnalité, mais j’ai fait quelques tests simples et ça fonctionne bien. Donc maintenant il suffit de construire un crawler pour mettre à jour le catalogue de données avec les nouvelles données générées par la partie ETL.
Dans le schéma suivant, il y a le calendrier des opérations dans AWS Glue.
Et maintenant faisons un test rapide sur AWS pour demander les données traitées depuis l’interface web.
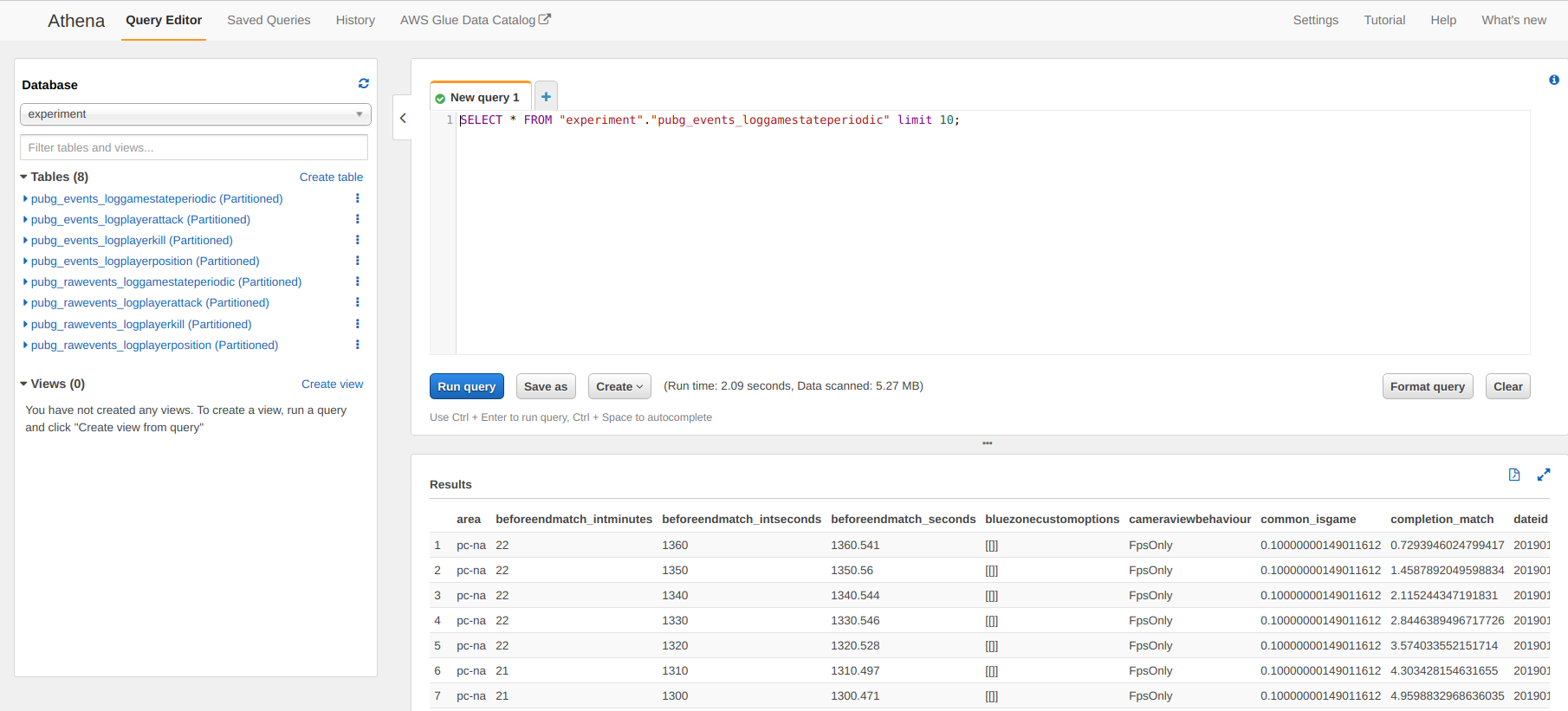
Ces données sont accessibles depuis Athena mais vous pouvez connecter AWS quicksight pour avoir une expérience plus comme Tableau (ce que je n’aime pas, je ne suis pas un grand fan de tous ces outils BI qui sont trop boîte noire pour moi) et plus important encore, vous pouvez accéder à ces données depuis un notebook (il y a une copie d’un environnement python dans le dépôt).
C’était une description de mon pipeline de données pour collecter les données de l’API PUBG. Le système collecte environ 1000 matchs par jour, ce n’est pas une grande quantité mais je voulais commencer petit.
Et je suis un gars sympa, vous pouvez trouver un extrait des tables que j’ai construites pour ce projet (c’est un extrait des données du 27 janvier 2019) dans ce dataset kaggle.
J’espère que vous avez apprécié la lecture, et si vous avez des commentaires n’hésitez pas à commenter.
Références
- Compétition Kaggle PUBG — Kaggle
- API développeur PUBG — developer.playbattlegrounds.com
- Documentation endpoint sample PUBG — documentation.playbattlegrounds.com
- Documentation endpoint matches PUBG — documentation.playbattlegrounds.com
- Dépôt pubg-datacollection — GitHub
- Dataset PUBG Events sur Kaggle — Kaggle