
Comment construire un jeu de données pour un classificateur d'images à partir de zéro (lié aux voitures)
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Dans cet article, je vais présenter un pipeline que j’ai construit il y a quelques semaines pour collecter des données (texte et images) du site Web Turo et le processus pour nettoyer les données collectées afin de les utiliser dans un projet de classificateur d’images.
Avertissement : Ces données sont pour mon usage (je ne les possède pas), donc je ne les partage pas.
Concept du projet
J’ai commencé il y a quelques semaines à penser à approfondir le deep learning, et je voulais démarrer un projet autour de la classification d’images.
La plupart des articles que je lis sur le sujet utilisent tous les mêmes jeux de données comme le jeu de données mnist (les chiffres écrits à la main), deepfashion (collection de vêtements étiquetés), ou le classificateur de races de chiens.
Ces jeux de données sont appropriés, mais je voulais travailler sur quelque chose de différent et à ce moment :
- J’ai découvert en même temps la plateforme Turo qui est une plateforme où les gens peuvent louer une voiture à d’autres personnes en Amérique du Nord (et ça semble bien fonctionner).

- Je commençais à jouer à Forza Horizon 4 sur PC de Playground games.

J’ai découvert il y a quelques semaines deux jeux de données sur le même type de sujets
- Celui de Stanford lié aux images de voitures en lisant cet article de Bhanu Yerra
- Ce dépôt GitHub de Nicolas Gervais
Mais je voulais améliorer mon jeu en termes de scraping, j’ai donc décidé de construire mon scraper du site Web Turo.
Dans une offre de Turo, je me suis rendu compte qu’il y a des images annotées avec le type de voiture.
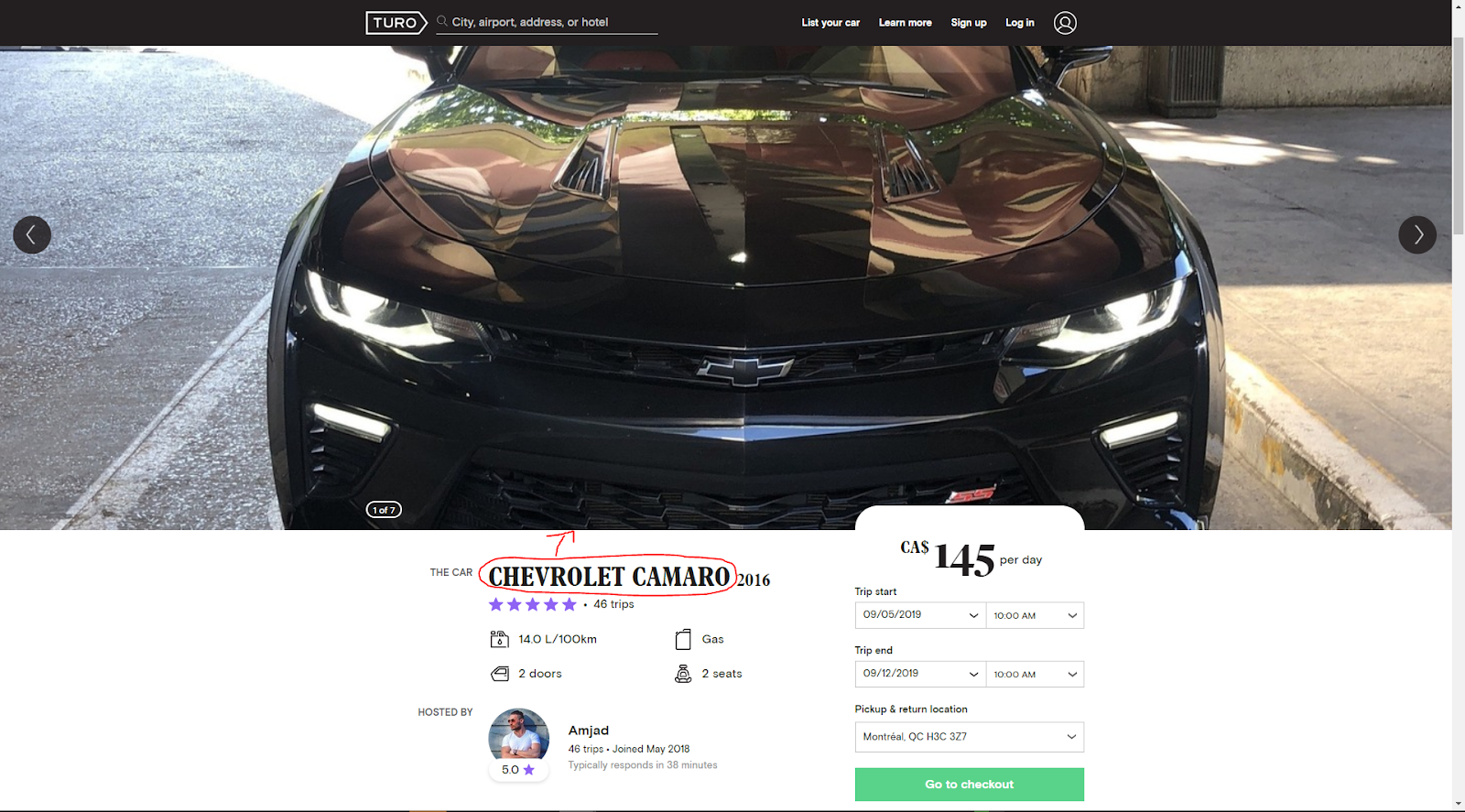
Alors pourquoi ne pas utiliser le site Web comme source pour un jeu de données pour la classification d’images afin de construire un système de détection de voitures.
Pour exécuter l’extraction des données du site Web, je ne peux pas utiliser la même approche avec Beautiful Soup de mon article sur le Crossfit open car :
- L’URL n’est pas très évidente à remplir, donc je dois automatiser ma recherche Turo
- Il y a du défilement à faire pour obtenir toutes les annonces affichées sur une page de résultats
Je peux toujours utiliser Beautiful Soup pour obtenir les données de la page source, mais je dois associer ce package avec un autre package appelé Selenium pour automatiser la recherche sur Turo.
Présentation des packages
Dans cette partie, je vais donner une brève introduction aux bibliothèques que j’ai utilisées pour parcourir tout Turo.
Beautiful Soup
Beautiful Soup est un package “pour extraire des données de fichiers HTML et XML. Il fonctionne avec votre parseur préféré pour fournir des moyens idiomatiques de naviguer, rechercher et modifier l’arbre d’analyse. Il économise généralement aux programmeurs des heures ou des jours de travail”.

Avec ce package, après la collecte de la page source en ligne, vous pouvez segmenter toutes les balises HTML et rechercher à l’intérieur pour collecter les informations dont vous avez besoin. À mon avis, ce package est un excellent début pour commencer le web scraping avec Python, et il existe de nombreuses ressources utiles sur le sujet.
Selenium
Ce package peut être vu comme un package d’automatisation de navigateur web.

Ce package permet à un script Python d’ouvrir un navigateur web comme Firefox, de remplir des champs sur une page web, de faire défiler la page web et de cliquer sur des boutons comme un humain peut le faire. Plongeons maintenant dans le pipeline de données.
Présentation du pipeline de données
Aperçu
En termes de collecte de données, j’ai décidé de concentrer ma collecte de données sur les plus grandes villes nord-américaines, j’ai donc pris :
- La ville centrale pour les États américains qui contiennent au moins 1 million de personnes
- Les 15 villes les plus peuplées au Canada
Voici une carte du panel de villes dont je scrape les données.
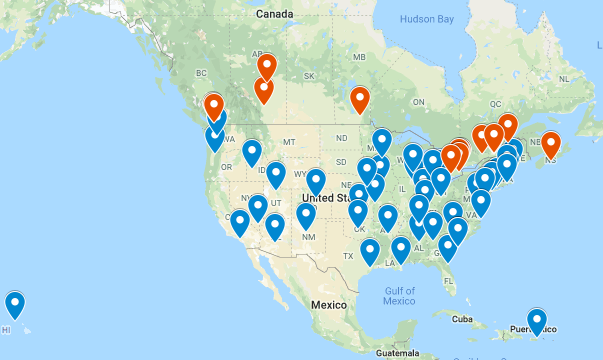
Cela représente 60 villes (en bleu les États-Unis et en rouge le Canada), comme ça j’ai plusieurs types d’environnements (montagnes, mer) et des types de météo différents qui peuvent induire différents types de véhicules.
L’idée est de collecter toutes les 6 heures les nouvelles offres de 5 villes qui sont choisies aléatoirement sur la liste des villes. Le stockage des données reçues est fait :
- En local, toutes les images sont sauvegardées sur la machine de scraping
- Dans AWS, j’utilise une table dynamodb pour stocker les informations des offres scrapées (id, détails sur l’offre) pour toujours avoir les infos disponibles sur les offres sauvegardées
J’ai lancé ce pipeline pendant environ deux semaines, et j’ai téléchargé environ 164000 images.

Regardons maintenant plus en détail le script qui effectue la collecte de données avec Selenium et Beautiful Soup.
Collecter les offres
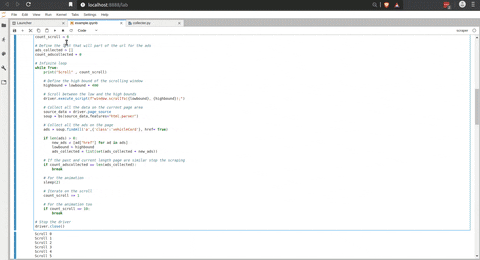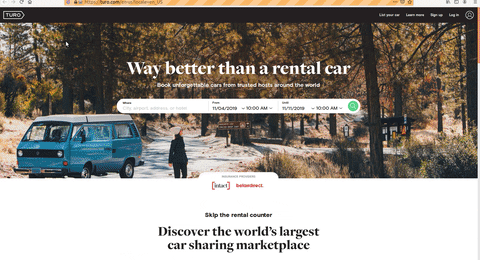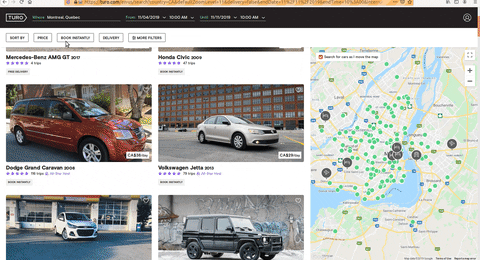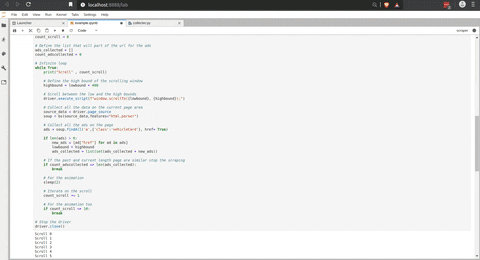
Tout d’abord, pour collecter ces données, j’ai besoin d’un moyen de donner une ville et d’obtenir les offres actuellement disponibles. Voici un code qui peut collecter des offres pour la ville de Montréal.
Comme nous pouvons le voir :
- l’utilisation de Selenium passe par la déclaration d’un driver qui peut contrôler le navigateur web pour faire la navigation sur le site web
- Avec l’objet driver, je peux configurer mon script pour remplir un champ spécifique défini par un id dans ce cas
js-searchFormExpandedLocationInputet envoyer la clé à cette entrée particulière (dans ce cas l’emplacement dans le champ ville)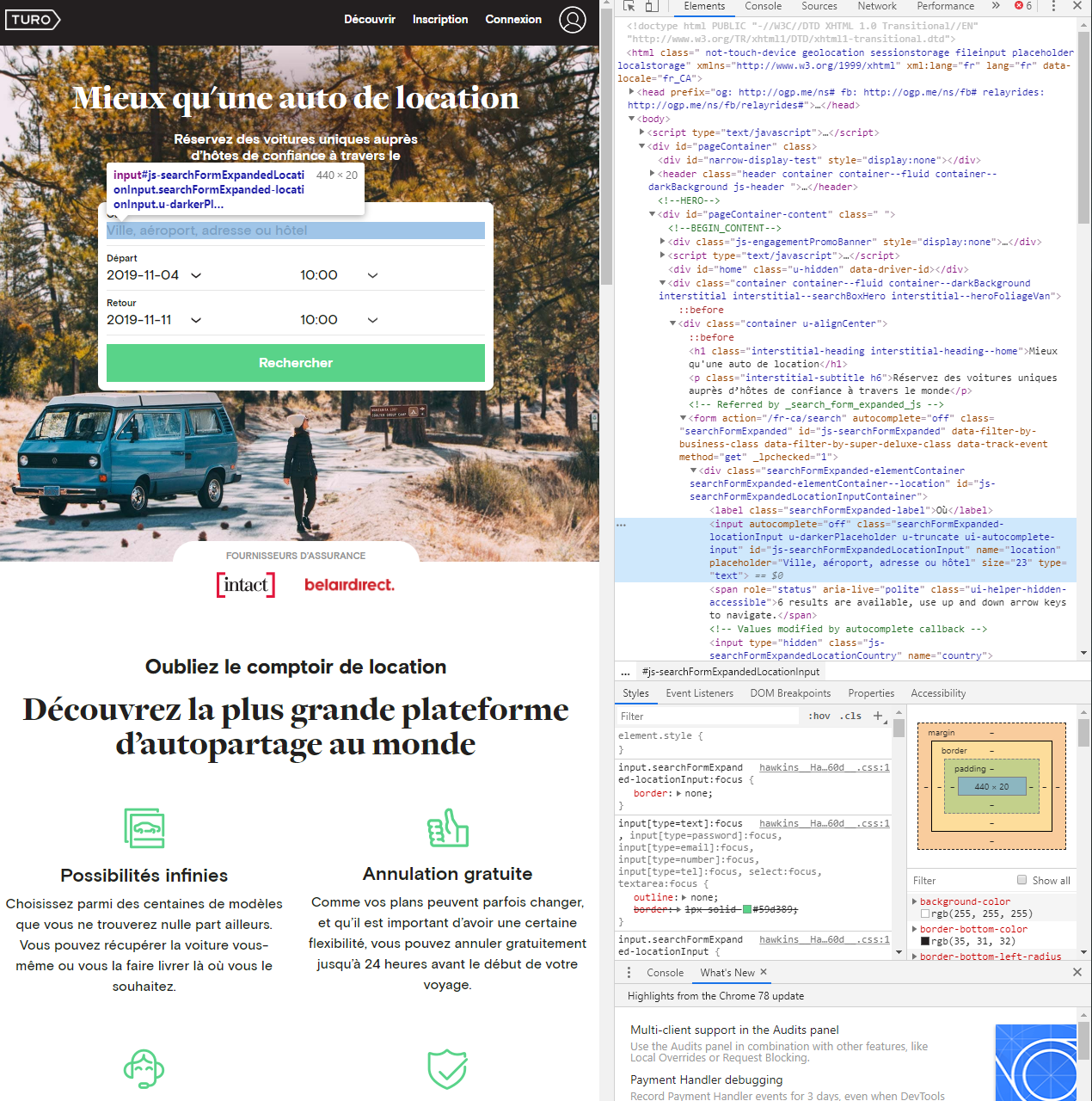
- Une autre partie de Selenium est l’interaction directe avec les boutons (besoin de trouver le bouton sur la page et l’activer) sur la page.
Pour le défilement sur la page, c’est un peu délicat ; j’ai utilisé la méthode de Michael J Sanders pour faire défiler une “page infinie”.
Entre chaque défilement, j’utilise Beautiful Soup pour collecter toutes les offres qui étaient sur la page.
Voici une animation du script en action.
Après cela, j’applique simplement un filtrage sur les offres que je n’ai jamais vues auparavant (qui ne sont pas dans ma table dynamodb) et j’utilise un nouveau processus pour collecter les données d’une offre spécifique.
Collecter les images
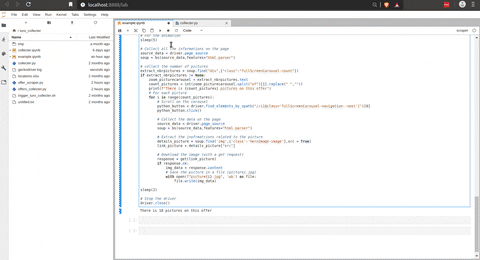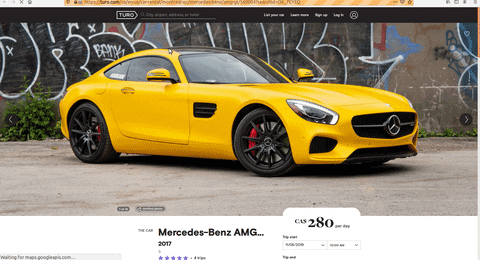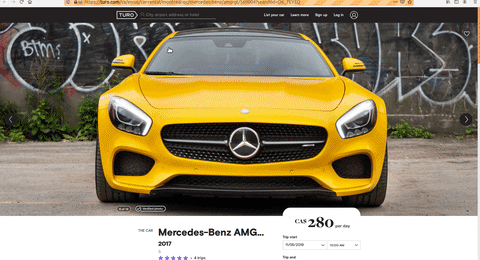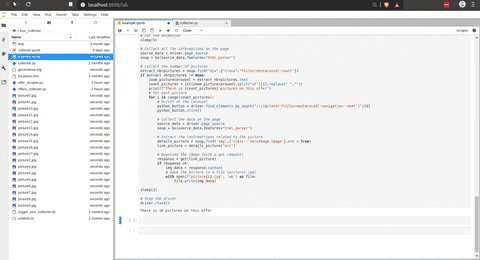
Voici le script pour collecter les données d’une offre.
La partie délicate de ce script est de collecter l’URL des images sur l’offre. La capture d’écran suivante illustre que les images sont stockées dans un carrousel.
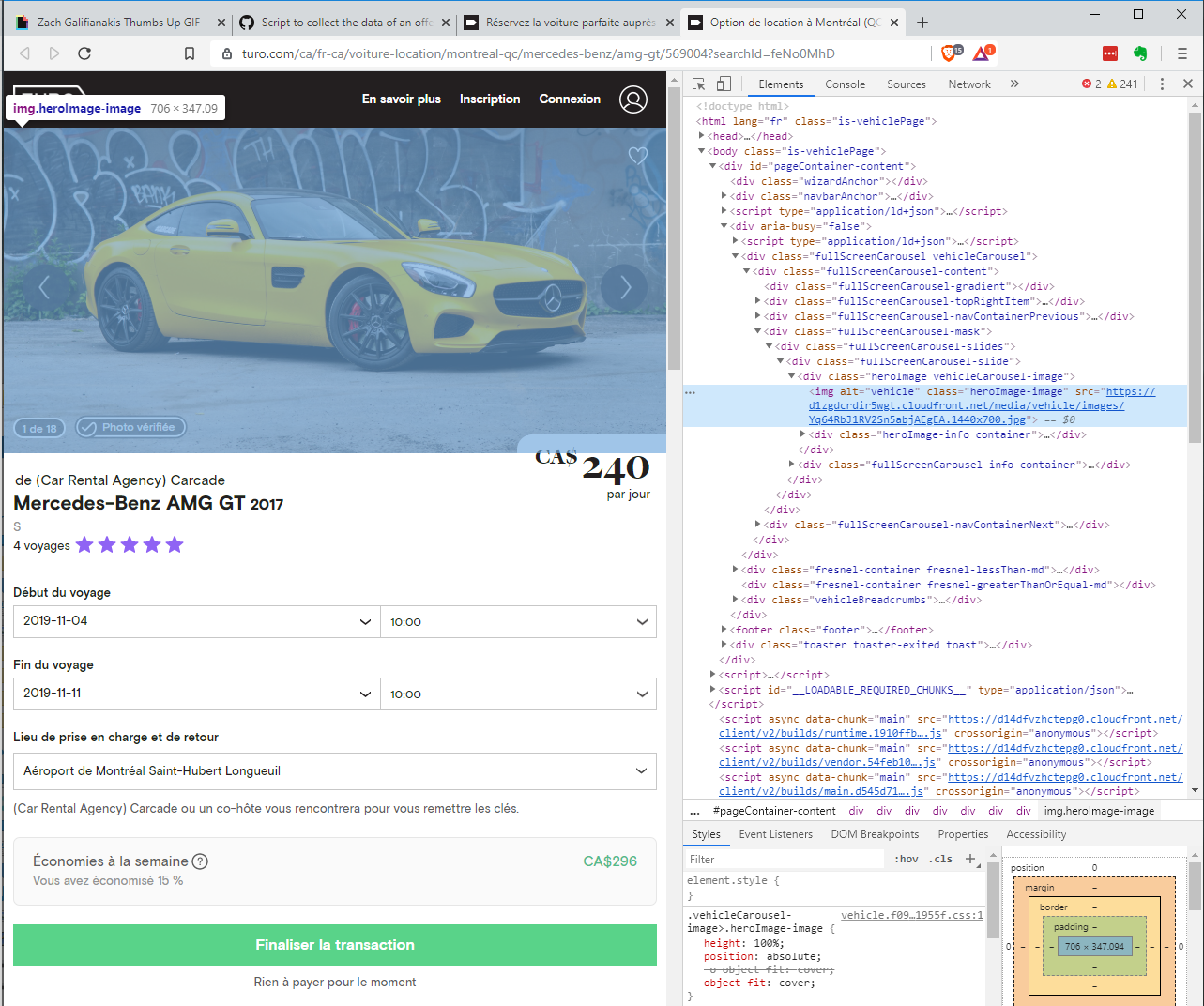
J’utilise la même astuce qu’avec le bouton de validation sur la page d’accueil, et avec cela, je peux facilement collecter toutes les URL des images et, avec une requête GET, les télécharger sur ma machine. Voici une animation du script précédent en action.
Si vous voulez exécuter les scripts, je vous invite à configurer un environnement python avec la configuration qui est sur ce dépôt Github (sur une machine Linux).
Regardons maintenant la préparation des données du jeu de données.
D’un jeu de données brut à un jeu de données héroïque pour un classificateur d’images
Avec mon scraper, j’ai collecté beaucoup (164000 environ) d’images sur le site Web Turo associées à leurs offres de voitures. C’est un bon nombre pour commencer, mais toutes ces images ne sont pas utilisables, par exemple, l’intérieur de la voiture.

Il y a beaucoup de ces images, donc je dois faire du nettoyage sur ce jeu de données brut.
Description du pipeline de nettoyage
Le processus derrière ce pipeline est de :
- Détecter tous les objets sur l’image du jeu de données brut
- Appliquer des règles basées sur les objets détectés dans l’image pour sélectionner les bonnes images
- Recadrer le véhicule sur l’image et le stocker dans un nouveau fichier
Voici une brève illustration du processus
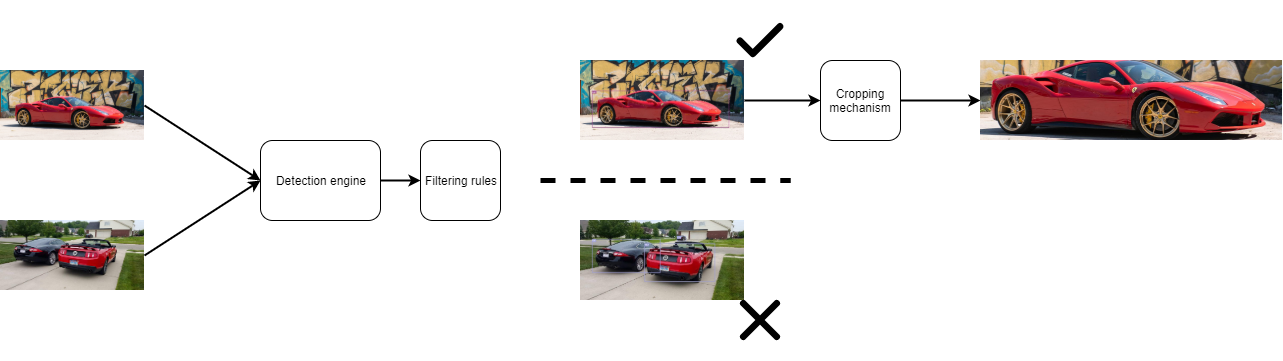
La partie la plus délicate de ce pipeline était le moteur de détection ; pour cette partie du pipe, j’ai décidé que je pouvais utiliser un modèle préfabriqué. Il existe une quantité importante de modèles qui peuvent être trouvés en ligne pour exécuter la tâche de détection d’objets sur une image.
L’implémentation qui semble la plus efficace à utiliser est celle faite par Chris Fotache sur Pytorch.
Pour les règles de filtrage, c’était simple ; une bonne image d’une voiture peut être définie avec :
- un seul véhicule (voiture ou camion) sur l’image
- l’indice de confiance de la détection du véhicule doit être supérieur à 90%
Après les règles de filtrage, il s’est avéré que seulement 57000 images étaient utilisables.
Voyons maintenant comment étiqueter ces images.
Étape finale : Redimensionnement et étiquetage
L’étape finale pour compléter le jeu de données est de redimensionner les images et d’avoir des étiquettes pour la classification.
Redimensionnement
De toutes ces images qui ont été sélectionnées, deux choses sont remarquables
- elles ont des tailles différentes (en termes de hauteur et de longueur)
- elles sont en couleur (donc elles ont 3 canaux pour les couleurs primaires)
Dans la figure suivante, il y a une représentation de la hauteur et de la longueur des images.
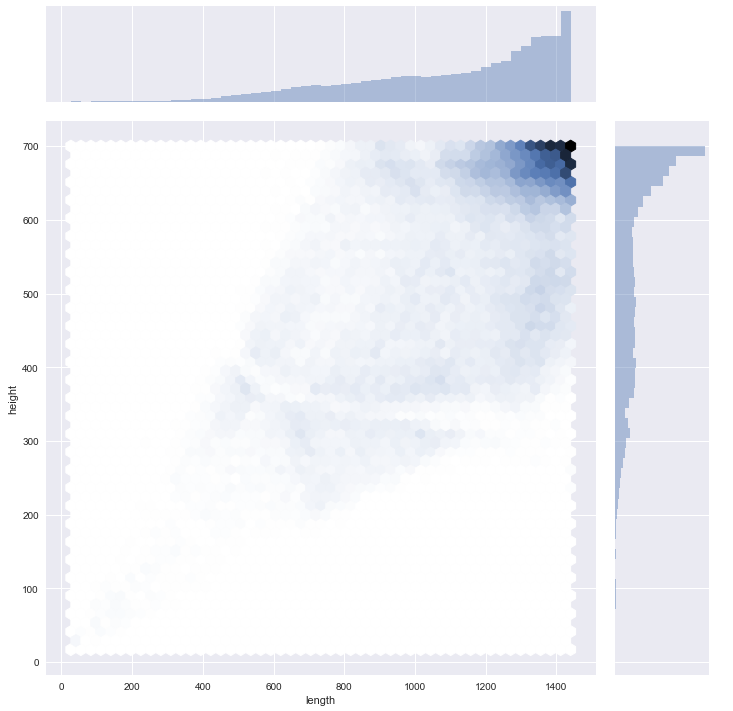
Les images ont des résolutions appropriées, mais je dois les uniformiser pour les rendre utilisables par chaque pipeline de classification. J’ai construit le morceau de code suivant pour redimensionner les images (et cette fonction peut les rendre en noir et blanc).
J’ai essayé plusieurs configurations de taille pour mon jeu de données en termes de pixels pour la hauteur et la longueur.
Regardons maintenant l’étiquetage.
Étiquetage
Il y a deux étiquetages évidents pour ce jeu de données :
- le fabricant avec 51 étiquettes possibles
- le modèle avec 526 étiquettes possibles
Dans la figure suivante, il y a une visualisation du nombre de modèles par fabricant.
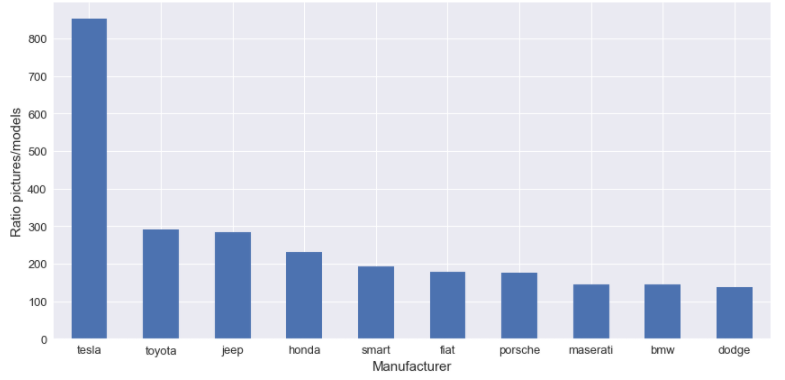
Comme nous pouvons le voir, il y a beaucoup de fabricants et de modèles, et c’est un départ difficile d’avoir autant d’étiquettes (je pense). J’ai décidé de construire mon “mécanisme d’étiquetage”.
J’ai construit deux types d’étiquetage :
- un pour un classificateur binaire
- un pour un classificateur multiclasse
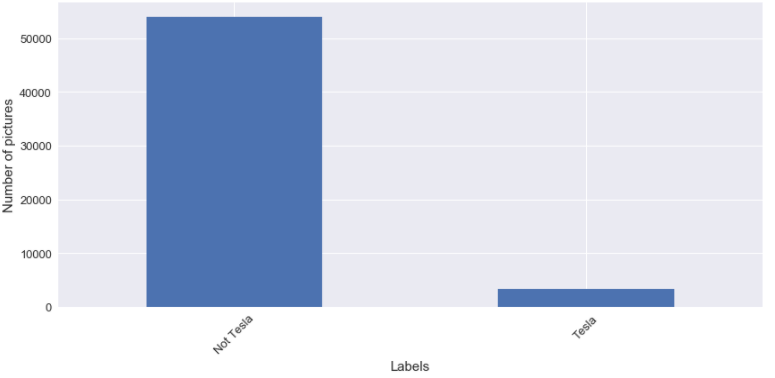
Pour le classificateur binaire, je choisis un fabricant spécifique et un modèle spécifique. Pour le fabricant, j’ai décidé de choisir Tesla ; la première raison est qu’il est tendance en ligne et la deuxième raison Tesla a un ratio inhabituel entre le nombre d’images pour le nombre de modèles disponibles, comme nous pouvons le voir dans la figure suivante.
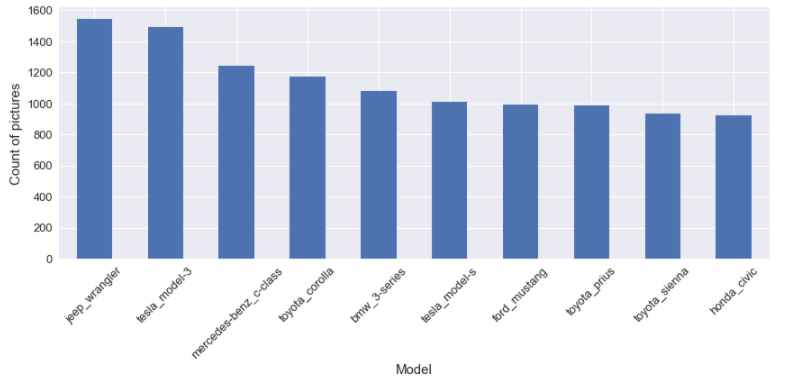
Pour le modèle, j’ai décidé de choisir la Ford Mustang parce que j’aime les Ford Mustang, rien d’autre. Mais soyons honnêtes, c’est l’un des modèles les plus populaires dans le jeu de données, comme nous pouvons le voir dans la figure suivante du top 10 des modèles les plus populaires.
Parlons du classificateur multiclasse ; pour ce cas, j’utilise une approche très simple pour l’étiquetage. L’idée est de prendre les X fabricants/modèles les plus populaires, et si le fabricant/modèle de l’image n’est pas dans le top X, son étiquette assignée est autre. J’ai construit les étiquettes pour les :
- top 10 fabricants/modèles
- top 25 fabricants/modèles
- top 50 fabricants/modèles
- top 100/200/400 modèles
Maintenant, beaucoup d’étiquettes différentes sont disponibles pour les images. Néanmoins, pour mon premier travail sur le classificateur d’images, je vais concentrer mon test avec les étiquettes binaires et le top 10 fabricants/modèles.
Pour compléter cet article, je veux juste parler de quelque chose, et c’est de l’équilibrage du jeu de données. Pour l’étiquette que j’ai sélectionnée, je peux vous dire que les classes à prédire ne sont pas du tout équilibrées. Dans les figures suivantes, il y a une illustration du déséquilibre du jeu de données.
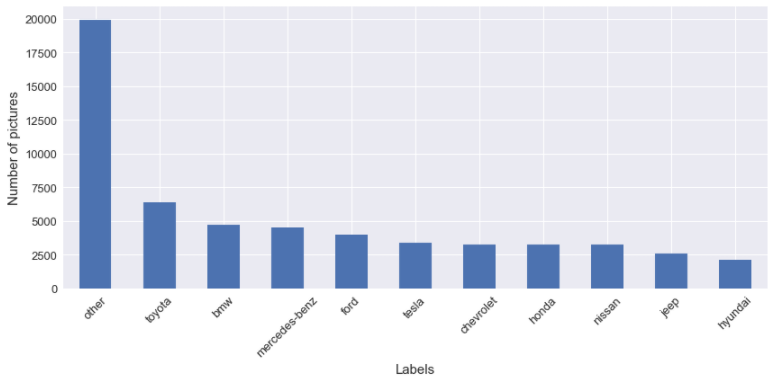
Quand je vais utiliser ces étiquettes pour la classification d’images, je vais tester l’impact d’équilibrer les classes pour l’entraînement.
Restez à l’écoute et n’hésitez pas à donner des commentaires.
Références
- Jeu de données MNIST — yann.lecun.com
- Walkthrough du classificateur de races de chiens — Medium / Towards Data Science
- Plateforme Turo — turo.com
- Stanford Cars Dataset — ai.stanford.edu
- Classifying car images using features extracted from pre-trained neural networks — Medium / Towards Data Science
- Predicting car price from scraped data — GitHub
- Beautiful Soup — crummy.com
- AWS DynamoDB — AWS
- Scrapin’ and Scrollin’ — michaeljsanders.com
- Object Detection and Tracking in PyTorch — Medium / Towards Data Science
- Dépôt example_webscraper — GitHub