
Optimisez votre workflow de machine learning avec weights and biases, mljar automl, hyperopt, shapash et evidently
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Je voulais écrire depuis quelques semaines sur des bibliothèques ml/ds que j’ai dans mon backlog de choses à essayer. Un article par bibliothèque était peut-être trop (et pas très dense), donc j’ai décidé de fusionner mes tests dans un article pour un cas d’usage afin de les tester et faire un rapide résumé dessus.
Dans cet article, vous aurez un test rapide (en shotgun) autour des bibliothèques suivantes :
- MLJAR Automated Machine Learning for Humans
- Hyperopt: Distributed Asynchronous Hyper-parameter Optimization
- shapash
- evidently
- weights and biases
J’appliquerai ces bibliothèques dans un cas d’usage simple (et mon cas d’usage classique pour tester des libs) et donnerai quelques retours.
Tout le code pour alimenter cet article peut être trouvé dans ce repository Github.
Configuration ML
Dans cette section, il y aura une description du cas d’usage utilisé pour tester ces bibliothèques. Mon cas d’usage est un héritage de mon MOOC que j’ai fait en 2016 sur Udacity, et c’est autour de la prévision de la consommation électrique quotidienne de la France ; vous pouvez trouver plus de détails sur cette expérience dans cet article.
Pour résumer cet article, il y a quelques points clés :
- La consommation électrique est très dépendante de la saison (le chauffage électrique est principalement utilisé en France)
- Les gens semblent consommer plus d’électricité un dimanche/samedi qu’en semaine.
Sur cette base, j’ai juste reconstruit le cas d’usage avec des données plus fraîches provenant de :
- Consommation électrique du portail rte, j’ai fait un dump jusqu’au 1er janvier (et agrégé les données au niveau quotidien)
- Données météorologiques de la source de données NASA POWER axées sur les 11 plus grandes villes et les températures minimales, moyennes, maximales à 2 mètres (degrés Celsius) plus les précipitations totales (mm)
À partir des données météorologiques, j’ai construit quatre caractéristiques qui sont une version pondérée de ces caractéristiques basées sur la population des villes ; vous pouvez trouver l’ETL dans ce notebook.
En termes de préparation, j’ai construit :
- Ensemble d’entraînement + ensemble de test qui représentent 80% et 20% des données entre 2015-2020 choisies aléatoirement
- Dataset 2020 qui sont les données de l’année 2020
Ce projet vise à voir comment nous pouvons construire un bon prédicteur de consommation d’énergie (et comment le faire efficacement avec ces bibliothèques).
Construire des modèles de base avec MLJAR automl
L’une des premières étapes pour construire un prédicteur est de construire des modèles de base qui sont faciles à mettre en place et un bon point de départ pour construire un meilleur prédicteur. Pour ce projet, la métrique d’évaluation principale sera le RMSE. Ces premiers modèles de base vont être :
- Prédicteur aléatoire (choisir une valeur entre le minimum et le maximum de la période d’ensemble d’entraînement aléatoirement)
- Prédicteur moins aléatoire (choisir une valeur entre le minimum et le maximum d’un sous-ensemble de l’ensemble d’entraînement basé sur le jour de la semaine et le mois)
- PTG: D’après la littérature, une régression par morceaux basée sur la température extérieure est un bon prédicteur (donc j’ai construit trois versions basées sur la température pondérée min, moyenne, max)
Enfin, et c’était le point de cette section, une autre approche pour construire des modèles de base qui peut prendre peut-être plus de temps mais sera plus difficile est d’utiliser des bibliothèques automl pour créer ces modèles. Pour ceux qui ne sont peut-être pas familiers avec ce concept, il y a un excellent article de Bojan Tunguz sur le sujet.
Pourtant, c’est laisser une bibliothèque ML faire de la recherche et des tests sur un jeu de données pour construire des modèles, il y a beaucoup de bibliothèques pour faire cela (H20 automl, auto-sklearn, autokeras) mais celle que je veux mettre en évidence est MLJAR autoML.
Il y a plusieurs aspects à ce package, mais leurs auteurs ont fait une belle infographie pour expliquer les fonctionnalités.
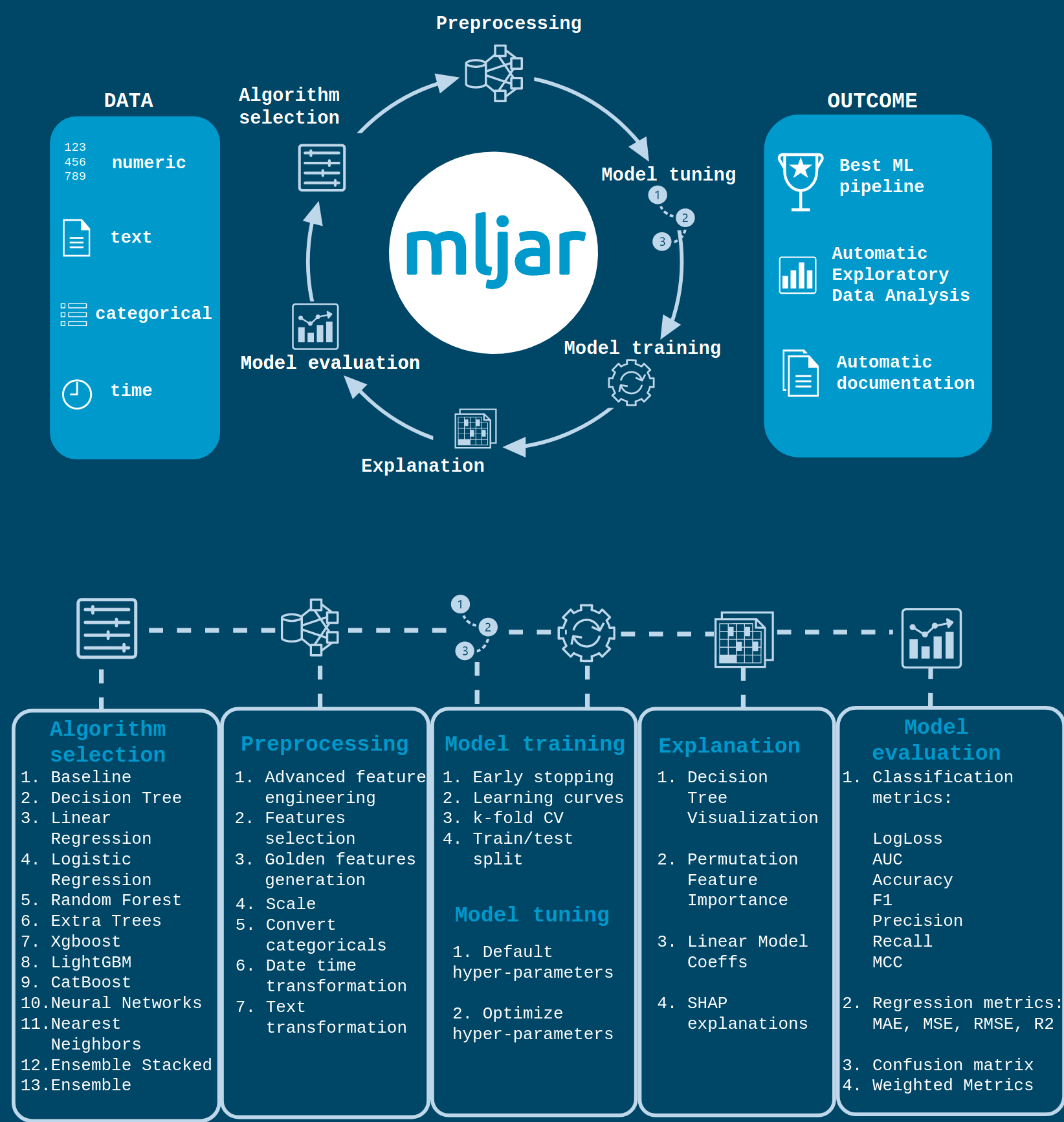
Vous pouvez trouver dans mon repository la partie que j’ai mise en place pour construire un modèle de base avec mljar (notebook et rapport), mais pour moi, les points critiques sur ce package sont :
- Facile à utiliser, vraiment quelques lignes de code sont utilisées pour le faire fonctionner
automl = AutoML() # mode=Explain, Perform, Compete
automl.fit(X_train, y_train)
predictions = automl.predict(X_test)
rmse = mean_squared_error(y_test, predictions, squared=False)
evaluation_metrics.append({'model' : 'mljar-bm', 'rmse' : rmse})
print('RMSE on the test-set:', rmse)- L’explicabilité des modèles produits par le système est disponible et est stockée dans un répertoire local (mettre un échantillon de la sortie de l’automl dans le repository)
- L’élément automl peut être configuré avec différents modes : Explain, perform, compute optuna. Ce mode peut être sélectionné en fonction du temps pour construire le modèle, et du niveau d’explicabilité attendu (cf documentation)
Dans ce cas, le meilleur modèle sera sélectionné (il semble être un modèle d’ensemble)
Alors voyons la comparaison des différents modèles de base produits.
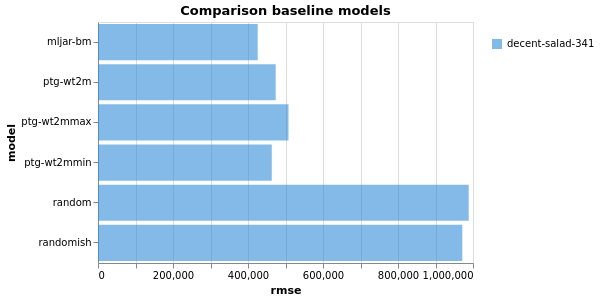
Toujours bon de voir que le PTG est toujours un bon prédicteur, mais le modèle produit par mljar fait un excellent travail.
Optimisation des hyperparamètres avec hyperopt
Dans le développement de modèles, l’exécution d’une recherche de grille pour trouver le bon ensemble de paramètres d’un modèle peut prendre du temps, et il existe différentes approches pour naviguer dans l’espace des paramètres qui peuvent être utilisées :
- Recherche de grille complète : tester tous les ensembles de paramètres dans l’espace de paramètres (pas efficace en temps)
- Recherche aléatoire : tester une quantité spécifique de paramètres sélectionnés aléatoirement dans l’espace (efficace en temps, mais manque d’opportunités)
Ces approches sont très standard et fonctionnent très bien, mais parfois vous avez des contraintes de temps pour faire des expériences, et à ce moment, une bibliothèque comme hyperopt peut être utilisée.
Ce package vise à utiliser la méthode bayésienne pour optimiser une fonction de perte (dans ce cas, basée sur le rmse) en ajustant les paramètres dans des directions spécifiques. Vous pouvez trouver plus de détails dans ce processus ici :
- Un article qui est derrière les approches TPE utilisées dans le package hyperopt
- Une explication générale du processus bayésien pour faire l’ajustement des hyperparamètres fait par Will Koehrsen
Dans le cas de la prédiction de la consommation électrique, il y a le notebook construit basé sur la documentation du package, et qui calcule la recherche sur 100 itérations pour un random forest regressor.
Ma recherche n’a pas apporté un excellent modèle pour construire la base de référence (ce n’était pas l’objectif).
D’un point de vue professionnel, cela fonctionne très bien, testé sur des projets au travail j’ai peut-être des réserves quand vous exécutez une application Spark mais reste un excellent package à avoir sous la main si vous êtes contraints en temps pour votre recherche (ce n’est pas le seul package qui peut faire cela, vous pouvez trouver ray tune par exemple).
Allons plus loin sur l’explicabilité du modèle.
Rendez votre modèle plus explicable avec shapash
Un autre aspect que j’ajoute récemment au travail était de travailler sur l’explicabilité de mes modèles de machine learning. Ma recherche m’a conduit à un package développé par la compagnie d’assurance MAIF (je ne m’attendais pas à écrire cela dans un article sur mon blog) appelé shapash.

Ce package offre la capacité de construire un niveau d’explainer au-dessus du modèle pour aider à expliquer l’explicabilité du modèle et la sortie de prédiction si nous revenons au cas de mon random forest regressor pour prédire la consommation électrique.
Il y a le notebook utilisé pour cette exploration de shapash.
J’utilise le meilleur modèle d’hyperopt avec toutes les caractéristiques précalculées ; du scikit learn, vous pouvez facilement extraire l’importance des caractéristiques dans le modèle (et shapash offre une excellente visualisation).
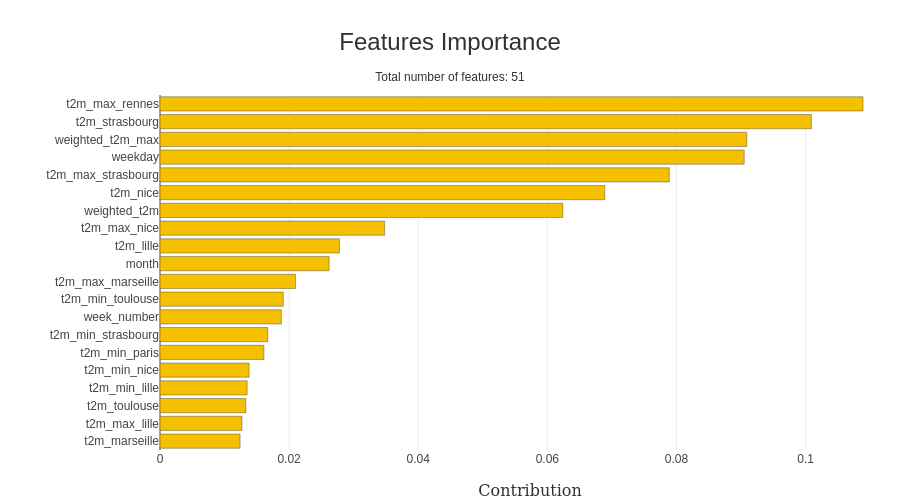
À remarquer que le prédicteur capte l’importance du jour de la semaine et des températures dans la modélisation. Une fonctionnalité excitante du package est de regarder la valeur spécifique dans le dataset x, comme dans cet exemple ; je me suis concentré sur le week-end.
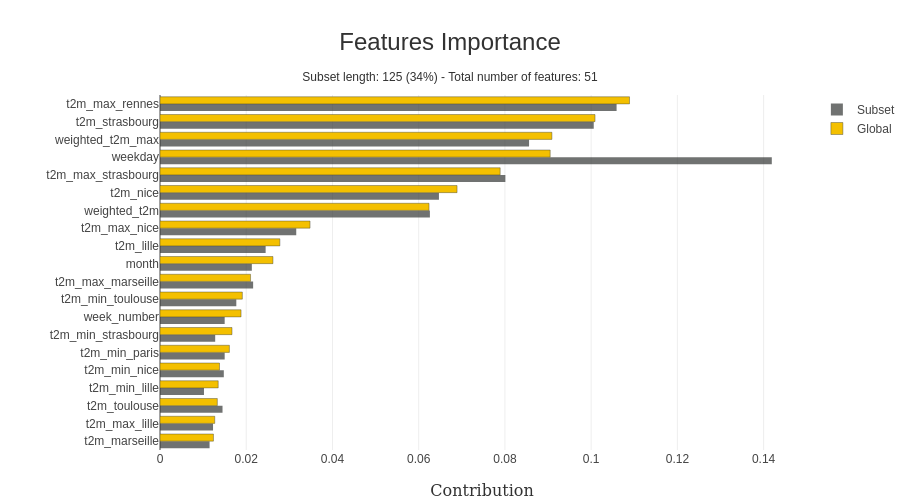
Comme nous pouvons le voir dans ce cas, le jour de la semaine est plus important que sur la représentation précédente. Une autre fonctionnalité utile si vous voulez creuser sur l’impact de la valeur directement d’une caractéristique spécifique, des graphiques de contribution peuvent être conçus par le package (il y a un exemple).
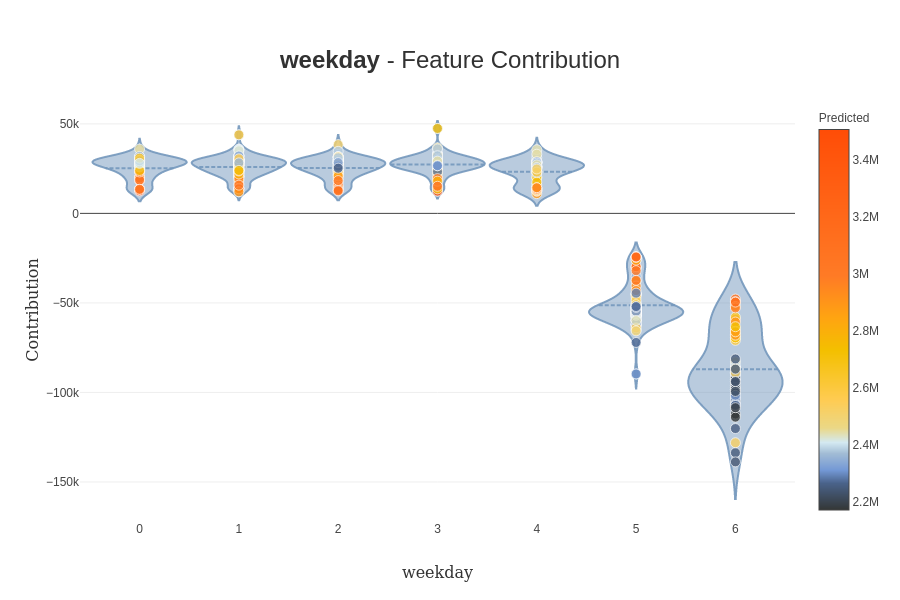
(toujours une bonne représentation de l’impact du week-end sur la prédiction).
Toute cette évaluation de l’impact est impactée par le framework utilisé en coulisses pour évaluer cet impact. Actuellement, deux frameworks peuvent être utilisés :
- SHAP: qui utilise les valeurs de Shapley pour construire l’impact des caractéristiques sur une prédiction ; il y a un bon article qui illustre ce package
- LIME: Une autre approche non basée sur les valeurs de Shapley, plus de détails ici
Si vous êtes intéressé par l’interprétabilité des modèles, vous devriez considérer le travail de Christoph Molnar. Il fait un excellent travail sur ce sujet (il est derrière une bibliothèque appelée rulefit qui peut être utile pour construire des modèles de base).
Pour conclure sur ce package, l’explicabilité peut être appliquée directement au niveau de la prédiction avec la capacité pour une prédiction spécifique d’avoir plus de détails dessus ; il y a une représentation de l’explicabilité pour une prédiction.
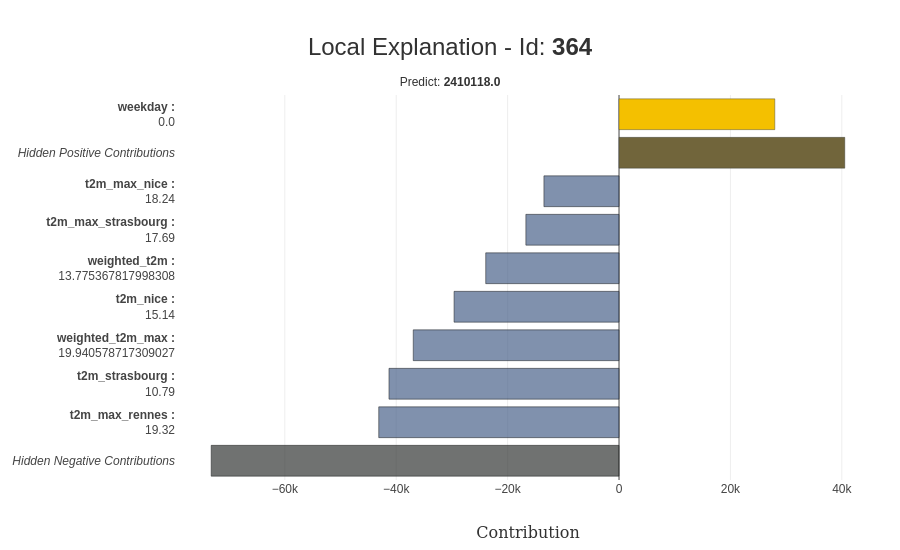
Une fonctionnalité cool est que cet élément explainer peut être sauvegardé et utilisé sur un objet prédicteur pour la prédiction en direct ; il y a un exemple sur les données de 2020.
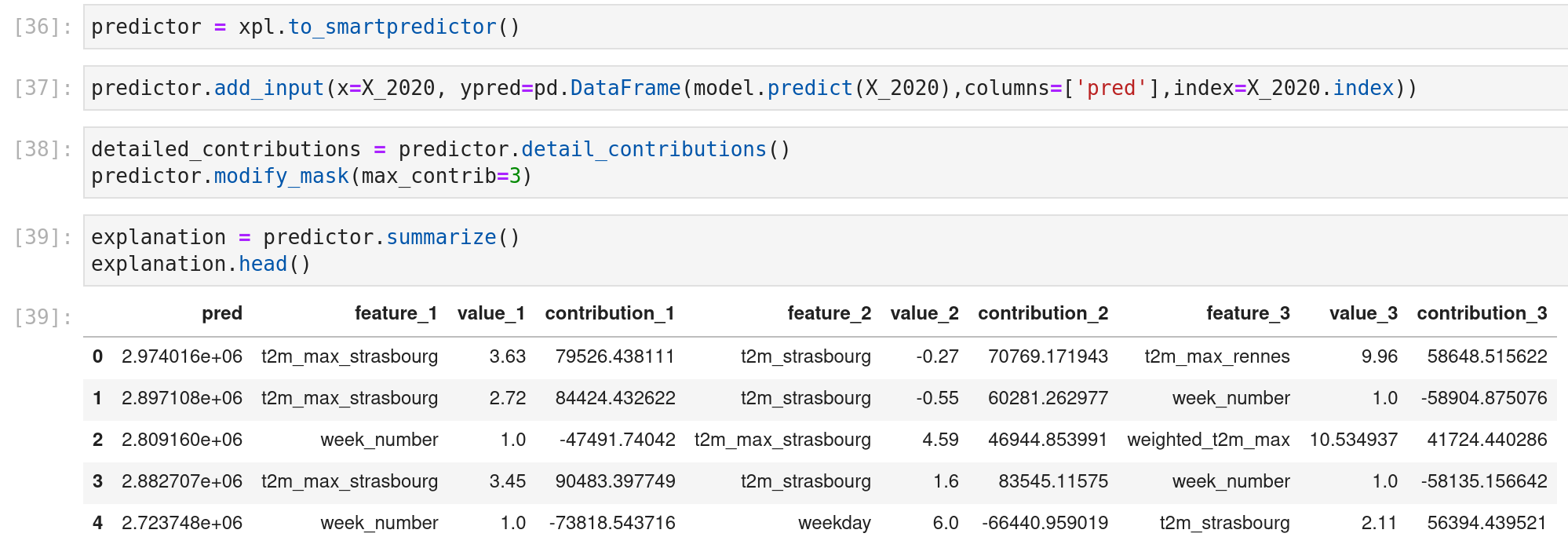
D’autres fonctionnalités pourraient être utiles pour vous (comme la petite application web ou le prétraitement des éléments), donc je vous invite fortement à jouer avec (et regarder le site web des projets open-source de MAIF ici ils font des choses cool).
Allons maintenant sur l’évaluation de la dérive du modèle et des données.
Évaluez vos données et votre modèle avec evidently
Un autre projet sur lequel je travaille au travail est le monitoring des pipelines ml. Je me concentre principalement sur la dérive des modèles. Dans mon flux, grâce à un de mes collègues, j’ai vu ce package qui développe une bibliothèque open-source autour de la dérive des données et des modèles appelée evidently.
![]()
Il y a une entreprise derrière ce package, mais c’est un outil open-source ; vous pouvez entendre l’un des cofondateurs dans ce datacast ; le package est assez simple à utiliser. Comme je l’ai dit précédemment, focus sur la dérive des données et des modèles, vous pouvez trouver l’expérimentation dans ce notebook.
Plongeons dans le rapport de données ; le notebook précédent produit un exemple ; l’idée de cela est de faire la comparaison entre un dataset de référence (dans ce cas, l’ensemble d’entraînement) versus un autre dataset (dans ce cas, l’année 2020) et voir s’il y a beaucoup de divergences (qui pourraient expliquer la variation du modèle dans la prédiction). Enfin, il y a une capture d’écran du rapport produit.
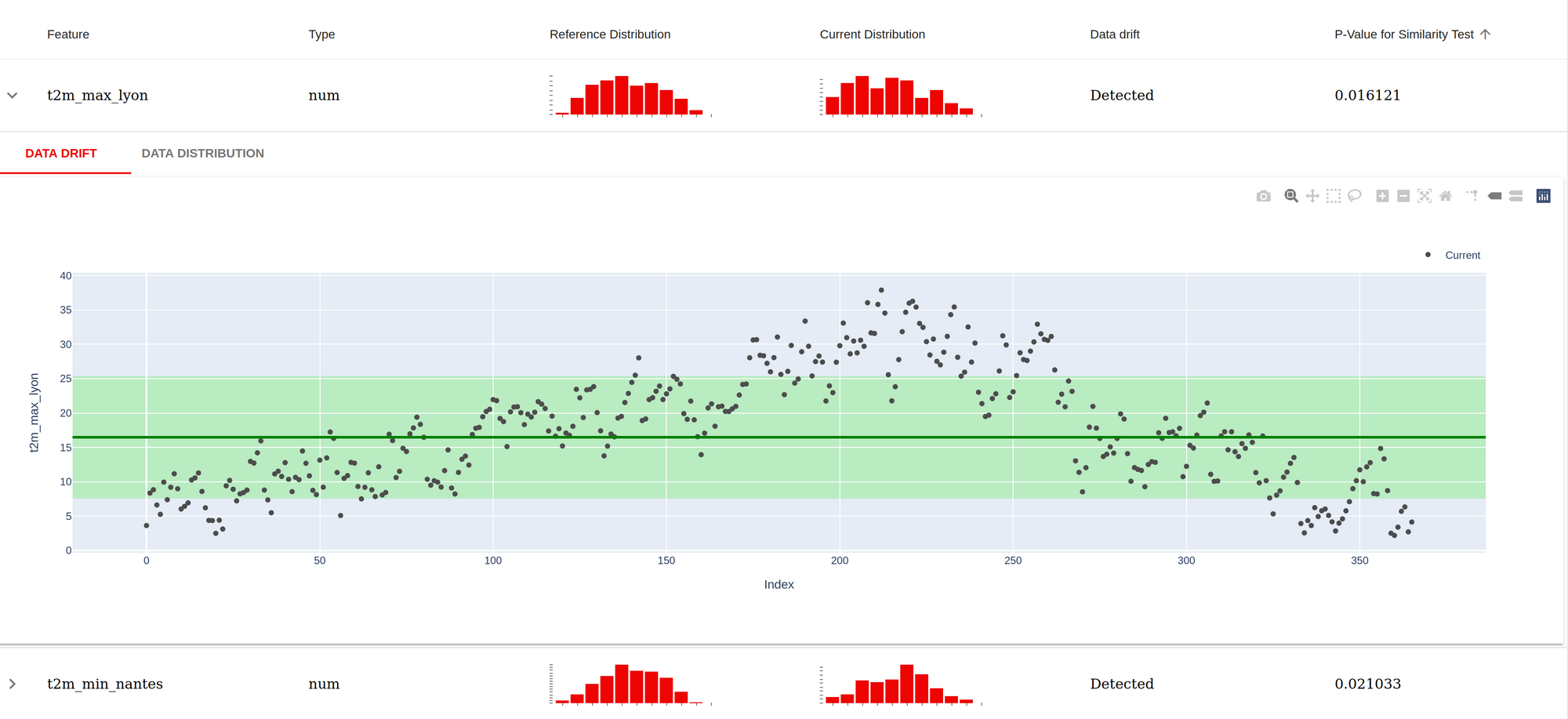
Pour chaque caractéristique utilisée dans le modèle, il y a une évaluation faite dans un test de similarité entre le dataset de référence et le dataset actuel (si la p-value est inférieure à 0.05, il y a quelque chose), comme prévu la température semble différente, c’est attendu car il y a cinq ans de données dans le dataset de référence contre un an de données). Il y a aussi quelques graphiques pour plonger un peu plus dans les datasets.
Le rapport de modèle est similaire, mais le rapport est plus évolué ; il y a un exemple ici. Les points critiques sur ce rapport sont :
- Les métriques d’évaluation traditionnelles pour un problème de régression sont affichées en haut.
- Comparaison sur plusieurs graphiques sur la prédiction versus les valeurs réelles
- La distinction entre les surestimations et les sous-estimations
La sortie de ce rapport n’est pas limitée à un fichier HTML ; elle peut être extraite dans un format JSON.
Ce package est récent, mais il y a beaucoup de bonnes visualisations et habitudes dedans. Par conséquent, je conseille aux gens de le regarder (ce n’est pas limité au travail de régression pour la classification aussi) car cela peut les inspirer pour leurs tableaux de bord (ou peut-être l’alimenter).
Soyez plus efficace pour construire votre pipeline d’exploration avec weights and biases
Enfin, sur cette exploration, j’ai testé un autre package appelé weights and biases qui fait beaucoup de bruit dans le monde ML (et pour une bonne raison appelé weights and biases. Ce package fait partie du package pour aider les data scientists à gérer le monitoring des expériences ml facilement et les aider à aller en production.
L’un des premiers aspects du package est d’enregistrer des informations ; vous pouvez enregistrer divers éléments à partir de données, modèle, table ou modèles. Il y a un rapide aperçu d’un code pour versionner un dataframe et un modèle (charger aussi).
# Log a dataframe
wandb.init(project='french_electrical_consumption', entity='jmdaignan')
data = [[row['model'], row['rmse']] for idx, row in dfp_evaluation_metrics.iterrows()]
table = wandb.Table(data=data, columns = ["model", "rmse"])
wandb.log({"comparison_baseline" : wandb.plot.bar(table, "model", "rmse", title="Comparison baseline models")})
# Log a model
run = wandb.init(project='french_electrical_consumption', entity='jmdaignan')
trained_model_artifact = wandb.Artifact('best_model_hyperopt', type='model', description='Best model from the hyperopt')
file_model = './data/model.pkl'
with open(file_model, 'wb') as file:
pickle.dump(model, file)
trained_model_artifact.add_file(file_model)
run.log_artifact(trained_model_artifact)
# Load a model
run = wandb.init(project='french_electrical_consumption', entity='jmdaignan')
model_at = run.use_artifact('best_model_hyperopt:latest')
model_dir = model_at.download()
#model_dir = './data'
with open(model_dir + '/model.pkl', 'rb') as file:
model = pickle.load(file)Cette fonctionnalité est très familière dans ce genre de package (comme vous pouvez le voir dans mon article sur mlflow). Mais l’un des avantages est que vous pouvez utiliser ces artefacts dans une belle UI pour concevoir des graphiques avec des données et écrire des rapports dans un style medium.
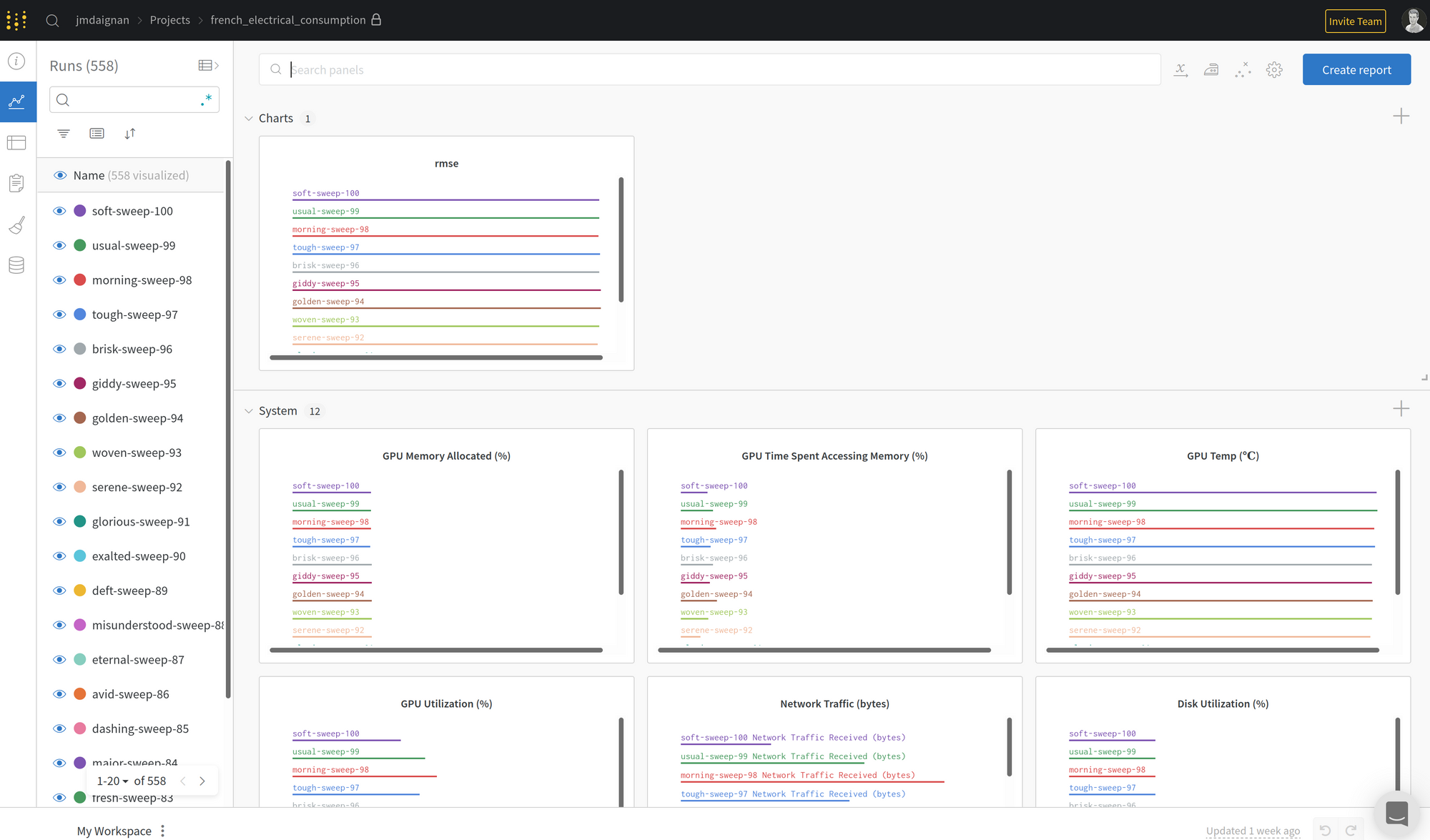
Une fonctionnalité remarquable de cette UI est le monitoring des performances de la machine qui exécute les expériences.
Une autre fonctionnalité que j’ai trouvée très intéressante est la fonctionnalité de sweep qui mélange la vision hyperopt pour le calcul et une très belle interface. Vous pouvez trouver l’expérience dans ce notebook, mais il y a une capture d’écran de l’UI.
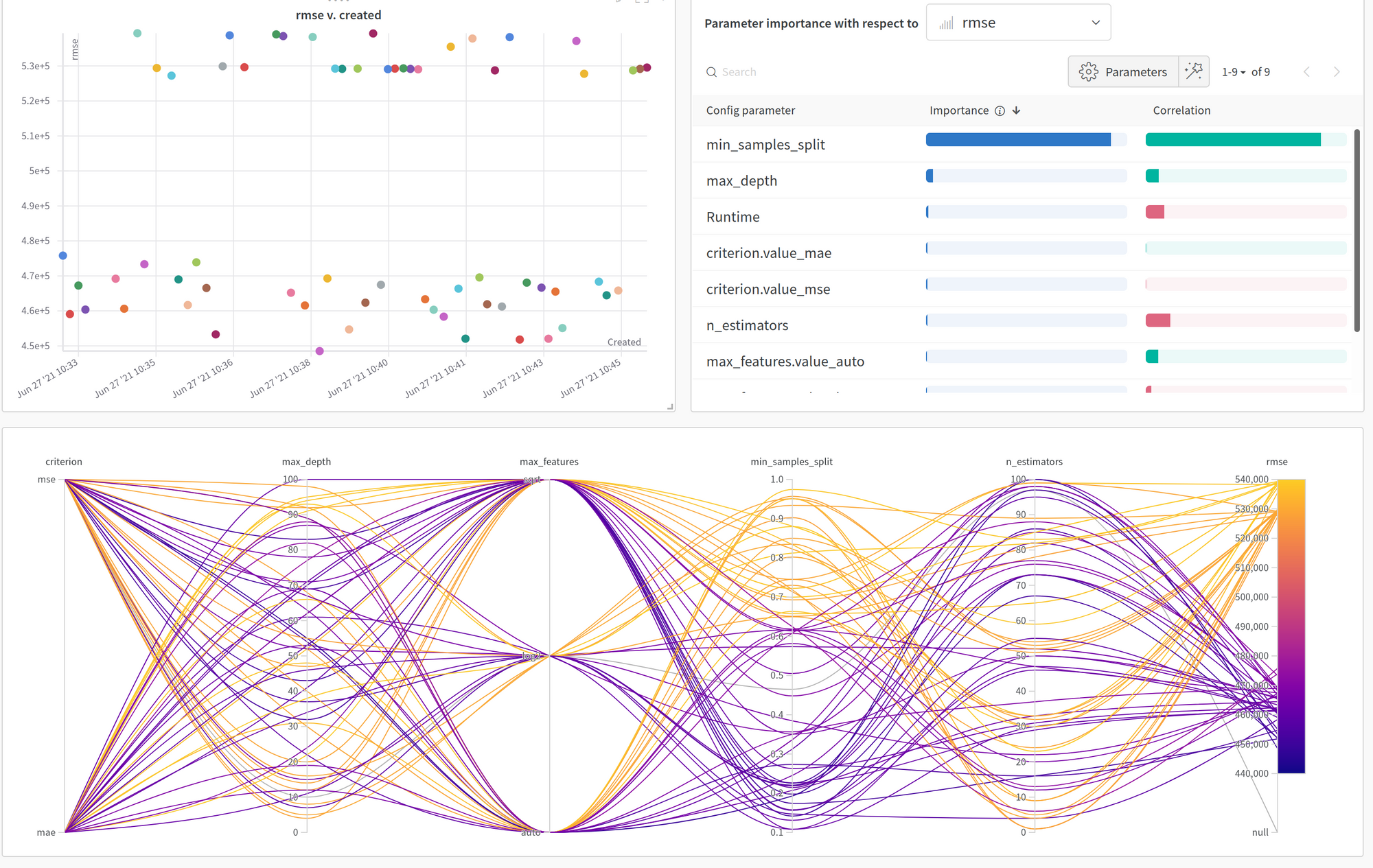
L’UI est facile à comprendre en utilisant le graphique de coordonnées parallèles pour étudier l’impact des paramètres sur la perte à optimiser. Mais la fonctionnalité remarquable que j’aime sur cette UI est les graphiques d’importance/corrélation en haut à droite ; pour l’importance des paramètres sur l’évolution de la perte, vous pouvez trouver les détails sur leurs approches dans cet article.
Globalement, weights and biases est un excellent package pour le monitoring ; je ne suis peut-être pas un grand fan du fait qu’il n’y ait pas de couche d’expérience sur un projet (projet> expérience > runs pourrait être mieux pour moi), mais c’est très efficace. Je vais juste peut-être souligner que pour un usage professionnel ; une licence doit être payée par utilisateur, donc soyez prêt (mais en fonction de la configuration de vos équipes ml cela pourrait valoir le coup)
Extra: Interface pandas avec les stockages AWS facilement avec data wrangler
Il y a un package que je n’ai pas utilisé dans ce projet, mais je voulais le partager ici parce que je l’ai trouvé très utile. Il y a un package d’AWS qui aide à connecter les dataframes pandas avec le stockage AWS (il y a un aperçu de code pour interfacer pandas avec divers services AWS)
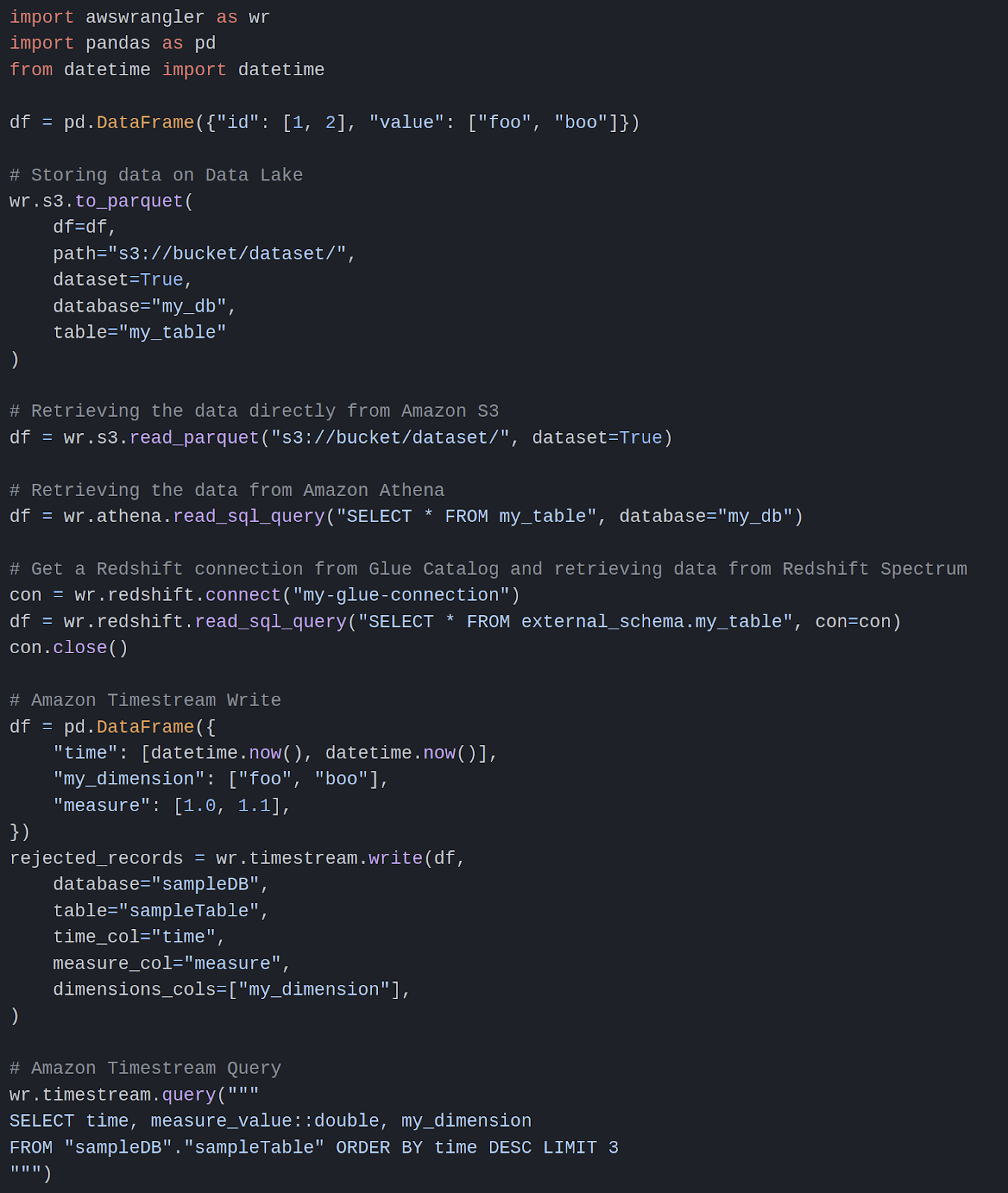
Rien de vraiment à dire ; si votre machine a suffisamment de droits sur les services AWS pour appeler, c’est un excellent package pour faire l’interface (pour moi, les seuls inconvénients sont la capacité de lecture manquante sur dynamodb).
Conclusion
J’espère que cet article vous a donné la curiosité de tester ces packages car ils peuvent rendre votre vie plus facile dans votre travail quotidien ML/DS.
Références
- MLJAR Automated Machine Learning for Humans — GitHub
- Hyperopt: Distributed Asynchronous Hyper-parameter Optimization — hyperopt.github.io
- shapash — GitHub
- evidently — GitHub
- weights and biases — wandb.ai
- repository Github — GitHub
- cet article — Medium / Towards Data Science
- portail rte — opendata.reseaux-energies.fr
- source de données NASA POWER — power.larc.nasa.gov
- ce notebook — GitHub
- RMSE — scikit-learn.org
- D’après la littérature — GitHub
- article de Bojan Tunguz — Medium / Towards Data Science
- H20 automl — docs.h2o.ai
- auto-sklearn — automl.github.io
- autokeras — autokeras.com
- MLJAR autoML — mljar.com
- notebook — GitHub
- rapport — GitHub
- un échantillon de la sortie — GitHub
- article — papers.nips.cc
- explication générale — Medium / Towards Data Science
- notebook — GitHub
- ray tune — docs.ray.io
- le notebook — GitHub
- SHAP — GitHub
- article — Medium / Towards Data Science
- LIME — GitHub
- le travail de Christoph Molnar — christophm.github.io
- rulefit — christophm.github.io
- ici — maif.github.io
- evidently — evidentlyai.com
- datacast — datacast.simplecast.com
- ce notebook — GitHub
- ici — GitHub
- article sur mlflow — Medium / Towards Data Science
- ce notebook — GitHub
- article — docs.wandb.ai
- package d’AWS — GitHub