
Cinq ans de préparation, mon parcours MLOps dans l'industrie du jeu vidéo
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Récemment, j’ai commencé à être impliqué dans l’organisation de différents meetups à MTL (pydata, mlops community); nous avons une grande fusion d’équipes autour du ML en production qui se déroule autour de moi chez Ubisoft, et j’ai participé à un podcast de la communauté mlops. J’ai donc pensé que ce serait un bon moment pour écrire un récapitulatif de mon expérience chez Ubisoft; cet article passera en revue mon parcours, mes responsabilités professionnelles, les défis rencontrés et les recommandations pour ceux qui cherchent à entrer dans le monde passionnant du ML en production.
Les origines de The Odd Dataguy
Avez-vous compris la référence?
J’ai obtenu mon diplôme en 2013 de Polytech Clermont Ferrand en ingénierie physique (spécialisation en énergie), où j’ai suivi un master orienté autour de la physique, comme vous pouvez vous y attendre, et l’informatique était assez loin de moi. Néanmoins, nous avions quelques cours autour du C (j’avais besoin de m’améliorer, et cela m’a fait détester la programmation) ou la gestion de bases de données. Dans ma dernière année, nous avons appliqué un peu de programmation autour de la modélisation de la thermodynamique et de la mécanique des fluides en Octave (et j’ai commencé à voir comment cela pouvait être utile, et j’ai aimé).
Machine learning sans le savoir
J’ai décidé pour mon projet de dernière année/stage de partir dans la voie de la modélisation pour travailler au CSTB à Sophia Antipolis, autour de la modélisation de la consommation d’énergie pour dimensionner le stockage d’énergie dans un contexte de quartier intelligent alimenté par des énergies renouvelables. J’ai donc principalement travaillé en Matlab et commencé à appliquer certaines techniques non supervisées (principalement trouver des personas à construire) pour creuser dans les données et créer des simulations de consommation (si vous êtes curieux et pas effrayé par le français, voici un lien vers la présentation.
Après ma graduation, j’ai décidé de continuer dans cette direction autour des applications de bâtiments intelligents, et j’ai travaillé pour différentes entreprises; la plus célèbre est le CEA pour construire des systèmes d’acquisition de données et des pipelines d’analyse de données pour créer des services autour de l’économie d’énergie (c’était principalement en Python).

Maison intelligente et au-delà
Après cela, je suis parti au Royaume-Uni (zut…) pour travailler chez EDF; j’ai été embauché en tant que data scientist (un mot nouveau en 2016) dans une équipe d’innovation numérique composée principalement de développeurs et de data scientists; j’ai travaillé sur ce sujet d’économie d’énergie et de bâtiment intelligent, mais un aspect important était également d’analyser les tendances dans le monde numérique et les données/ML pour proposer de nouvelles solutions pour le business autour de divers sujets (j’ai travaillé sur les recsys de plateformes e-learning, à l’analyse de données de centrales nucléaires).

Il y avait donc beaucoup de prototypage dans divers langages, et avec différents services (j’ai commencé à travailler dans le cloud avec AWS), cette expérience a été excellente pour travailler avec des data scientists qui m’ont poussé dans une nouvelle direction que mon diplôme en physique (et pour apprendre de nouvelles approches et un nouveau vocabulaire). Si vous voulez en savoir plus sur les projets à EDF ou au CEA, vous pouvez consulter mon LinkedIn, où j’ai expliqué les projets plus en détail.
Mon expérience avec la data science et le machine learning dans les secteurs de la maison intelligente et de l’énergie m’a bien préparé pour mon rôle chez Ubisoft, qui a commencé en juillet 2018, où j’aiderais à construire une plateforme ML pour l’entreprise et à opérer des pipelines de machine learning en production.
Façonner l’avenir : rejoindre une équipe de plateforme ML
Dans cette section, je partagerai mon expérience d’être membre d’une équipe chez Ubisoft qui construit une plateforme ML. La plateforme s’appelait auparavant Merlin mais sera bientôt rebaptisée avec un nouveau nom. Bien que je n’entre pas dans les détails techniques, j’ai fait une présentation sur le sujet à pydata MTL l’été dernier, et vous pouvez trouver le récapitulatif de ma présentation ici pour plus d’informations.
Le travail d’équipe fait fonctionner le rêve.
J’ai rejoint Ubisoft à l’été 2018, et l’équipe de la plateforme ML était initialement composée de deux personnes, un chef d’équipe et un chef de projet/produit/propriétaire. Au fil des ans, l’équipe a subi des changements importants, notamment une augmentation de l’effectif du côté des développeurs.
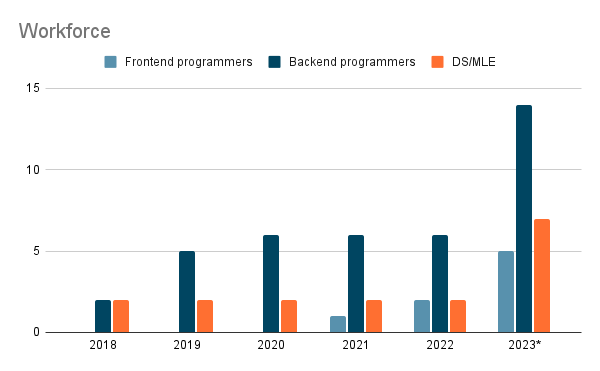
Comme discuté, la plupart de l’équipe est composée de développeurs avec
- Des programmeurs backend peuvent également être considérés comme des ingénieurs ML plateforme (si nous prenons la définition de Shreya Shankar). Ils travaillent sur tous les aspects liés à l’infrastructure, aux données et aux outils.
- Des programmeurs frontend sont responsables du portail qui est le point d’entrée principal de notre plateforme; ces rôles ont été ajoutés en 2021 et sont composés de 2 développeurs, un sur le front end et l’autre sur le back end.
- Une base de deux data scientists (DS) / ingénieurs machine learning (MLE) comme moi était là de 2018-2022
- En parallèle de tous les développeurs, vous avez des chefs d’équipe et de projet/produit/propriétaire qui organisent l’équipe.
En 2023, il y a eu une grande fusion au sein des équipes du bureau des données d’Ubisoft responsables du ML en production. En conséquence, plus de personnes ont été ajoutées pour construire une nouvelle plateforme ML pour étendre les cas d’usage actuels.
Faire partie d’une équipe dynamique qui s’efforce de fournir des produits et fonctionnalités de premier ordre est une expérience exaltante. Cependant, cela exige une nouvelle façon de travailler en utilisant de nouveaux outils, terminologies et processus comme Agile, Scrum et Jira. Le flux de travail de notre équipe a subi plusieurs transformations tout au long de l’année, mais quelques détails de la dernière itération avant la fusion méritent d’être partagés :
- Notre cycle de sprint était de deux semaines et divisé en trois parties - une pour les développeurs de plateforme, une pour les développeurs de portail et une pour les data scientists. Chaque sprint commence par une réunion de planification de sprint (pour chaque partie de l’équipe), se termine par une revue de sprint ouverte aux utilisateurs internes, et enfin, une réunion rétrospective de sprint.
- Nous avons également une réunion hebdomadaire pour assurer une coordination et une communication fluides de l’équipe.
- Chaque story est notée en fonction de la complexité, variant entre 1, 2, 3 et 5. La complexité de la tâche détermine le nombre de points et non le temps requis. Par exemple, une tâche simple comme l’envoi d’un email se verrait attribuer un score de 1, tandis qu’une tâche plus complexe nécessitant plusieurs jours de codage se verrait attribuer un score de 5.
En tant que l’un des data scientists de l’équipe, je suis activement impliqué dans le test de nouvelles fonctionnalités et dans la fourniture de commentaires pour assurer l’amélioration continue de notre produit.

Explorer le paysage mlops
Participer à une plateforme ML est une excellente opportunité pour explorer et tester de nouvelles technologies qui peuvent aider à accélérer le développement de la plateforme. Cependant, le paysage technologique est en constante évolution et encombré, et choisir les meilleurs outils qui conviennent à vos besoins est difficile.

Pour naviguer dans ce paysage, je recommande de lire des articles de Lj Miranda et Mihail Eric, où ils parlent de leurs expériences de navigation et de classification de ces types d’outils.
Chez Ubisoft, j’ai travaillé avec diverses technologies et packages, y compris des solutions open-source comme mlflow et metaflow, des services gérés comme Arize.ai (sur lequel je prévois d’écrire bientôt), et des services ML gérés dans le cloud comme AWS sagemaker.
En tant qu’équipe, notre objectif est d’évaluer la valeur de chaque outil testé et le coût d’intégration estimé du point de vue à la fois d’un utilisateur de plateforme (comme un data scientist) et d’un constructeur de plateforme (un développeur). Nous avons d’abord testé ces outils avec des données ouvertes pour obtenir des informations, puis nous sommes passés aux cas d’usage réels d’Ubisoft pour évaluer leur efficacité plus en profondeur.
Construire une plateforme ML peut être intimidant, et les organisations doivent souvent choisir entre construire et acheter leurs solutions. Ce débat soulève plusieurs questions et préoccupations qui doivent être abordées avant de se lancer dans un tel projet.
Lors d’une récente table ronde sur les systèmes de recommandation organisée par Tecton, Jacopo Tagliabue, un expert ML, a partagé ses réflexions sur les stratégies de construction et d’achat autour d’une plateforme ML. De plus, il a fourni un aperçu de la stratégie présentée dans le déploiement d’un système de recommandation.
Voici un aperçu de la stratégie présentée par Jacopo dans un schéma.
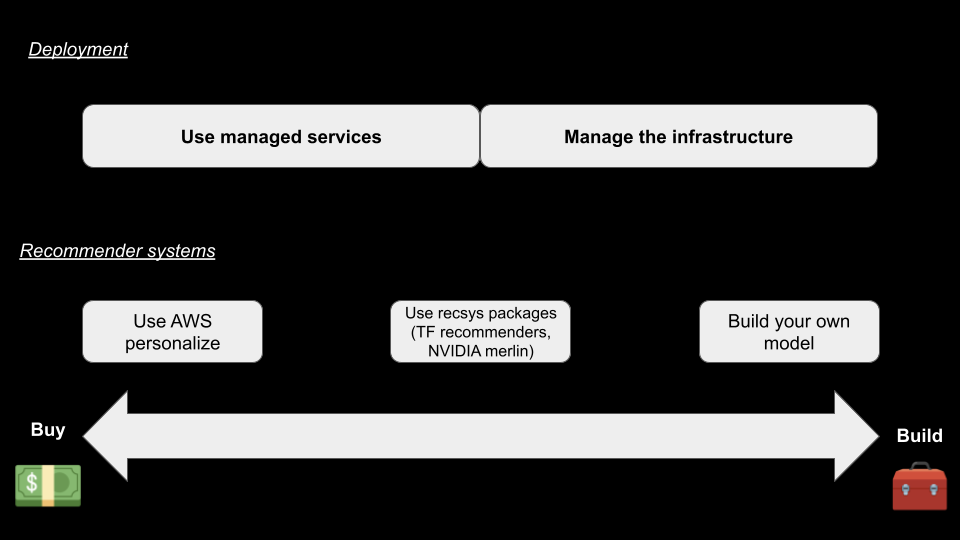
Chez Ubisoft, nous nous concentrons sur la construction de nos modèles en utilisant des frameworks comme Spark MLlib ou TensorFlow, mais en ce qui concerne le déploiement, nous sommes plus sur la gestion de notre propre infrastructure d’une certaine manière.
Le point clé de Jacopo était que la plupart des entreprises devraient commencer avec une approche ACHETER puis passer à une approche CONSTRUIRE mais ne jamais revenir en arrière (sauf s’il y a des circonstances extrêmes). Ce conseil s’aligne avec notre expérience chez Ubisoft et pourrait être précieux pour d’autres organisations naviguant dans la même décision.
Si vous voulez en savoir plus sur ce sujet, je recommande de lire l’excellent chapitre de Chip Huyen sur les stratégies de construction et d’achat dans son livre Designing Machine Learning Systems.
Parlons de la partie amusante d’une plateforme ML, le support client.
Soutenir les clients internes
Construire une plateforme ML pour les data scientists et les ingénieurs ML peut être difficile, surtout en ce qui concerne l’adaptation aux niveaux variables d’expertise technique des utilisateurs.
Récemment, Spotify a publié un article qui met en lumière leurs stratégies autour du ML en production. Ils ont construit un schéma qui décrit les différents rôles impliqués dans un projet ML en production. Cependant, j’ai trouvé l’axe un peu flou, alors j’ai créé ma propre version.
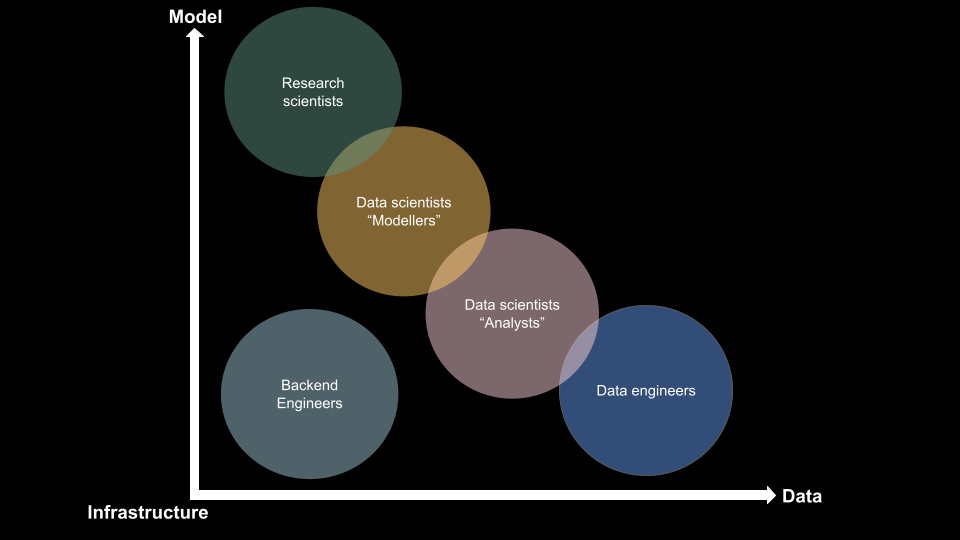
À mon avis, un projet ML en production implique trois éléments principaux : les données, le modèle et l’infrastructure. Différents rôles gravitent autour de ces éléments, notamment :
- Ingénieurs Backend : Développeurs responsables de tous les éléments nécessaires pour construire/utiliser des données et construire/utiliser des modèles.
- Chercheurs : Experts concentrés sur l’exploration de nouveaux modèles et algorithmes pour améliorer les performances du pipeline ML.
- Data Scientists (Modélisateurs) : Professionnels qui se spécialisent dans la modélisation de phénomènes dans un ensemble de données et ont une boîte à outils étendue pour soutenir leur travail.
- Data Scientists (Analystes) : Experts qui se concentrent davantage sur l’analyse des données que sur la modélisation.
- Ingénieurs de données : Développeurs qui travaillent principalement avec les données, l’ETL et l’organisation des données.
Cependant, où un ingénieur ML s’intègre-t-il dans ce schéma ? Différentes visions s’affrontent sur cette question.
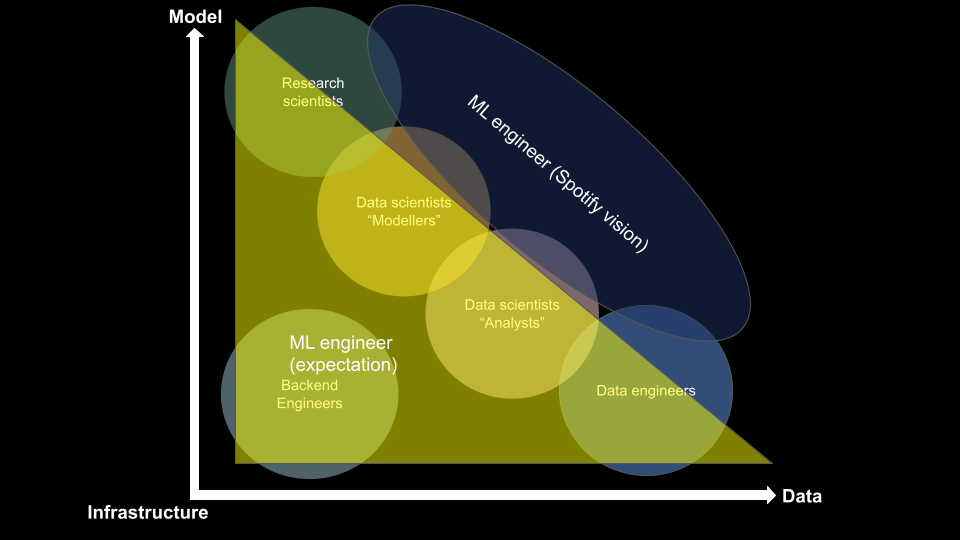
Il existe deux visions différentes en ce qui concerne les attentes du rôle d’un ingénieur ML :
- La première est une approche “touche-à-tout”, où un ingénieur ML est censé gérer tout, de l’infrastructure et des données au développement de modèles. Cette approche est bien illustrée dans un article de Chip Huyen, où elle discute du rôle d’un data scientist full-stack.
- La vision de Spotify démontre que la deuxième approche se concentre sur les données et le développement de modèles et abandonne l’aspect ingénierie backend.
Bien que la vision de Spotify soit bonne, le rôle d’un ingénieur ML s’apparente davantage à une pieuvre, avec la tête et le corps dans le rôle de modélisateur de data scientist et des tentacules atteignant des cercles spécifiques en fonction des préférences et de l’expérience de l’individu.

Pour s’assurer que la plupart des utilisateurs DS/MLE comprennent notre plateforme ML, nous avons mis en œuvre diverses approches, notamment :
- Mettre à jour régulièrement une documentation facilement accessible intégrée directement dans notre portail.
- Construire des pipelines d’exemples de bout en bout pour montrer comment la plateforme peut être utilisée dans des projets simples.
- Envelopper les outils MLOps derrière des fonctions pour faciliter l’intégration de nouveaux outils à l’avenir et permettre aux utilisateurs de se concentrer sur les fonctionnalités les plus critiques de l’outil (comme nous l’avons fait avec mlflow).
- Utiliser des conférences internes pour promouvoir la plateforme et ses fonctionnalités auprès d’autres équipes #EveAngelization (les Français comprendront).
Plongeons dans mon travail quotidien en tant que DS/MLE chez Ubisoft.
Concevoir et opérer des pipelines de machine learning en production
En tant que DS/MLE responsable de la construction de systèmes de recommandation dans un contexte batch pour les jeux, mon travail quotidien implique principalement :
- concevoir des processus d’événements : Obtenir le bon événement de la télémétrie et le rendre utile dans un pipeline ML
- explorer de nouveaux algorithmes : Choisir les bonnes fonctionnalités et hyperparamètres pour que le modèle fasse les bonnes prédictions
- déployer et opérer des pipelines : Avoir une base de code qui peut construire des prédictions et être surveillée
- surveiller les performances : Avoir un mécanisme d’alerte en place pour détecter les anomalies dans les données ou les prédictions
- effectuer des expériences en direct pour tester de nouveaux modèles et hypothèses.
Déployer des applications comme celles-ci est intense à des moments spécifiques, particulièrement pendant les sorties de fonctionnalités et les migrations de données ou d’infrastructure. Après le déploiement, c’est principalement de la maintenance et des tests réguliers pour réévaluer l’utilité d’utiliser le ML pour une fonctionnalité spécifique en termes de coût vs gain.
J’ai brièvement abordé mon travail parce que chaque point pourrait être un article en soi, mais si vous voulez en savoir plus, écoutez ma participation au podcast de la communauté mlops.
La section suivante discutera des défis et des leçons apprises de mon expérience.
Ready Player ML : Défis et leçons apprises
Ce seront plus de gros points que des sections structurées, comme précédemment, alors attachez votre ceinture.
Évaluation des systèmes ML au fil du temps : Pour celui-ci, je vais citer ce tweet d’Eugene Yan, un expert recsys chez Amazon.
D’accord avec cela; il est essentiel de garder un œil sur votre pipeline et d’évaluer régulièrement les performances du modèle pour voir s’il vaut la peine d’exécuter ce pipeline et toujours valable après X mois (analyse coût VS gain). Dans l’industrie du jeu vidéo, comme vous pouvez vous y attendre, un jeu peut atteindre un plateau après quelques mois et piquer à des moments spécifiques de l’année (comme Noël), donc choisir d’activer certaines fonctionnalités ML est essentiel.
L’industrie du jeu vidéo est d’abord guidée par la créativité : À la base, les jeux vidéo ne sont pas conçus par les données ou le machine learning. Au lieu de cela, ils sont construits pour offrir aux joueurs du plaisir, de la créativité et des expériences uniques. Cependant, construire autour des données et du machine learning est un développement récent dans l’industrie du jeu vidéo, et Ubisoft progresse dans ce domaine.
Il y a aussi des défis liés au cycle de vie du jeu; il doit passer certains jalons et priorités. Cette approche peut entraîner des retards dans la sortie ou l’annulation de certaines fonctionnalités. Incorporer le machine learning dans les jeux vidéo nécessite de la flexibilité et une collaboration étroite avec les développeurs de jeux pour démystifier l’utilisation de ces technologies.
Si vous êtes curieux d’en savoir plus sur le cycle de vie du développement de jeux, il y a un excellent article d’Ubisoft ICI qui explique les différentes phases de la conception, préproduction, production et opérations (en général, nous sommes plus impliqués dans les phases de production et d’opérations), avec également cette vidéo.
L’évolutivité d’abord : L’une des premières choses que j’ai apprises lors du déploiement de pipelines de machine learning était de tester l’évolutivité. Travaillant principalement avec Spark, avant de libérer une fonctionnalité prédictive comme un système de recommandation (dans un contexte batch), l’une des vérifications que j’effectue est de m’assurer que le pipeline peut gérer la charge.
Pour tester l’évolutivité, j’exploite les données d’utilisation d’autres jeux Ubisoft concernant les utilisateurs quotidiens/mensuels et j’exécute le pipeline sur des données factices 1-10 fois le volume des jeux les plus populaires. Cette approche fournit sécurité et confort pour le client qui commande la fonctionnalité prédictive. Il est essentiel de tester la partie machine learning (comme faire des inférences) et la partie ETL.
Commencer simple : Selon la première règle du guide du ML en production de Google, il est essentiel de commencer petit et simple au lieu de sauter directement dans des modèles et techniques complexes.
Par exemple, lors de la construction d’une fonctionnalité de recommandation, on pourrait commencer par une liste basée sur la popularité ou une simple matrice d’association avant de plonger dans l’ingénierie de données lourde et la modélisation avec des forêts aléatoires ou des techniques d’apprentissage profond. C’est particulièrement important dans l’industrie créative des jeux vidéo, où construire une culture autour des données et du machine learning est encore relativement nouveau (construire simple et brancher rapidement).

Si vous voulez en savoir plus sur ce concept, “Commencer simple” Eugene Yan a écrit un excellent article sur le sujet avec de nombreux témoignages et le concept d’heuristiques.
Les données sont votre ami avant votre modèle : Les données jouent un rôle critique dans MLOps, et il y a plusieurs aspects essentiels à considérer, tels que l’exploration des données, le nettoyage, la visualisation, l’ingénierie des caractéristiques, la division, le prétraitement et la surveillance. Investir du temps et des efforts dans le traitement des données peut avoir un impact significatif sur les performances de vos modèles. De plus, travailler en étroite collaboration avec les analystes de données garantit que vous utilisez et traitez efficacement les bonnes données.
Cependant, il est essentiel d’être prudent quant à la qualité des données et de ne pas s’appuyer uniquement sur les contrôles de qualité de votre fournisseur de données. Au lieu de cela, il est recommandé d’effectuer vos propres vérifications à chaque étape du pipeline ETL ou ML pour garantir l’exactitude et la fiabilité de vos données. Cette diligence raisonnable peut vous aider à faire de meilleures prédictions et à éviter des erreurs coûteuses.

Baissez vos attentes sur une plateforme ML: De mon point de vue, n’attendez pas qu’une plateforme ML résolve tous vos problèmes dès le départ. Stefan Krawczyk a une excellente analogie, où une plateforme devrait être vue comme “tout ce sur quoi vous construisez” - dans ce cas, une application ML.
J’irai plus loin en trouvant une métaphore qu’une plateforme ML dans une entreprise est comme un atelier dans un club de bricolage. Il y a quelques déclarations liées à cette métaphore :
- “Je veux cette technologie et celle-là sur votre plateforme ML” - Attendez-vous qu’un atelier ait tous les outils possibles disponibles ? Cela n’évolue pas en termes de coût et de maintenance, et gardez toujours à l’esprit, pourquoi avez-vous besoin de cet outil/technologie ?
- “Vous n’offrez pas cette fonctionnalité, je ne peux pas travailler” - Ne soyez pas arrêté par cela et trouvez votre chemin. Du côté ML, avoir les algorithmes de pointe les plus récents est facultatif pour apporter de la valeur avec le ML. Du côté MLOps, exploiter certains outils initialement non faits pour cela peut apporter une valeur rapide, comme utiliser une épingle à cheveux pour tenir un clou (VS un porte-clou).

Cette approche montre le besoin de l’équipe derrière une plateforme ML, et ils peuvent trouver le bon outil à apporter à la plateforme. De plus, pour tous ceux qui construisent une plateforme ML :
- “Ne concevez pas une plateforme sur des cas d’usage hypothétiques”; vous perdrez du temps et de l’énergie pour rien.
- “Ne vous laissez pas guider uniquement par les articles et les blogs technologiques”. Je vais paraphraser un ingénieur de Netflix qui a dit lors d’une conférence, “Une plateforme ML devrait être conçue par les besoins business et NON par les attentes DS/MLE/DEV.”
87% des projets ML ne vont pas en production : … parce que vous n’êtes pas amis avec les bonnes personnes. Cette statistique est souvent citée dans les discussions sur le machine learning en production, et provient d’un article de VentureBeat. Bien qu’il soit vrai que les professionnels MLE/DS devraient être proches du business pour comprendre le contexte et accéder aux données nécessaires pour l’intégration ML, ce n’est qu’un côté de la pièce.
Vous devez également avoir une bonne relation de travail avec le programmeur qui intégrera l’API de votre application. Peu importe à quel point votre API est bien documentée et facile à utiliser, le programmeur qui l’intègre détermine finalement si le projet arrive en production ou non. Par conséquent, il est crucial de leur offrir du support à travers des démos, des tours personnels et une implication dans les discussions liées au business pour leur montrer l’impact de leur travail sur l’entreprise.
Construire ou acheter, la question éternelle : Il y a quelques questions qui peuvent être connectées à ce sujet, telles que :
- “Dois-je construire une plateforme ML ?” Honnêtement, cela dépend de votre budget et de votre industrie. Je pense qu’il est préférable de commencer avec des services gérés, d’évaluer le coût et de peser les compromis avant de décider de construire quelque chose.
- “Si je construis une plateforme ML, devrais-je avoir des data scientists dans mon équipe ?” Bien sûr, vous avez besoin d’utilisateurs expérimentés, mais s’ils devraient être dans votre équipe est plus une décision organisationnelle (et devrait être basée sur des cas d’usage réels).
- “Si je construis une plateforme ML, devrais-je embaucher des développeurs intéressés par le ML ?” C’est un plus, mais en 2023, c’est loin d’être obligatoire (surtout quand on peut tout configurer pour le ML en quelques clics dans le cloud).
Pour conclure, voici quelques ressources et personnes que j’ai trouvées intéressantes pour en savoir plus sur le machine learning en production.
Codes de triche pour MLOps
Tout au long de cet article, j’ai partagé divers articles pour soutenir mes explications. Cependant, j’aimerais prendre un moment pour mettre en évidence certaines ressources spécifiques et individus qui peuvent vous aider à en savoir plus sur MLOps et le machine learning en production.
Sites Web
- Made with ML: un site web construit par Goku Mohandas qui partage des connaissances sur le domaine du machine learning en production.
- Full stack deep learning: Un site web qui promeut un cours gratuit et un bootcamp autour de l’exploitation du ML en production, avec un fort accent sur l’industrialisation des modèles d’apprentissage profond.
- Udacity: Une plateforme d’e-learning qui offre le Programme Nanodegree d’Ingénieur Machine Learning, qui fournit une base raisonnable pour comprendre le monde du machine learning.
- Kaggle: Une plateforme populaire de data science et machine learning proposant des ensembles de données, des compétitions et du code pour apprendre et améliorer les compétences.
- Blogs techniques : Ressources d’entreprises où elles partagent de bonnes pratiques, comme celui d’Airbnb, Etsy ou DoorDash
Personnes
- Eugene Yan (Twitter, site web): L’un des meilleurs contributeurs DS/ML en ligne avec un style excellent et efficace. Il est intéressant de noter qu’il lance toujours des threads sur Twitter pour obtenir des contributions de ses followers, ce qui en fait un excellent endroit pour apprendre de nouvelles choses.
- Chip Huyen (Twitter, Site Web): Derrière un excellent site web et livre où elle partage son point de vue sur l’industrialisation des solutions ML. Elle est également instructrice dans le cours de conception de systèmes machine learning de Stanford, qui est un point de départ parfait.
- Jacopo Tagliabue (Twitter): A travaillé chez Coveo avant (son entreprise d’origine a été rachetée par Coveo) et travaille maintenant sur de nouveaux projets. Très présent sur différents podcasts et conférences, mais son travail le plus intéressant est l’un de ses articles à RecSys 2021 sur le fait de ne pas rendre les pipelines trop complexes pour le ML en production.
- Ronny Kohavi (Twitter): Travailler chez Ubisoft m’a poussé à faire des tests AB en direct, et il est l’un des grands noms de l’expérimentation et des tests A/B. Il a travaillé pour des entreprises comme Microsoft et Airbnb, donc c’est la personne à suivre si vous voulez en savoir plus sur ces sujets. De plus, il a participé à un livre sur le sujet des tests AB.

Meetups/podcasts
- MLOps community: Une excellente communauté avec d’excellents fondateurs/animateurs où vous écouterez toujours de bonnes choses dans leur slack ou podcast
- Apply tecton conference: Conférence en ligne régulière autour du ML en production où les praticiens partagent leur expérience
- Podcasts d’entreprise : comme le blog technique, il y a d’excellents podcasts dirigés par certaines entreprises comme Gradient Dissident de weight and biases ou les podcasts techniques de Deezer
- Pydata Youtube: Un endroit où les organisateurs de pydata partagent des enregistrements de diverses éditions partout dans le monde; l’une de mes plus grandes découvertes a été cette vidéo de hello fresh autour de MLOps
Niveau final
En conclusion, réfléchir à mes cinq ans (environ) d’expérience chez Ubisoft a été une expérience perspicace et amusante. J’ai appris de nombreuses leçons précieuses sur le machine learning en production, comme acheter avant de construire des composants de plateforme ML, commencer simple la partie ML, évaluer régulièrement votre pipeline et éviter le FOMO autour des dernières techniques ML.
En regardant vers l’avenir, je suis enthousiaste de voir où l’industrie ira dans les cinq prochaines années, en voyant les percées récentes avec chatGPT, dalle, etc. Alors que le machine learning continue de mûrir et de devenir plus accessible, nous verrons des utilisations encore plus créatives et innovantes de la technologie dans l’industrie du jeu vidéo et au-delà. J’ai hâte de participer à ce voyage passionnant et de continuer à apprendre et à grandir en tant que DS/MLE.
Au-delà de cet article, j’aime discuter de données, d’IA et de conception de systèmes - comment les projets sont construits, où ils réussissent et où ils échouent. Si vous voulez échanger des idées, remettre en question des hypothèses ou parler de vos propres projets, n’hésitez pas à me contacter. Je suis toujours ouvert à une bonne conversation.
Références
- pydata — meetup.com
- mlops community — meetup.com
- Polytech Clermont Ferrand en ingénierie physique — uca.fr
- CSTB à Sophia Antipolis — cstb.fr
- CEA — ines-solaire.org
- définition de Shreya Shankar — shreya-shankar.com
- Agile — atlassian.com
- Scrum — scrum.org
- Jira — atlassian.com
- Lj Miranda — ljvmiranda921.github.io
- Mihail Eric — mihaileric.com
- mlflow — documentation
- metaflow — metaflow.org
- Arize.ai — arize.com
- AWS sagemaker — AWS
- Designing Machine Learning Systems — oreilly.com
- article — engineering.atspotify.com
- article de Chip Huyen — huyenchip.com
- EveAngeli — Wikipedia
- guide du ML en production de Google — developers.google.com
- un excellent article — eugeneyan.com
- Stefan Krawczyk a une excellente analogie — stefankrawczyk.substack.com
- article de VentureBeat — venturebeat.com
- Made with ML — madewithml.com
- Full stack deep learning — fullstackdeeplearning.com
- Udacity — udacity.com
- Kaggle — Kaggle
- Airbnb — airbnb.io
- Etsy — etsy.com
- DoorDash — doordash.engineering
- site web — eugeneyan.com
- Site Web — huyenchip.com
- cours de conception de systèmes machine learning de Stanford — stanford-cs329s.github.io
- ses articles à RecSys 2021 — GitHub
- un livre — experimentguide.com
- MLOps community — mlops.community