
Explorer la transcription de podcasts français avec OpenAI Whisper
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Au cours des derniers mois, j’ai expérimenté avec la technologie de speech-to-text, en appliquant spécifiquement Whisper d’OpenAI pour transcrire des podcasts. Cet article est une collection de ces expérimentations, visant à partager les principales découvertes et insights pratiques qui pourraient bénéficier à d’autres dans le domaine ou à ceux qui commencent juste leur parcours dans les applications speech-to-text.
![]()
Contexte
Donc, j’ai eu cette idée depuis quelques mois d’explorer la création de transcriptions de divers podcasts français que j’écoute lorsque je fais des tâches qui ne nécessitent pas trop de concentration. Cela inclut des podcasts axés sur l’écriture et l’humour comme le floodcast ou un bon moment, et ceux sur l’industrie du divertissement comme origami ou realise sans trucage
Ces podcasts sont très diversifiés en ton, humour et contenu, mais ils sont toujours une bonne source de recommandations pour divers contenus qui peuvent être intéressants à découvrir. Par exemple, j’ai récemment découvert :

- ce jeu Mosa Lina

Vous pourriez demander pourquoi je veux obtenir les transcriptions ? Pour faire des résumés ? En fait, les idées générales tournent autour de 2-3 choses (allant de correct à fou) :
- Créer une base de texte engageante (pour moi) pour entraîner mes techniques de NLP
- Exploiter le machine learning pour extraire automatiquement le contenu recommandé dans mes podcasts préférés
- Utiliser les LLM pour créer des épisodes totalement fictifs (comme certains pourraient dire, “C’est comme Black Mirror”)
Le cas d’usage le plus intéressant pour moi était définitivement le deuxième. Cela vient du fait que ce travail de stockage des recommandations peut parfois être fait par la communauté, mais à un moment donné, la source de données peut cesser d’être mise à jour. Je voulais voir si je pouvais ajouter de l’automatisation au processus qui pourrait être utile pour moi (et toute personne qui aime le contenu de ces podcasts).
Ce travail autour de la transcription était aussi assez aligné avec une nouvelle fonctionnalité récente de Spotify pour proposer un affichage synchronisé dans le temps de la transcription du podcast pendant l’écoute
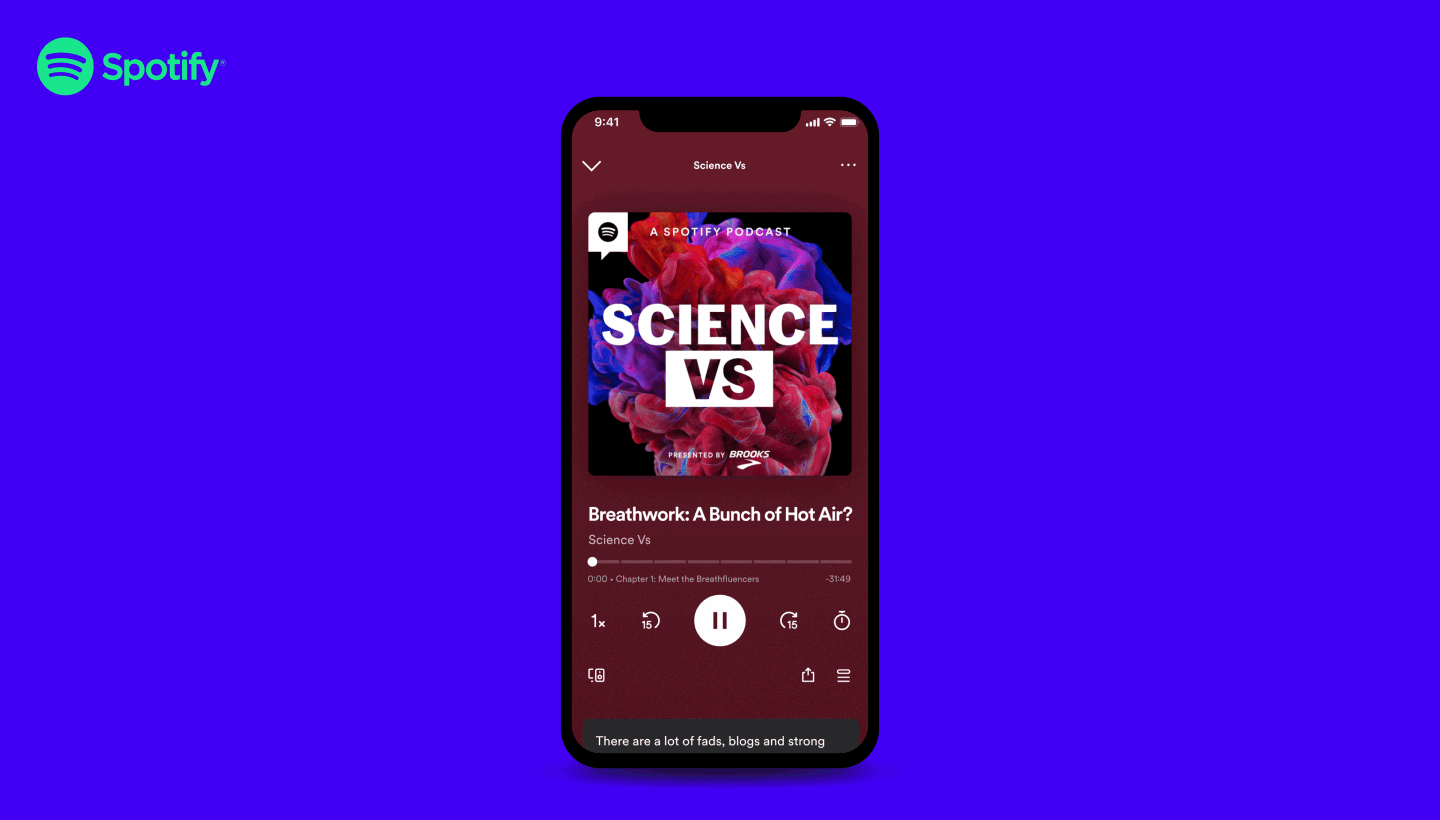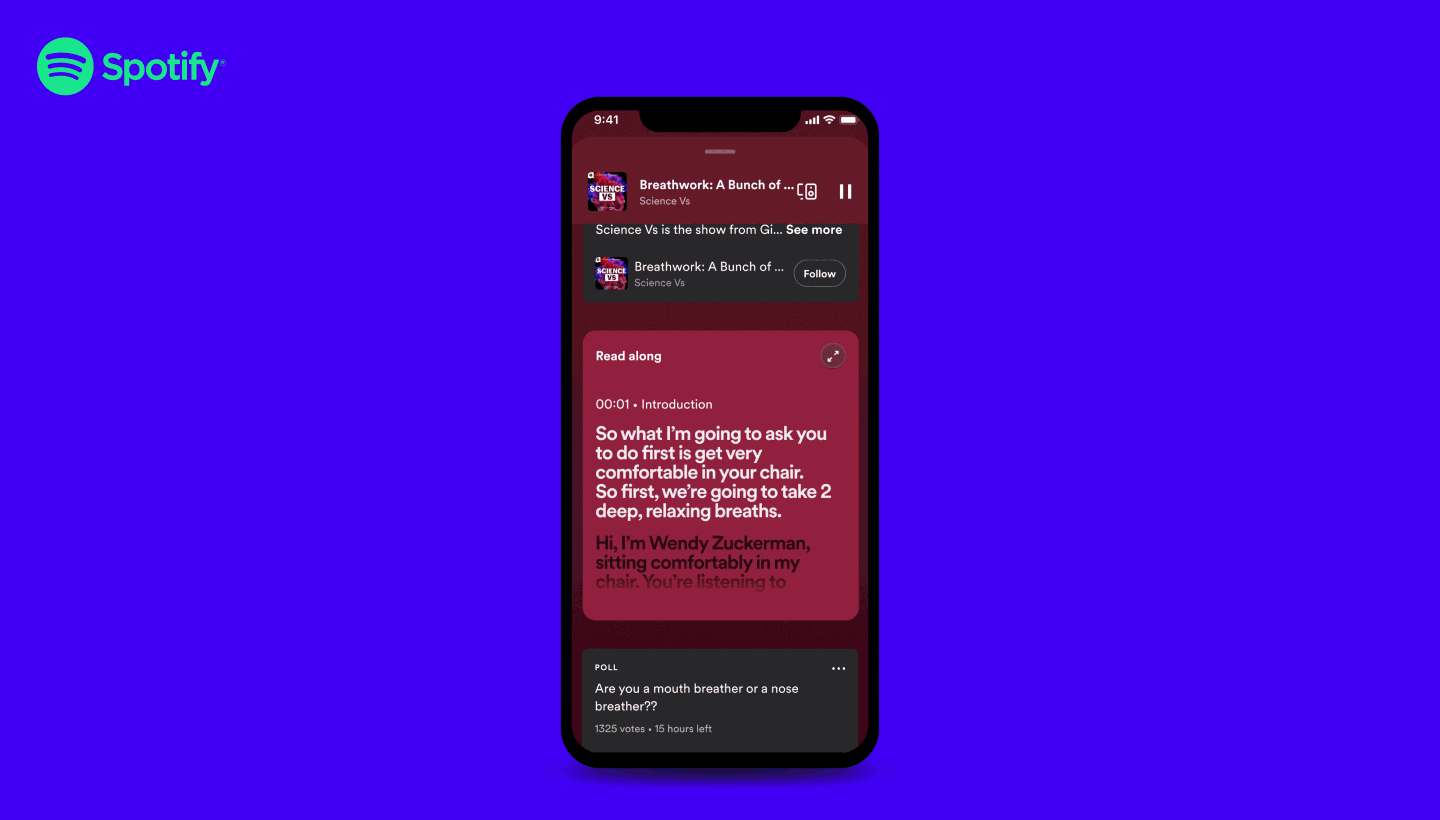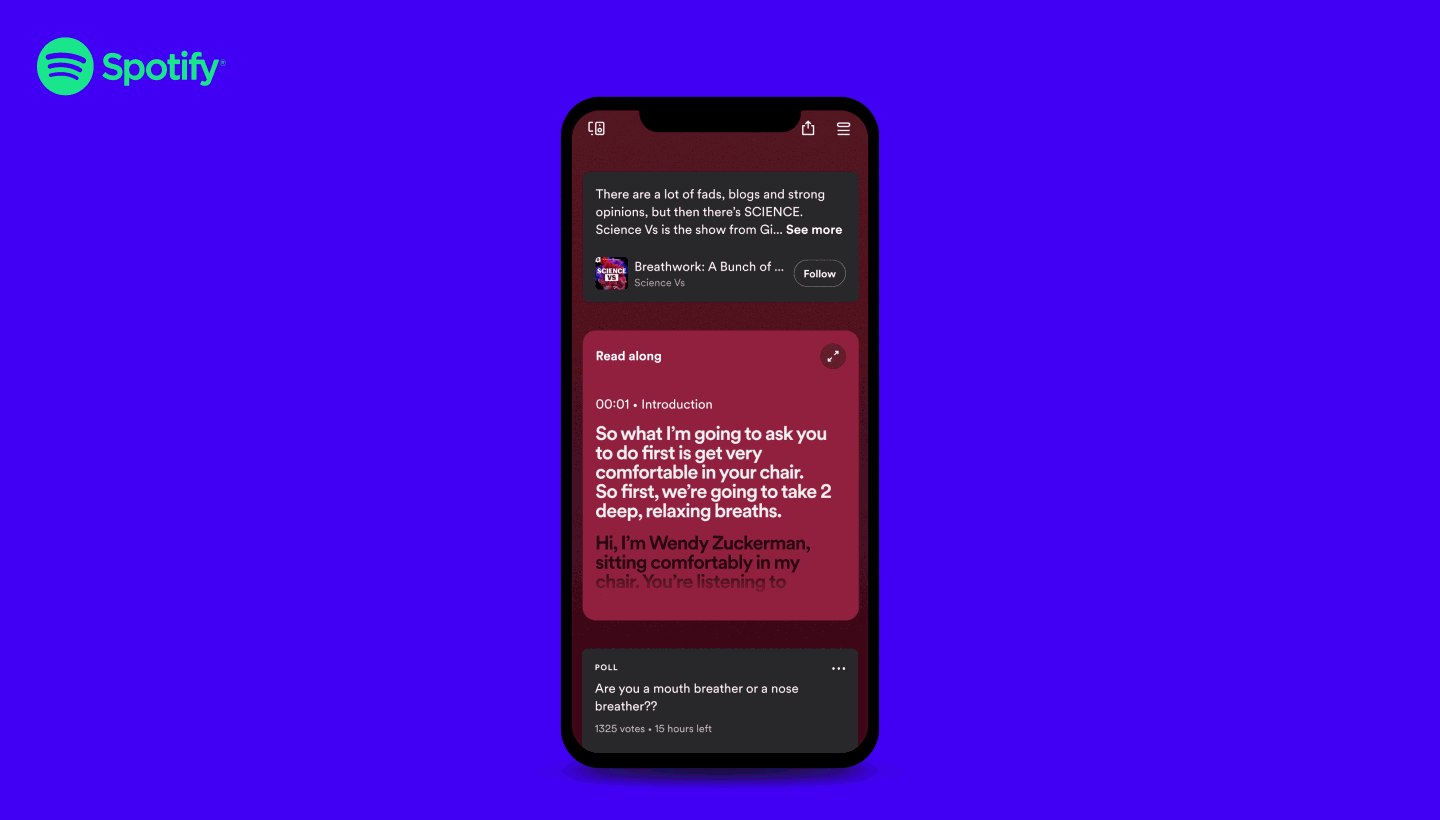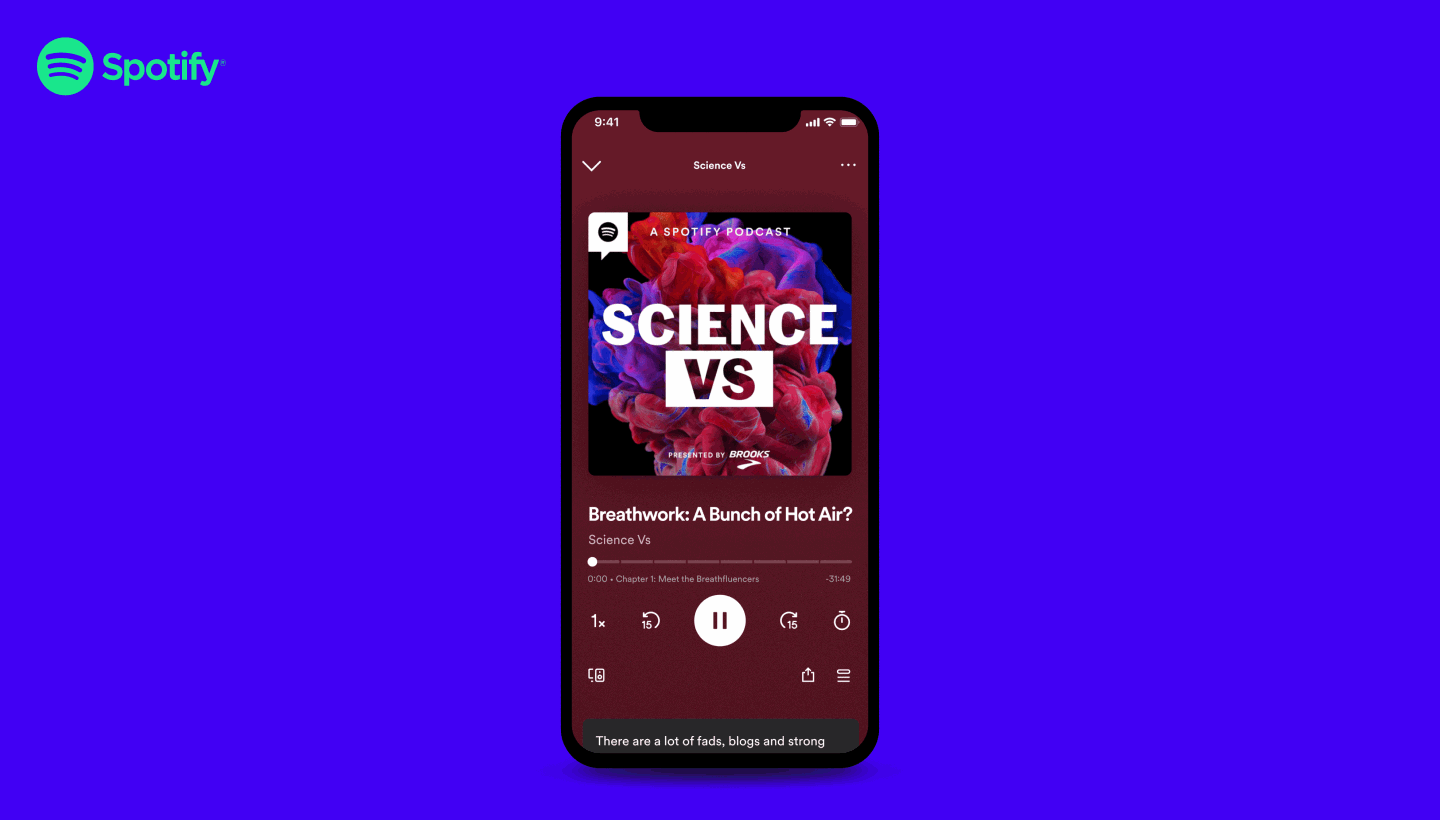
C’est une fonctionnalité plutôt cool mais pas disponible automatiquement sur tous les podcasts et vous devez toujours être dans la bonne configuration pour voir le contenu affiché.
Donc maintenant la question est, Par où commencer ? et le premier mot qui me vient à l’esprit est Whisper.
Whisper : Qu’est-ce que c’est ?
Whisper est un modèle de reconnaissance automatique de la parole (ASR) d’OpenAI. Il vise à être un outil de transcription multilingue très précis. Whisper a été entraîné en utilisant un énorme ensemble de données d’environ 680 000 heures d’audio parlé. Cet audio est multilingue et provient de diverses sources sur le web. La diversité de l’ensemble de données en langues, accents et environnements aide à rendre le système robuste et polyvalent. Il peut transcrire et traduire de nombreuses langues en anglais.
La technologie derrière Whisper implique un Transformer encodeur-décodeur. Cela fonctionne comme ceci : l’audio d’entrée est coupé en morceaux de 30 secondes, transformé en spectrogramme log-Mel, puis traité par un encodeur. Après cela, un décodeur prend le relais pour prédire la légende textuelle. Ce processus inclut des tokens spéciaux pour différentes tâches. Voici un aperçu rapide du processus :
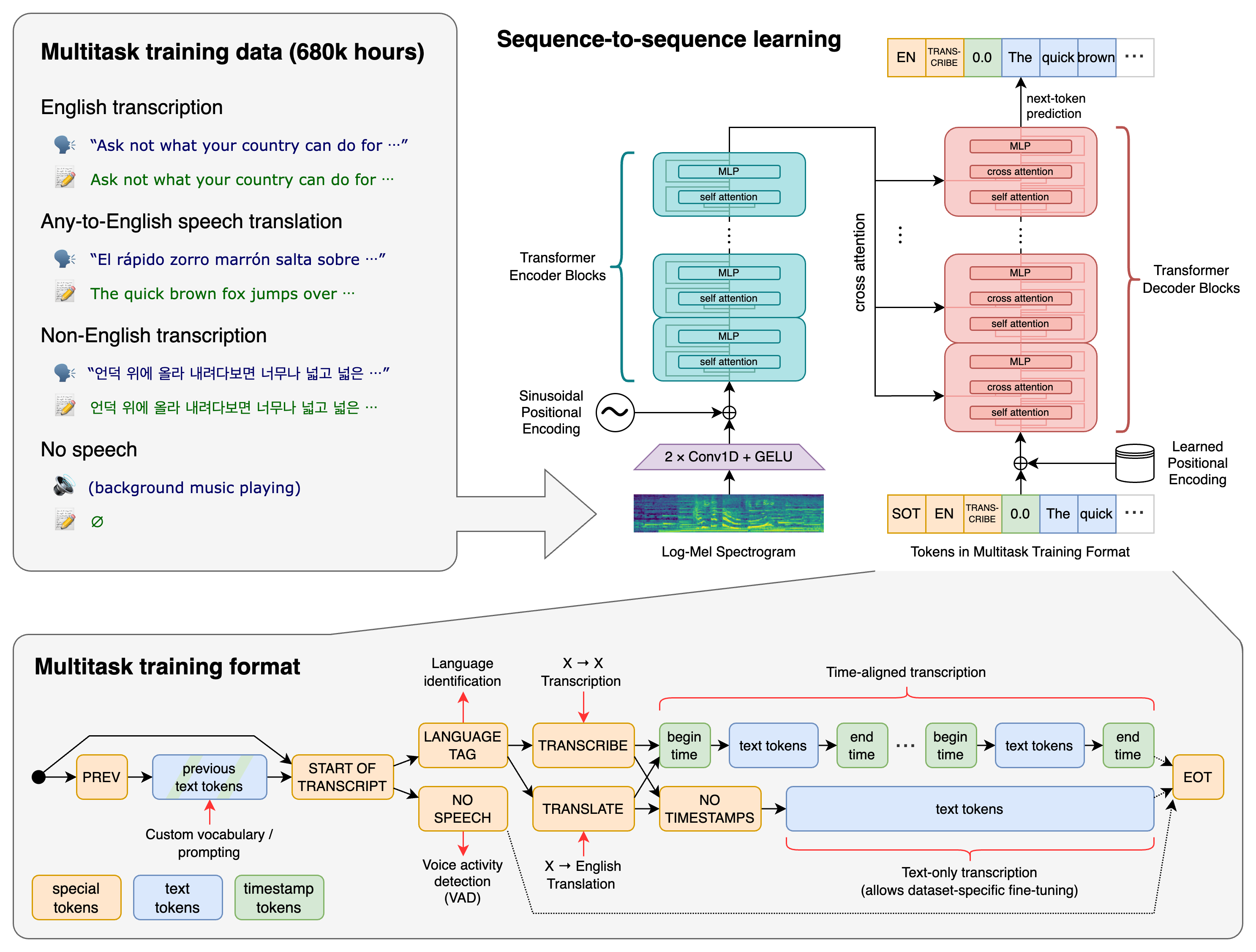
Le modèle est disponible en tailles allant de tiny à large et en différentes versions, il y a aussi un modèle dédié pour l’anglais vous pouvez trouver plus de détails sur les modèles dans la carte de modèle ICI.

La dernière est la version 3 pour la taille large. Cette version a ajouté plus de bacs de fréquence au spectrogramme et a introduit une nouvelle langue (cantonais). Plus de détails peuvent être trouvés dans cette discussion GitHub..
Whisper est assez populaire, et il existe de nombreux tutoriels montrant comment utiliser le modèle de différentes manières pour produire des transcriptions ou des traductions vers et depuis l’anglais. J’étais curieux de l’essayer moi-même, surtout dans mon contexte français mais d’abord je devais voir comment utiliser ce modèle.
Différentes saveurs de Whisper
Pour commencer mon expérience, je voulais explorer les différentes façons d’utiliser Whisper, et il y avait de nombreuses options.
Déploiement local
Les premiers choix qui me sont venus à l’esprit étaient le package Python OpenAI et l’utilisation du modèle Hugging Face. Les deux sont faciles à installer avec pip install et peuvent fonctionner sur CPU ou GPU (ce qui est recommandé pour ce type de modèle).
Avertissement : Ma configuration actuelle pour ce test est une Dell XPS 9500 series avec GeForce GTX 1650 Ti comme GPU. J’ai eu une expérience difficile pour configurer et utiliser CUDA sur cette machine pour ce test, et je prévois d’écrire un petit article sur ce sujet bientôt. :)
Donc, avec cette configuration, à quoi ressemble le code ?
Local Whisper
Globalement, le processus est très simple, sauf pour l’étape d’obtention du log_mel_spectrogram (j’ai essayé la méthode transcribe du modèle, mais elle n’a pas fonctionné) avant de faire l’inférence.
Ma configuration locale actuelle ne me permet pas d’aller au-delà de la configuration de base.
Local Hugging Face Whisper
Dans ce cas, il pourrait y avoir un peu plus de configuration nécessaire pour configurer le modèle, mais la méthode pipeline du package Transformers simplifie vraiment les expériences futures en utilisant la tâche pipeline automatic-speech-recognition pour standardiser le fonctionnement de ce type de modèle.
Ma configuration locale actuelle ne me permet pas d’aller au-delà de la configuration medium (qui est un modèle plus grand que le package officiel OpenAI).
Maintenant, passons au déploiement cloud.
Déploiement d’endpoint
Dans ce scénario, vous pouvez facilement déployer la même configuration sur une machine plus grande et accéder aux grands modèles sur de gros GPU. Cependant, je voulais explorer l’idée d’avoir un endpoint facilement accessible avec le modèle opéré sur le côté.
Le choix le plus évident pour moi était d’utiliser les endpoints de Hugging Face. Il y a deux options : le Serverless Inference Endpoint (pour le prototypage rapide) et le Dedicated Inference Endpoint (prêt pour la production).
J’ai choisi l’option dédiée parce que je voulais une solution plus robuste. Il est à noter que Hugging Face offre également des moyens de déployer des modèles via AWS SageMaker, et ils se sont récemment associés à Google Cloud.
Concernant l’endpoint d’inférence dédié, si vous êtes intéressé par comment déployer des modèles en utilisant l’endpoint de Hugging Face, la visite d’Abhishek Thakur est une excellente ressource.
Il présente la fonctionnalité en détail pour un déploiement LLM. Après avoir déployé un modèle, vous trouverez des snippets de code expliquant comment utiliser le modèle fraîchement déployé (comme montré dans la capture d’écran).
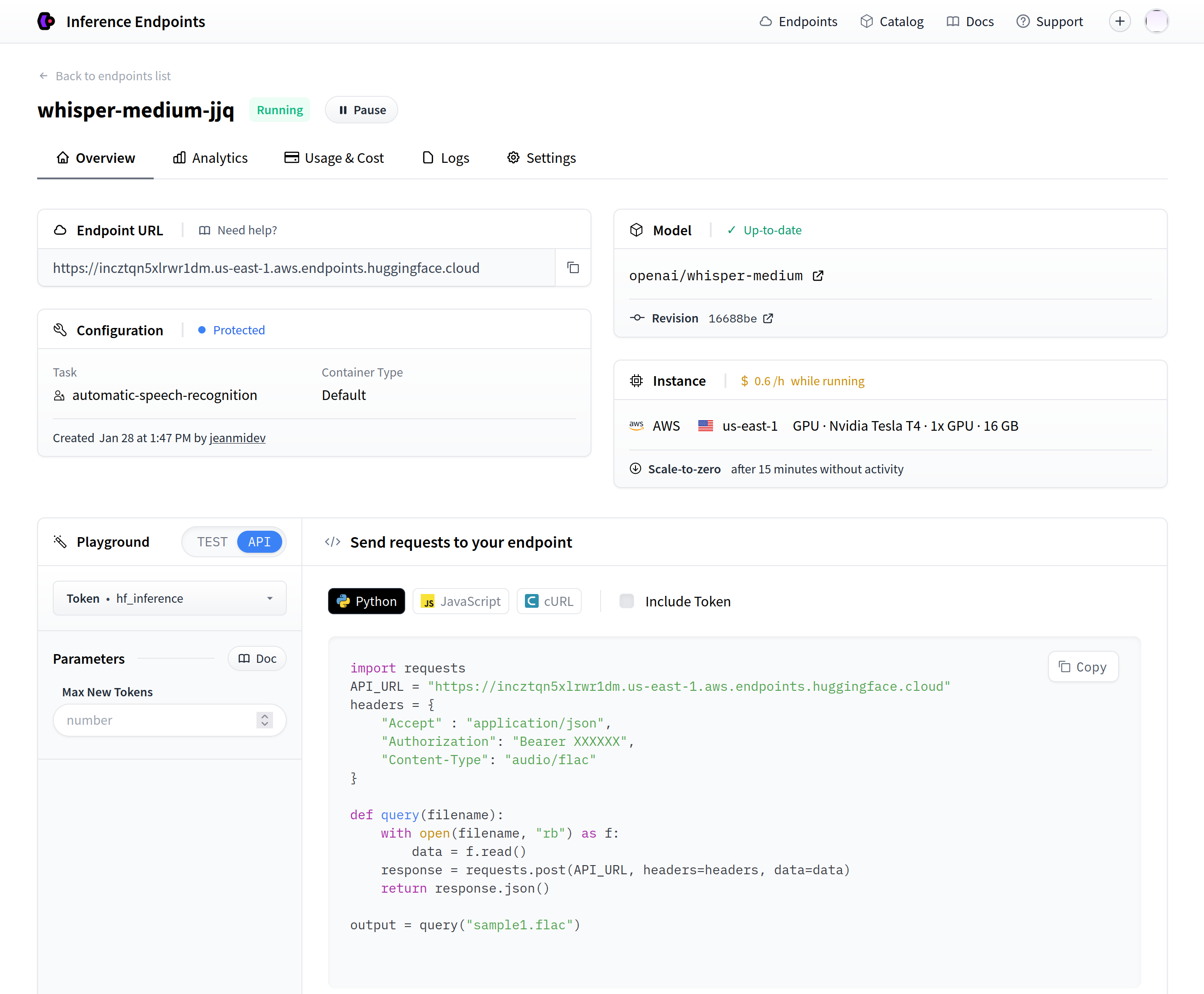
L’appel API pour atteindre l’endpoint est simple : envoyez simplement les octets du fichier audio à l’endpoint, et vous obtiendrez la transcription (dans l’exemple, c’est un fichier FLAC, mais les fichiers MP3 sont également acceptables avec l’en-tête "Content-Type": "audio/x-mpeg-3").
Notes : Je suis vraiment impressionné par l’expérience globale UI/UX pour servir des modèles avec l’endpoint Hugging Face, c’est super clair avec le bon niveau d’information pour faire des tests rapidement (pour tout passionné de MLops c’est super excitant)
Configurer le modèle est simple, mais cette méthode ne permet pas de définir la langue pendant l’inférence. Il n’y a pas de capacité à définir des kwargs généraux comme avec la configuration locale Hugging Face (à moins que j’aie manqué quelque chose), donc la transcription retournée pourrait ne pas être dans la langue attendue (elle pourrait être en anglais ou une autre langue selon la version).
Cette limitation est significative si vous cherchez une solution prête à l’emploi, mais il existe des moyens alternatifs pour la faire fonctionner. Par exemple, certains membres de Hugging Face ont affiné Whisper pour des langues spécifiques, comme bofenghuang pour le français.
Maintenant regardons l’API OpenAI.
API OpenAI
Pour interagir avec l’API OpenAI, j’utilise le wrapper Python ICI pour la transcription audio avec Whisper.
Il est important de noter que l’API actuelle :
- Est limitée au modèle whisper-1 (probablement la première version et le grand multilingue).
- Vous permet d’injecter un prompt dans la requête pour fournir un contexte pour la transcription (excellent pour continuer une transcription d’une précédente ou valider le ton).
- Inclut le concept de température (température d’échantillonnage), où plus proche de 0 sera plus déterministe et plus proche de 1 sera plus aléatoire.
- A une taille de fichier maximale de 25MB (comparé à la limite de 30 secondes dans une configuration locale, donc les fichiers plus longs sont définitivement un plus, mais je suis curieux de savoir comment ils traitent les fichiers plus volumineux).
Concluons avec quelques alternatives pour opérer les modèles Whisper.
Chemins alternatifs pour utiliser Whisper
Plus tôt, lors de la discussion sur l’endpoint cloud Hugging Face, j’ai mentionné des personnes construisant des modèles affinés et les publiant en open-source. J’aimerais mettre en évidence d’autres implémentations de Whisper.
Dans le chemin local, grâce à Wadie Benkirane de mon équipe qui suit le sujet, il y a deux packages intéressants :
- Whisper C++ : C’est une implémentation efficace des poids de Whisper derrière une API C++, idéale pour des résultats rapides. C’est particulièrement efficace pour le streaming en direct d’audio sur des appareils limités (il y a une belle démo sur un smartphone). Je l’ai essayé, et c’est génial, mais il semble que vous devez utiliser des fichiers FLAC pour les fichiers locaux.
- Faster-Whisper : Une autre implémentation C++/Python utilisant CTranslate2 qui semble être un moyen efficace d’activer l’inférence de transformers.
Pour le chemin cloud, j’ai remarqué deux services :
- Deepgram offre d’excellents services autour du traitement de la parole et de la voix (similaire à Whisper mais pas limité à cela).
- Lemonfox.ai offre la possibilité d’opérer des modèles open-source de GPT aux modèles type Whisper.
Cette liste n’est pas exhaustive, donc restez à l’écoute pour plus d’alternatives Whisper.
Maintenant il est temps d’expérimenter avec toutes ces solutions.
Expérimentations
Pour expérimenter avec les podcasts, j’ai décidé de sélectionner trois épisodes de ma collection de podcasts pour tester avec Whisper.

Mon objectif est de tester comment les différentes saveurs de Whisper peuvent fonctionner de manière évolutive, mon contexte est très en batch (offline !?) donc pas de besoins en temps réel ou de petites demandes à la demande mais plus traiter quelques heures de podcast et rétrocharger des centaines d’heures parfois.
L’expérience impliquera d’abord la construction de segments pour la transcription puis l’exploration de la génération de transcriptions pour comparer :
- le temps pour faire une inférence
- la qualité de la transcription
- le coût de l’inférence
Traiter l’audio
L’outil principal pour ce traitement audio est un package Python appelé Pydub. Le package n’a pas été mis à jour depuis un moment (le dernier commit date d’il y a deux ans), mais il est toujours largement utilisé et fonctionne bien en 2024.
Pour traiter l’audio de podcast, l’approche la plus simple pourrait être de couper le podcast en petits morceaux basés sur des timestamps. Cependant, je voulais aborder cela de manière plus méthodique. Un podcast n’est pas une chanson et a généralement des silences, donc mon processus sera de diviser le podcast en plusieurs morceaux basés sur la présence de silence.
Comment détecter le silence ? Pydub a une méthode appelée silence.detect_silence qui peut traiter l’audio Pydub et retourner des timestamps (en millisecondes) de segments sans silence. Cette fonction a trois paramètres :
min_silence_len: Longueur du silence en millisecondes, définie à 1000 ms (1 seconde).silence_thresh: La limite supérieure pour le niveau de silence en dBFS (décibels par rapport à l’échelle complète), définie à -16 dBFS (basé sur quelques lectures et tests).seek_step: Échelle d’interaction définie à 1 pas/1ms (la valeur par défaut).
Avec cette approche, nous pouvons annoter les silences dans l’audio du podcast. Sur cette base, j’ai décidé de créer des segments d’une longueur spécifique qui devraient contenir des périodes sans silence. Voici ma fonction pour construire les timecodes liés à un épisode de podcast basé sur le silence détecté.
J’ai appliqué ce traitement audio pour créer différentes versions des timecodes basées sur la longueur souhaitée des segments (avec des segments de 6, 15, 30 secondes et 1, 2, et 5 minutes).
Passons maintenant à Whisper pour l’évaluation de la transcription.
Benchmark
Dans mon expérience, j’ai utilisé des segments de 21 à 27 secondes pour m’aligner avec le papier original de Whisper (entraîné sur des morceaux de 30 secondes). L’évaluation s’est concentrée sur le temps pour générer une transcription et la qualité des prédictions. Cinq segments de chaque fichier ont été sélectionnés pour cette évaluation, et chaque opération a été exécutée 10 fois pour une évaluation fiable de la durée et de la qualité de la transcription. Les résultats, y compris les transcriptions et les fichiers audio, peuvent être trouvés ICI.
Mon benchmark a testé les saveurs Whisper suivantes :
- Tiny, base, et small local Whisper du package Python d’OpenAI sur ma machine locale
- Tiny, base, small, et medium local Whisper des poids Hugging Face OpenAI sur ma machine locale
- Medium Whisper affiné pour le français (modèle bofenghuan), déployé sur un endpoint dédié sur Hugging Face
- Medium, largeV2 et largeV3 Whisper des poids Hugging Face OpenAI, déployés sur un endpoint dédié sur Hugging Face
- API Whisper OpenAI
Donc il y a une comparaison globale de la durée pour les différentes saveurs pour faire les inférences
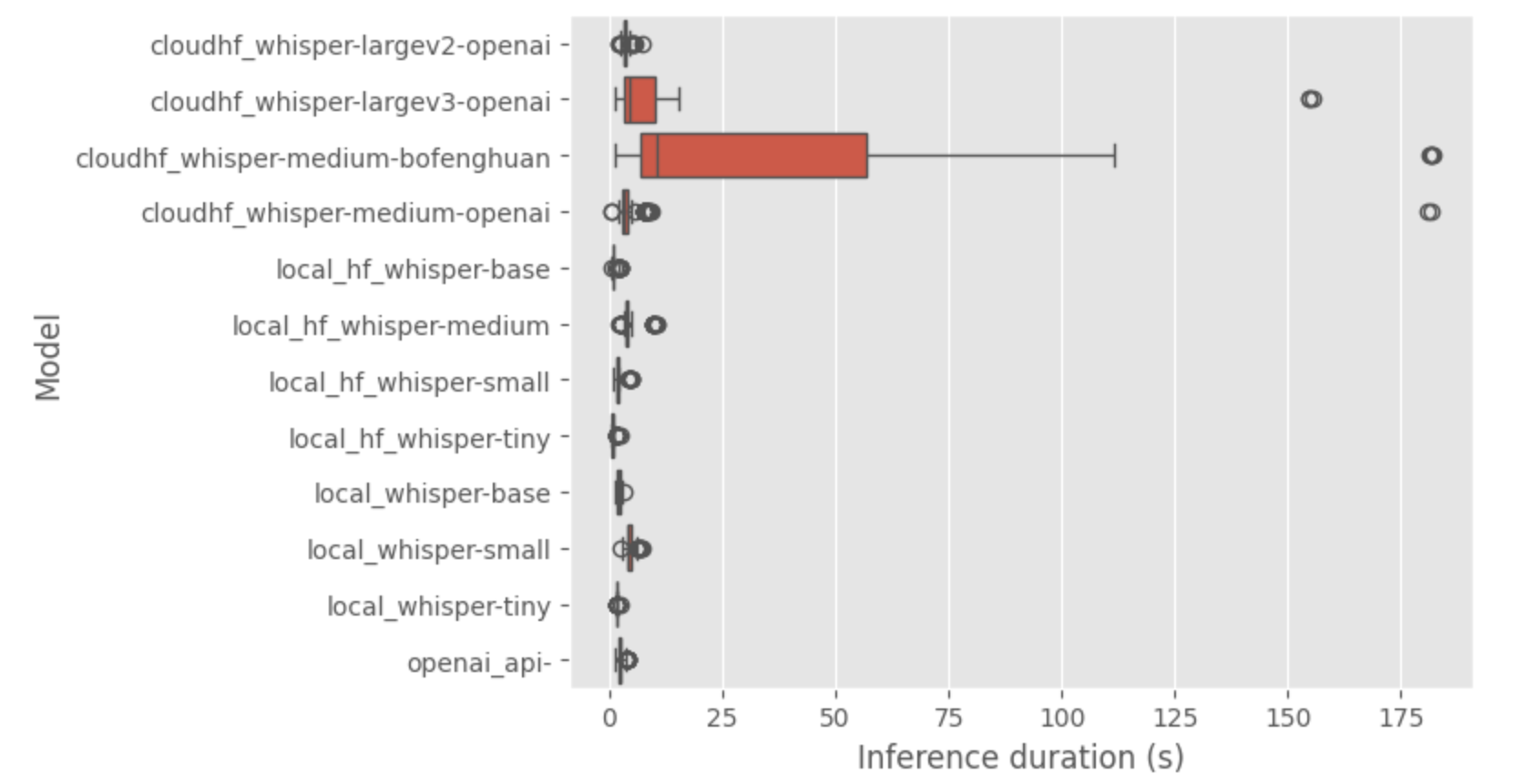
Les observations les plus évidentes sont :
- le modèle whisper medium fine tune a une inférence très longue en général
- medium et large-v3 d’openAI ont un temps d’inférence moyen correct mais il y a quelques outliers (venant uniquement de l’endpoint de Hugging face bizarrement avec des erreurs). En regardant les transcriptions de ces saveurs, j’ai remarqué des transcriptions vides, donc définitivement ces endpoints ne répondent parfois pas, et cela explique les outliers.
Je vais mettre un petit drapeau rouge sur les endpoints dédiés car ils ne semblent pas bien gérer le traitement par batch comme je le fais pour ce benchmark, je suppose que vous devrez ajuster l’endpoint (et le prix) pour mieux s’adapter à un scénario de production.
Zoomons sur les modèles les plus rapides (sans fliers pour les endpoints HF).
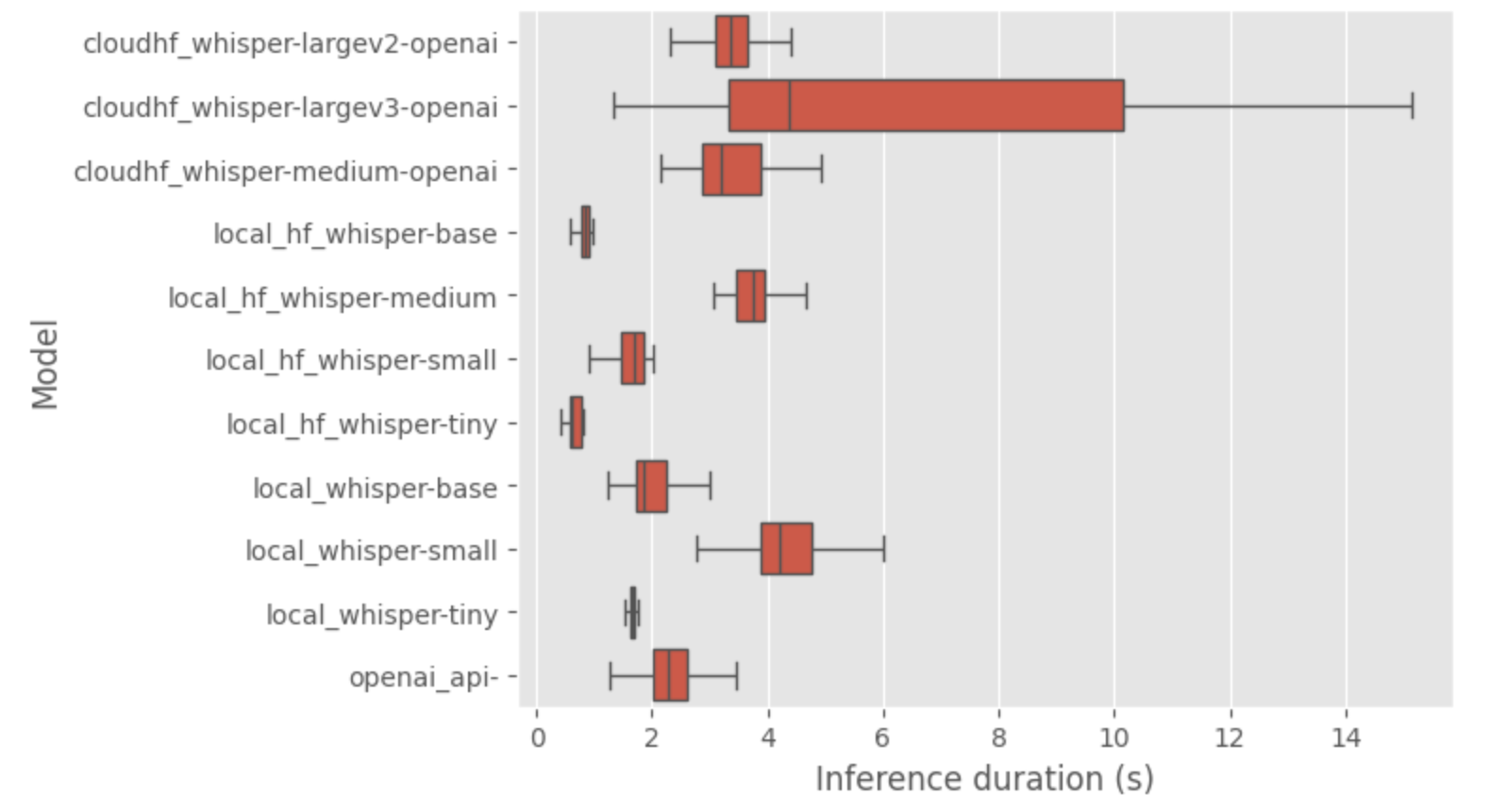
Donc à partir de cette analyse des temps d’inférence et de la qualité des transcriptions, j’ai remarqué :
- Les grands modèles OpenAI ont montré de bons temps d’inférence.
- La qualité des transcriptions s’est améliorée avec des modèles plus grands ; la taille medium est un bon début pour le déploiement local.
- Le temps d’inférence de l’implémentation native whisper locale est plus élevé que sur celle de Hugging Face (je pense que ma méthode d’inférence est erronée)
- Des répétitions dans les transcriptions ont été notées (sur les transcriptions de petits et grands modèles), s’alignant avec les limitations connues du modèle.
Donc c’était mon benchmark de l’évaluation des segments, encore une fois si vous êtes curieux sur les données et transcriptions il y a tout ICI donc vous pouvez vous faire votre propre opinion sur les données produites.
Évaluons maintenant le coût de calcul.
Évaluation du coût de calcul
L’objectif est de faire une estimation de la bonne stack pour opérer whisper et faire la production de transcription. Donc voici mes options actuelles pour l’évaluation :
- API OpenAI : Pas de stack supplémentaire requise, coûte 0.006 $ par minute de transcription.
- Endpoint dédié Hugging Face : Nvidia Tesla T4 (1 GPU avec 16GB VRAM), coûte 0.6 $ par heure de fonctionnement ou (0.0002$ par seconde de fonctionnement).
- Instance AWS EC2 : Nvidia Tesla T4, coûte 0.53 c$ par heure de fonctionnement ou (0.00015$ par seconde de fonctionnement).
- Configuration locale (en se concentrant sur la carte graphique) :
- NVIDIA GeForce RTX 4070 SUPER (12GB RAM) = $600.
- NVIDIA GeForce RTX 4080 (16GB RAM) = $1200.
Donc voici une estimation du coût par heure d’audio transcrite dans le cas où nous analysons l’audio en une séquence de 30 secondes à la fois.
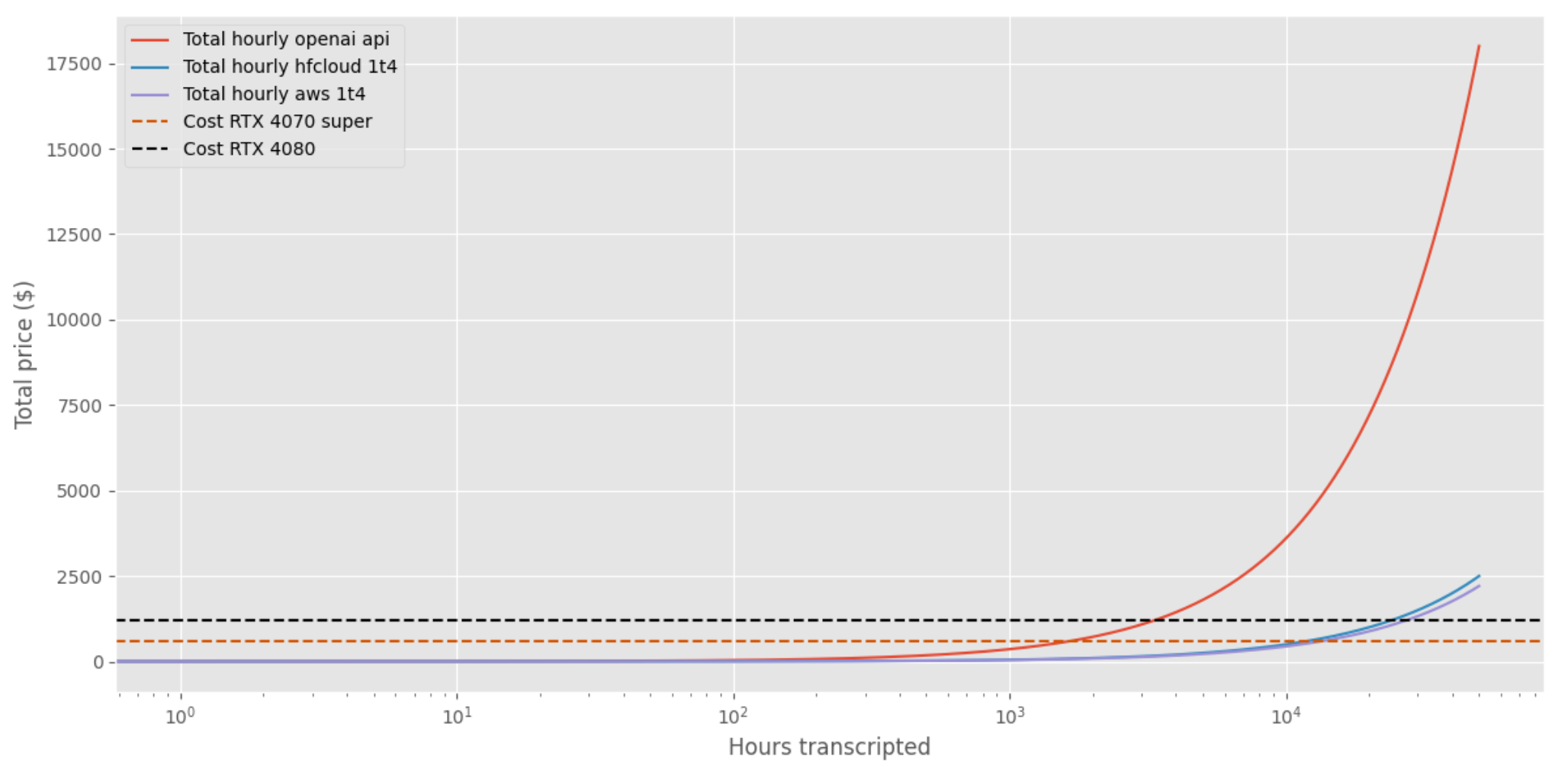
Globalement, je note que :
- Configuration locale avec RTX : Pour justifier l’investissement par rapport à l’utilisation de l’API OpenAI ou d’une configuration cloud, il faudrait transcrire des milliers d’heures. Ainsi, passer à une RTX pourrait ne pas être rentable pour mon usage.
- Configuration cloud T4 : Semble plus rentable que l’API OpenAI. Avec un temps attendu de 7 secondes pour transcrire 1 minute d’audio, le coût est d’environ 0.001$ par minute transcrite – 6 fois moins cher que l’API OpenAI.
Il semble que la meilleure affaire soit de déployer un modèle sur une machine GPU dans le cloud et que l’API openAI soit peut-être une victoire rapide mais coûteuse.
Je voulais conclure cette section par un test final pour l’API openAI pour tester si les temps d’inférence étaient les mêmes pour toute taille d’audio à transcrire (parce que peut-être c’est une fonctionnalité)
Voici un benchmark de l’api avec diverses durées d’audio (répété 10 fois pour chaque durée)
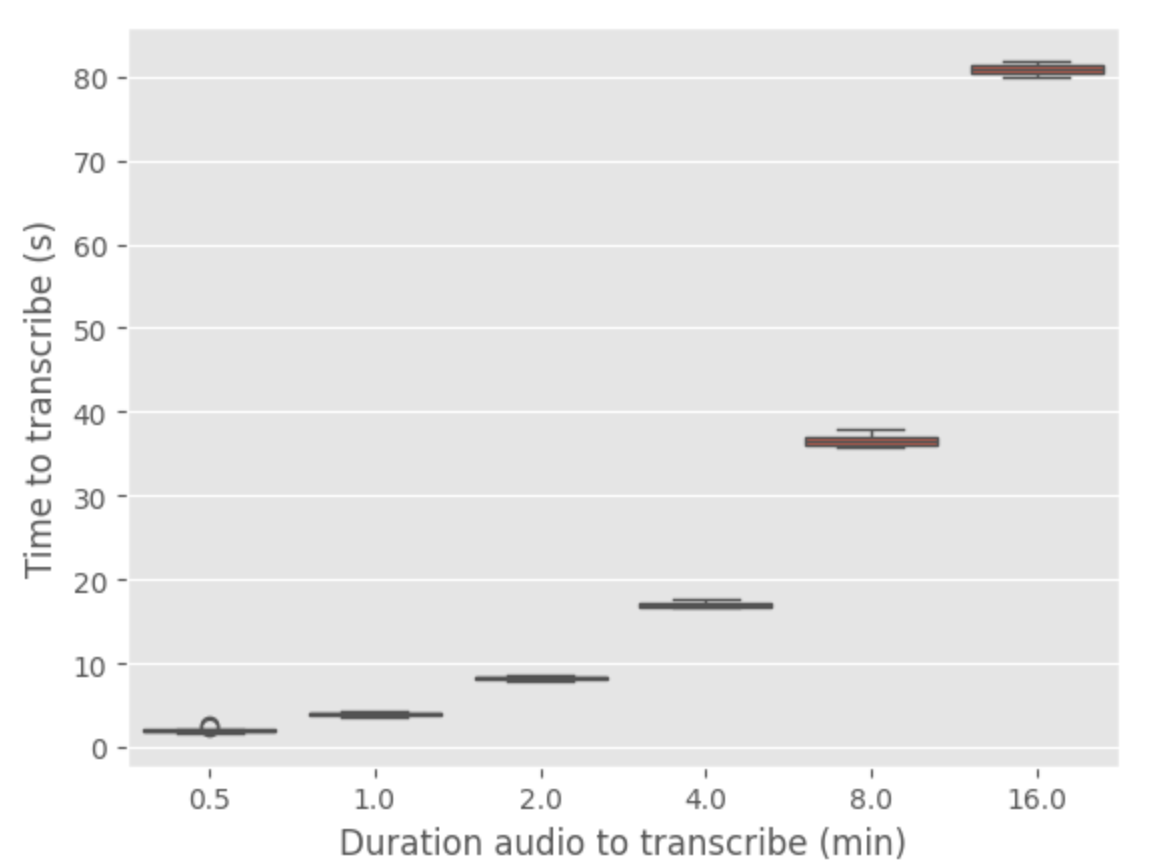
Il semble qu’il y ait une relation linéaire entre la durée de l’audio et le temps de transcription. Le temps de transcription est approximativement 5 fois la durée de l’audio à transcrire. Donc l’API n’offre pas d’accélération de l’analyse d’un fichier audio (et il est toujours inconnu comment ils traitent le fichier audio d’entrée)
Vous pouvez trouver les fichiers et résultats utilisés dans ce test ICI.
Conclusion
Le choix entre configuration locale, déploiement cloud, ou utilisation de l’API OpenAI dépend fortement du volume de transcription nécessaire et des contraintes budgétaires. Pour la transcription à haut volume, une configuration locale avec un GPU puissant comme le RTX 4070 ou 4080 pourrait éventuellement devenir plus rentable (mais pas pour moi)
Cependant, pour des besoins modérés ou faibles en volume, les solutions cloud (pour héberger une machine GPU) sont les plus rentables et plus pratiques et budgétaires. L’API OpenAI est excellente pour le prototypage mais à long terme peut devenir coûteuse.
Notes de conclusion et directions futures
Ce projet me donne d’excellents insights sur le déploiement de modèles et le benchmarking dans un domaine qui ne m’est pas familier avec un modèle intéressant d’openAI.
La sortie de mon benchmark a illustré que déployer votre propre modèle sur du matériel dans le cloud est l’option la plus rentable, mais l’API OpenAI est bonne pour faire des prototypes et de petites démos.
En regardant vers l’avenir, il y a plusieurs directions intéressantes que j’explorerai dans le futur :
1. Traitement audio amélioré :
- Séparation des locuteurs : Développer ou utiliser une méthode pour isoler et se concentrer sur les voix individuelles dans un podcast. Cela pourrait améliorer la clarté et la pertinence des transcriptions.
- Approche streaming : Considérer le traitement de l’audio comme un flux continu plutôt que de le diviser en segments, simplifiant potentiellement le processus et le rendant plus dynamique.
- Qualité audio supérieure : Enquêter sur la faisabilité d’utiliser des fichiers FLAC au lieu de MP3 pour une meilleure qualité audio, bien que cela puisse avoir des contraintes techniques.
- Alternatives de bibliothèque audio : Explorer d’autres bibliothèques de traitement audio comme Librosa, qui pourraient offrir plus de fonctionnalités et une meilleure maintenance par rapport à Pydub.
2. Développement de modèle focalisé :
- Construction d’un ensemble de données annoté : Collecter manuellement des recommandations d’épisodes de podcast pour créer un ensemble de données qui relie les épisodes ou segments spécifiques à des sujets ou thèmes.
- Modèle adapté pour la langue française : Étant donné les capacités multilingues de Whisper, mais le français est loin d’être le meilleur modèle (cf repository), affiner ou utiliser un modèle spécifiquement adapté à la langue française pourrait améliorer significativement la précision dans ce contexte.
- Explorer les alternatives à Whisper : Enquêter sur d’autres modèles de speech-to-text comme Wav2vec 2.0 pour comparer les performances et l’adéquation aux besoins du projet.
- LLM pour l’analyse de transcription : Utiliser de grands modèles de langage (LLM) pour analyser et post-traiter les transcriptions. La documentation de l’API OpenAI, par exemple, démontre comment améliorer la fiabilité avec GPT-4. Cette approche pourrait être particulièrement utile pour combler les lacunes entre les segments ou ajouter du contexte aux transcriptions (et il y a aussi l’option prompt à explorer dans le wrapper api openaI)
Ces étapes futures semblent intéressantes et j’espère avoir le temps de creuser plus sur ce sujet, restez à l’écoute 🔉👂.
Au-delà de cet article, j’aime discuter de données, d’IA et de conception de systèmes—comment les projets sont construits, où ils réussissent et où ils échouent. Si vous voulez échanger des idées, remettre en question des hypothèses ou parler de vos propres projets, n’hésitez pas à me contacter. Je suis toujours ouvert pour une bonne conversation.
Références
- Whisper — openai.com
- ICI — GitHub
- Plus de détails peuvent être trouvés dans cette discussion GitHub. — GitHub
- package Python OpenAI — GitHub
- l’utilisation du modèle Hugging Face — Hugging Face
- nouvelle fonctionnalité récente de Spotify — newsroom.spotify.com
- package Transformers — Hugging Face
- Serverless Inference Endpoint — Hugging Face
- Dedicated Inference Endpoint — Hugging Face
- AWS SageMaker — AWS
- Google Cloud — cloud.google.com
- bofenghuang — Hugging Face
- API OpenAI — openai.com
- ICI — GitHub
- la transcription audio avec Whisper — platform.openai.com
- Whisper C++ — GitHub
- Faster-Whisper — GitHub
- CTranslate2 — GitHub
- Deepgram — deepgram.com
- Lemonfox.ai — lemonfox.ai
- Pydub — GitHub
- silence.detect_silence — GitHub
- ICI — Kaggle
- limitations connues du modèle — GitHub
- modèle bofenghuan — Hugging Face
- ICI — Kaggle
- Librosa — GitHub
- repository — GitHub
- Wav2vec 2.0 — ai.meta.com
- améliorer la fiabilité avec GPT-4 — platform.openai.com